cloud computing Recently Published Documents
Total documents.
- Latest Documents
- Most Cited Documents
- Contributed Authors
- Related Sources
- Related Keywords

Simulation and performance assessment of a modified throttled load balancing algorithm in cloud computing environment
<span lang="EN-US">Load balancing is crucial to ensure scalability, reliability, minimize response time, and processing time and maximize resource utilization in cloud computing. However, the load fluctuation accompanied with the distribution of a huge number of requests among a set of virtual machines (VMs) is challenging and needs effective and practical load balancers. In this work, a two listed throttled load balancer (TLT-LB) algorithm is proposed and further simulated using the CloudAnalyst simulator. The TLT-LB algorithm is based on the modification of the conventional TLB algorithm to improve the distribution of the tasks between different VMs. The performance of the TLT-LB algorithm compared to the TLB, round robin (RR), and active monitoring load balancer (AMLB) algorithms has been evaluated using two different configurations. Interestingly, the TLT-LB significantly balances the load between the VMs by reducing the loading gap between the heaviest loaded and the lightest loaded VMs to be 6.45% compared to 68.55% for the TLB and AMLB algorithms. Furthermore, the TLT-LB algorithm considerably reduces the average response time and processing time compared to the TLB, RR, and AMLB algorithms.</span>
An improved forensic-by-design framework for cloud computing with systems engineering standard compliance
Reliability of trust management systems in cloud computing.
Cloud computing is an innovation that conveys administrations like programming, stage, and framework over the web. This computing structure is wide spread and dynamic, which chips away at the compensation per-utilize model and supports virtualization. Distributed computing is expanding quickly among purchasers and has many organizations that offer types of assistance through the web. It gives an adaptable and on-request administration yet at the same time has different security dangers. Its dynamic nature makes it tweaked according to client and supplier’s necessities, subsequently making it an outstanding benefit of distributed computing. However, then again, this additionally makes trust issues and or issues like security, protection, personality, and legitimacy. In this way, the huge test in the cloud climate is selecting a perfect organization. For this, the trust component assumes a critical part, in view of the assessment of QoS and Feedback rating. Nonetheless, different difficulties are as yet present in the trust the board framework for observing and assessing the QoS. This paper talks about the current obstructions present in the trust framework. The objective of this paper is to audit the available trust models. The issues like insufficient trust between the supplier and client have made issues in information sharing likewise tended to here. Besides, it lays the limits and their enhancements to help specialists who mean to investigate this point.
Cloud Computing Adoption in the Construction Industry of Singapore: Drivers, Challenges, and Strategies
An extensive review of web-based multi granularity service composition.
The paper reviews the efforts to compose SOAP, non-SOAP and non-web services. Traditionally efforts were made for composite SOAP services, however, these efforts did not include the RESTful and non-web services. A SOAP service uses structured exchange methodology for dealing with web services while a non-SOAP follows different approach. The research paper reviews the invoking and composing a combination of SOAP, non-SOAP, and non-web services into a composite process to execute complex tasks on various devices. It also shows the systematic integration of the SOAP, non-SOAP and non-web services describing the composition of heterogeneous services than the ones conventionally used from the perspective of resource consumption. The paper further compares and reviews different layout model for the discovery of services, selection of services and composition of services in Cloud computing. Recent research trends in service composition are identified and then research about microservices are evaluated and shown in the form of table and graphs.
Integrated Blockchain and Cloud Computing Systems: A Systematic Survey, Solutions, and Challenges
Cloud computing is a network model of on-demand access for sharing configurable computing resource pools. Compared with conventional service architectures, cloud computing introduces new security challenges in secure service management and control, privacy protection, data integrity protection in distributed databases, data backup, and synchronization. Blockchain can be leveraged to address these challenges, partly due to the underlying characteristics such as transparency, traceability, decentralization, security, immutability, and automation. We present a comprehensive survey of how blockchain is applied to provide security services in the cloud computing model and we analyze the research trends of blockchain-related techniques in current cloud computing models. During the reviewing, we also briefly investigate how cloud computing can affect blockchain, especially about the performance improvements that cloud computing can provide for the blockchain. Our contributions include the following: (i) summarizing the possible architectures and models of the integration of blockchain and cloud computing and the roles of cloud computing in blockchain; (ii) classifying and discussing recent, relevant works based on different blockchain-based security services in the cloud computing model; (iii) simply investigating what improvements cloud computing can provide for the blockchain; (iv) introducing the current development status of the industry/major cloud providers in the direction of combining cloud and blockchain; (v) analyzing the main barriers and challenges of integrated blockchain and cloud computing systems; and (vi) providing recommendations for future research and improvement on the integration of blockchain and cloud systems.
Cloud Computing and Undergraduate Researches in Universities in Enugu State: Implication for Skills Demand
Cloud building block chip for creating fpga and asic clouds.
Hardware-accelerated cloud computing systems based on FPGA chips (FPGA cloud) or ASIC chips (ASIC cloud) have emerged as a new technology trend for power-efficient acceleration of various software applications. However, the operating systems and hypervisors currently used in cloud computing will lead to power, performance, and scalability problems in an exascale cloud computing environment. Consequently, the present study proposes a parallel hardware hypervisor system that is implemented entirely in special-purpose hardware, and that virtualizes application-specific multi-chip supercomputers, to enable virtual supercomputers to share available FPGA and ASIC resources in a cloud system. In addition to the virtualization of multi-chip supercomputers, the system’s other unique features include simultaneous migration of multiple communicating hardware tasks, and on-demand increase or decrease of hardware resources allocated to a virtual supercomputer. Partitioning the flat hardware design of the proposed hypervisor system into multiple partitions and applying the chip unioning technique to its partitions, the present study introduces a cloud building block chip that can be used to create FPGA or ASIC clouds as well. Single-chip and multi-chip verification studies have been done to verify the functional correctness of the hypervisor system, which consumes only a fraction of (10%) hardware resources.
Study On Social Network Recommendation Service Method Based On Mobile Cloud Computing
Cloud-based network virtualization in iot with openstack.
In Cloud computing deployments, specifically in the Infrastructure-as-a-Service (IaaS) model, networking is one of the core enabling facilities provided for the users. The IaaS approach ensures significant flexibility and manageability, since the networking resources and topologies are entirely under users’ control. In this context, considerable efforts have been devoted to promoting the Cloud paradigm as a suitable solution for managing IoT environments. Deep and genuine integration between the two ecosystems, Cloud and IoT, may only be attainable at the IaaS level. In light of extending the IoT domain capabilities’ with Cloud-based mechanisms akin to the IaaS Cloud model, network virtualization is a fundamental enabler of infrastructure-oriented IoT deployments. Indeed, an IoT deployment without networking resilience and adaptability makes it unsuitable to meet user-level demands and services’ requirements. Such a limitation makes the IoT-based services adopted in very specific and statically defined scenarios, thus leading to limited plurality and diversity of use cases. This article presents a Cloud-based approach for network virtualization in an IoT context using the de-facto standard IaaS middleware, OpenStack, and its networking subsystem, Neutron. OpenStack is being extended to enable the instantiation of virtual/overlay networks between Cloud-based instances (e.g., virtual machines, containers, and bare metal servers) and/or geographically distributed IoT nodes deployed at the network edge.
Export Citation Format
Share document.
- Open access
- Published: 06 July 2018
Reliability and high availability in cloud computing environments: a reference roadmap
- Mohammad Reza Mesbahi 1 ,
- Amir Masoud Rahmani ORCID: orcid.org/0000-0001-8641-6119 1 , 2 &
- Mehdi Hosseinzadeh 3
Human-centric Computing and Information Sciences volume 8 , Article number: 20 ( 2018 ) Cite this article
61k Accesses
64 Citations
3 Altmetric
Metrics details
Reliability and high availability have always been a major concern in distributed systems. Providing highly available and reliable services in cloud computing is essential for maintaining customer confidence and satisfaction and preventing revenue losses. Although various solutions have been proposed for cloud availability and reliability, but there are no comprehensive studies that completely cover all different aspects in the problem. This paper presented a ‘Reference Roadmap’ of reliability and high availability in cloud computing environments. A big picture was proposed which was divided into four steps specifying through four pivotal questions starting with ‘Where?’, ‘Which?’, ‘When?’ and ‘How?’ keywords. The desirable result of having a highly available and reliable cloud system could be gained by answering these questions. Each step of this reference roadmap proposed a specific concern of a special portion of the issue. Two main research gaps were proposed by this reference roadmap.
Introduction
It was not so long ago that applications were entirely developed by organizations for their own use, possibly exploiting components/platforms developed by third parties. However, with service-oriented architecture (SOA), we moved into a new world which applications could delegate some of their functionalities to already existing services developed by third parties [ 1 ].
For meeting ever-changing business requirements, organizations have to invest more in time and budget for scaling up IT infrastructures. However, achieving this aim by own premises and investments not only is not cost-effective but also organizations will not be able to have an optimal resource utilization [ 2 ]. Therefore, these challenges have forced companies to seek some new alternative technology solutions. One of these modern technologies is cloud computing, which focuses on increasing computing power to execute millions of instructions per seconds.
Nowadays, cloud computing and its services are at the top of the list of buzzwords in the IT world. It is a recent trend in IT that can be considered as a paradigm shift for providing IT & computing resources through the network. One of the best and most popular definitions of cloud computing is the NIST definition proposed in 2009 and updated in 2011. According to this definition, “Cloud computing is a model for enabling ubiquitous, convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction” [ 3 ].
Recent advances in cloud computing are pushing virtualization more than ever. In other words, cloud computing services can be considered as a significant step towards realizing the utility computing concept [ 4 ]. In such a computing model, services can be accessed by users regardless of where they are hosted or how they are delivered.
Over the years, computing trends such as cluster computing, grid computing, service-oriented computing and virtualization have gained maturity but cloud computing is still in infancy, and experiences lack of complete standards and solutions [ 5 ]. Therefore, the following critical issues are introduced by cloud business models and technologies including load balancing [ 6 , 7 ], security [ 8 , 9 ], energy-efficiency [ 10 , 11 , 12 ], workflow scheduling [ 13 , 14 , 15 , 16 , 17 ], data/service availability, license management, data lock-in and API design [ 1 , 2 , 5 , 18 , 19 , 20 ].
High Availability (HA) and reliability in cloud computing services are some of the hot challenges. The probability that a system is operational in a time interval without any failures is represented as the system reliability, whereas the availability of a system at time ‘t’ is referred to as the probability that the system is up and functional correctly at that instance in time [ 21 , 22 ]. HA for cloud services is essential for maintaining customer’s confidence and preventing revenue losses due to service level agreement (SLA) violation penalties [ 23 , 24 ]. In recent years, cloud computing environments have received significant attention from global business and government agencies for supporting critical mission systems [ 25 ]. However, the lack of reliability and high availability of cloud services is quickly becoming a major issue [ 25 , 26 ]. Research reports express that about $285 million have been lost yearly due to cloud service failures and offering availability of about 99.91% [ 26 ].
Cloud computing service outage can seriously impact workloads of enterprise systems and consumer data and applications. Amazon’s EC2 outage on April, 2011 is an example of one of the largest cloud disasters. Several days of Amazon cloud services unavailability resulted in data loss of several high profile sites and serious business issues for hundreds of IT managers [ 27 ]. Furthermore, according to the CRN reports [ 28 ], the 10 biggest cloud service failure of 2017, including IBM’s cloud infrastructure failure on January 26, GitLab’s popular online code repository service outage on January 31, Facebook on February 24, Amazon Web Services on February 28, Microsoft Azure on March 16, Microsoft Office 365 on March 21 and etc., caused production data loss, and prevented customers from accessing their accounts, services, projects and critical data for very long and painful hours. In addition, credibility of cloud providers took a hit in these service failures and unavailability.
Although many research papers and studies have been conducted in recent years such as studies in [ 26 , 29 , 30 , 31 , 32 , 33 , 34 ], but each of these previous works focused on a special aspect of HA in cloud computing and there are no comprehensive studies, which cover all aspects of HA problem in cloud computing environment based on all cloud actors’ requirements. In this paper, a comprehensive study results about cloud computing reliability and HA problems as a ‘Reference Roadmap’ for future researchers will be proposed.
This research aims to offer a comprehensive strategy for providing high availability and reliability while guaranteeing less performance degradation in cloud computing datacenters. Therefore, by satisfying the users’ requirements and providing services according to the SLA and preventing SLA violation penalties, providers can make a huge profit [ 35 ]. To achieve this goal, all possible aspects to this issue will be studied by proposing a big picture of the problem (for clarifying the possible future approaches). In this research, the proposed research gaps will be puzzled out by completing the pieces of our big picture through answering four questions starting with ‘Where?’, ‘Which?’, ‘When?’ and ‘How?’ question words. In the rest of this paper, a proposed reference roadmap will be introduced and its different aspects will be described. Then the possible primary solutions for these proposed questions will be introduced. The main contributions of this study can be considered as follows:
A reference road map for cloud high availability and reliability is proposed.
A big picture is proposed through dividing the problem space into four major parts.
A comprehensive cloud task taxonomy and failure classification are presented.
Research gaps which were neglected in the literature review are identified.
The rest of this paper is as follows. The research background and literature review is presented in “ Research background ”. The proposed reference roadmap in terms of research “Big Picture” is presented in “ Proposed reference roadmap ”. Discussion and open issues section is presented in “ Discussion and open issues ”. The paper is concluded in “ Conclusion ”.
Research background
Cloud computing provides the context of offering virtualized computing resources and services in a shared and scalable environment through the network on a pay-as-you-go model. By rapid adoption of cloud computing, a large proportion of worldwide IT companies and government organizations have adopted cloud services for various purposes including hosting the mission-critical applications and thus critical data [ 34 ]. In order to support these mission-critical applications and data, there is need to provide dependable cloud computing environments.
In order to study dependability of cloud computing, the major cloud computing system (CCS) dependability attributes should be identified which can quantify the dependability of cloud in different aspects. Some important attributes for dependable cloud environments have been mentioned in [ 36 ] and include availability, reliability, performability, security, and recoverability.
Five major actors and related roles in cloud environments are described in the NIST Cloud Computing Standards Roadmap document [ 37 ]. These five participating actors are cloud provider, cloud consumer, cloud broker, cloud carrier and cloud auditor [ 37 ]. Table 1 presents the definitions of these actors. Consumers and Providers are two main roles among these actors which are significantly considerable in the most cloud computing scenarios. Therefore, this research paper focuses on these two actors.
Pan and Hu [ 36 ] proposed a summary of the relative strengths of dependency on different dependability attributes for each class of actors shown in Table 1 . This empirical analysis shows that there are three ‘Availability’, ‘Reliability’, and ‘Performability’ critical requirements for cloud consumers and providers. Thus, on one hand, from the consumers’ viewpoint, there is a great requirement for highly available and reliable cloud services, but on the other hand, while cloud providers understand the necessity for providing highly available and reliable services for meeting quality of services (QoS) due to the SLA, they also prefer to have highly utilized systems to achieve more profits [ 35 ]. Under these considerations, providing dependable cloud environments which can meet the desires of both cloud consumers and providers is a new challenge.
There are many different design principles such as ‘Eliminating Single Point of Failure’ [ 27 , 38 ], ‘Disaster Recovery’ [ 39 , 40 ] and ‘Real-Time and Fast Failure Detection’ [ 41 , 42 , 43 ] that can help achieve high availability and reliability in cloud computing environments. The single point of failure (SPOF) in cloud computing datacenters can occur in both software and hardware level. Single point of failure can be interpreted as a probable risk which can cause the entire system failure. Applying redundancy is an important factor for avoiding SPOFs [ 27 ]. In simple words, every vital component should exist in more than one instance. At the occurrence of a disaster at a main component in a cloud datacenter, system operations can be switched to backup services and efficient techniques are required for data backup and recovery [ 40 ]. The time taken to detect a failure is one of the key factors in the cloud computing environments. So, fast and real-time failure detection to identify or predict a failure in the early stages is one of the most important principles to achieving high availability and reliability in cloud systems [ 42 , 43 ]. Moreover, there are some new trends in cloud computing such as SDN-based technology like Espresso that makes cloud infrastructures more reliable and available in the network level [ 44 ].
A systematic review of high availability in cloud computing was undertaken by Endo et al. [ 45 ]. This study aimed to discuss high availability mechanisms and important related research questions in cloud computing systems. From the results, the three most useful HA solutions are ‘Failure Detection’, ‘Replication’, and ‘Monitoring’. In addition, the review results show that ‘Experiment’ approach is used more than other approaches for evaluating the HA solutions. However, the paper proposed some research questions and tried to answer these questions, but the study results are more similar to the study mapping review. Furthermore, it did not consider the different cloud actors’ requirements in terms of high availability.
Liu et al. [ 46 ] applied an analytical modeling and sensitivity analysis for investigating the effective factors on cloud infrastructure availability such as repair policy and system parameters. In this study, the replication method was used to provide physical machine availability. Two different repair policies were considered in this study, and a Stochastic Reward Nets availability model was developed for each policy. The numerical results of this study showed that both policies provide the same level of availability but with the different cost level. The system availability was assessed through modeling without considering the failure types in this paper. In addition, the limited number of hot pares and repair policies cannot be sufficient to evaluate the large-scale cloud environments.
The availability and performance of storage services in private cloud environments were evaluated in [ 47 ]. In this study, a hierarchical model was applied for evaluation which consists of Markov chain, stochastic Petri Nets and reliability block diagrams. The result of this study showed that the adoption of redundancy could reduce the probability that timeouts occurred and users were attended to due to failures.
An et al. [ 32 ] presented a system architecture and framework of fault tolerance middleware to provide high availability in cloud computing infrastructures. This middleware uses the virtual machine replicas according to a user defined algorithm for replication. Proposing an optimal replica placement in cloud infrastructure is an important issue in this study. So, authors developed an algorithm for online VM replica placement.
Snyder et al. [ 48 ] presented an algorithm for evaluating the reliability and performance of cloud computing datacenters. In this study, a non-sequential Monte Carlo simulation was used to analyze the system reliability. This paper demonstrated that using this approach can be more efficient and flexible for cloud reliability evaluation when there is a set of discrete resources.
A cloud scoring system was developed in [ 49 ] that can integrate with a Stochastic Petri Net model. In this study, while an analytical model was used for evaluating the application deployment availability, the scoring system can suggest the optimal HA-aware option according to the energy efficiency and operational expenditure. The proposed model in this study can consider different types of failures, repair policies, redundancy, and interdependencies of application’s components. One of the main contributions of this study is proposing an extensible integrated scoring system for offering the suitable deployment based on the users’ requirements.
A comparative evaluation of two redundancy and proactive fault tolerance techniques was proposed in [ 50 ], based on the cloud providers’ and consumers’ requirements. This evaluation was proposed in terms of cloud environment’s availability based on the consumers’ viewpoint and cost of energy from the providers’ viewpoint. The result of this study showed that the proactive fault tolerance methods can be better than traditional redundancy technique in terms of cloud consumers’ costs and execution success rate.
A framework for amending GreenCloud simulator was proposed in [ 51 ] to support the high availability features in simulation processes. In this study, the necessity of a simulator that can provide the HA features was addressed. Then, the phased communication application (PCA) scenario was implemented to evaluate the HA features, workload modeling and scheduling.
Table 2 presents a comparative analysis of some availability and reliability solutions. The comparative factors in this table are main idea, advantages, challenges and evaluation metrics.
The lack of evaluating solutions to quantitatively assess the availability of provided cloud services is one of the main issues and gaps. In addition, according to the literature review, it seems that VM performance overhead [ 52 ] can affect the system availability. Furthermore, the high availability common techniques such as VM migration can also affect the VM performance overhead. So, considering the mutual impact of VM performance overhead and high availability solutions in cloud environments is another important research gap in the current CCS study area.
Proposed reference roadmap
This section presents the proposed reference roadmap in terms of the big picture shown in Fig. 1 . The goal of this section is to cover all different aspects of the reliability and availability issues in cloud computing research area. So, the area in the big picture is divided into four major steps. Figure 1 illustrates the general scheme of the proposed big picture of our reference roadmap. This big picture represents all aspects and factors of high availability and reliability issues in cloud computing environments. In this big picture, a eucalyptus-based architecture illustrates the major and key components of a cloud computing environment. By determining cloud key components in this architecture we will be able to identify the most important factors that can affect system high availability and reliability. The main components include VM, node controller, cluster controller, storage controller, cloud controller and Walrus [ 23 ]. Four major steps to achieve a high available and reliable cloud system are posed in terms of four pivotal questions. In addition, other related issues such as cloud computing nodes’ performance have been considered in this big picture.

Proposed big picture of high availability and reliability issue in cloud computing environments
By proposing this big picture we aim to have a comprehensive look at the problem area and have a reference roadmap for taking each step to solve the problem in cloud computing environments. It is believed that by taking these four steps in terms of answering the four questions, a high available and reliable cloud computing system will be obtained and while satisfying the cloud consumers’ requirements, the providers’ concerns could also be considered.
In the rest of this section, the different parts of our proposed big picture will be explained in details. Each question will be discussed and current available approaches and solutions for each part will be proposed. In future works, we aim to study each part in more details as another independent research and use this big picture as a reference roadmap as mentioned earlier.
“ Where are the vital parts for providing HA in the body of cloud computing datacenters? ”
There are many different geographically distributed cloud clusters in a cloud environment. Cloud computing datacenters comprise of a different stack of components such as physical servers with heterogeneous hardware characteristics like different processor speed, disk and memory size [ 53 ]. In addition, based on the property of workload heterogeneity and dynamicity, datacenters run a vast number of applications with diverse characteristics. Particularly, an application can be divided into one or more processes running on dedicated virtual machines (VM) and the resource requirement differs from VM to VM [ 53 ]. Therefore, by posing the where question at the first step, we are trying to find out where the vital parts are with high priority and basic requirement for high availability. Figure 2 illustrates the proposed roadmap of the “Where” step. The following possible approaches are available for offering primary solutions for the where question.

Proposed roadmap of the “Where” step
• SLA-based approach
A service level agreement is simply defined as a part of a standardized service contract where a service is formally defined. It is an agreement about the quality of a provided service. The agreement describes terms regarding service usage rate and delivery which are agreed between the service providers and the consumers. SLAs contain the following parts [ 54 ]:
The agreement context. Signatory parties, generally the consumer and the provider, and possibly third parties entrusted to enforce the agreement, an expiration date, and any other relevant information.
A description of the offered services including both functional and non-functional aspects such as QoS.
Obligations agreement of each party, which is mainly domain-specific.
Policies: penalties incurred if a SLA term is not respected and SLA violation occurs.
Service level agreements can also be discussed at these three different levels:
Customer - based SLA It is a type of agreement with a single customer that covers all the necessary services. This is similar to the SLA between an IT service provider and the IT department of an organization for all required IT services.
Service - based SLA It is defined as a general agreement for all customers who are using the delivered services by the service provider.
Multi - level SLA This kind of agreement can be split into different levels, with each level addressing a different set of customers for the same services.
By using this approach, we can focus on the SLA in the ‘Multi-level SLA’ to find the clusters which are offering services to the users whose basic requirement and first priority to run their tasks are highly available in the entire cloud system. Then by determining these clusters it can be said that the vital parts of the system are known and if high availability can be provided for these clusters, it can be said that while providing a high available system, more benefits are gained by preventing SLA violation penalties.
• Using 80/20 Rule
Pareto principle or 80/20 rule is a useful rule in computer science world [ 55 , 56 , 57 ]. In simple words, it says that in anything, a few (about 20%) are vital and many (about 80%) are trivial. In the subject of cost in cloud computing environments, 80/20 rule can be used which says that 80% of the outcomes will come from 20% of your effort [ 58 ]. In addition, the 80/20 rule is leveraged in our previous study to provide a highly reliable architecture in cloud environments [ 57 ]. According to our research results, there are a reliable sub-cluster and a highly reliable zone in cloud computing datacenters which can be used to serve the most profitable request. This rule can be applied from two different perspectives:
80% of cloud service providers’ profits may come from 20% of customers.
80% of requested services consist of just 20% of the entire cloud providers’ services.
So in this step, we can limit the domain of providing high availability in cloud computing clusters in our study based on this assumption that the majority of cloud providers’ profits will be earned by offering 20% of the entire services to 20% of whole customers. Therefore, if the high availability in the clusters which belong to that 20% of customers can be guaranteed, then it can be claimed that cloud providers will make the maximum profits while offering a system with high availability.
• Task-based approach
Providing high availability for different requests and incoming workloads according to the requested task classification and through various suitable mechanisms for each task’s class is another approach for this step. So, if the cloud computing tasks can be classified according to their resource requirements (CPU, Memory, etc.), then cloud services and tasks high availability can be provided by hosting tasks in the suitable clusters to avoid task failure due to the resource limitation. For instance, a memory-intensive task will be forwarded into a cluster with sufficient memory resources. Therefore, tasks can be completed without any execution interruption related to the lack of memory errors.
There are many different types of application software and tasks that can be executed in a distributed environment such as high-performance computing (HPC) and high-throughput computing (HTC) applications [ 59 ]. It is required to provide a massively parallel infrastructure for running High-performance computing applications using multi-threaded and multi-process program models. Tightly coupled parallel jobs within a single machine can be executed efficiently using HPC applications. This kind of applications commonly uses message passing interface (MPI) to achieve the needed inter-process communication. On the other hand, distributed computing environments have had awesome achievements to execute loosely coupled applications using workflow systems. The loosely coupled applications may involve numerous tasks that can be separately scheduled on different heterogeneous resources to achieve the goals of the main application. Tasks could be large or small, compute-intensive or data-intensive and may be uniprocessor or multiprocessor. Moreover, these tasks may be loosely-coupled or tightly-coupled, heterogeneous or homogeneous and can have a static or dynamic nature. The aggregate number of tasks, the quantity of required computing resources and volumes of required data for processing could be small but also extremely large [ 59 ].
As mentioned earlier, the appearance of cloud computing guarantees providing highly available and efficient services to run applications like web applications, social networks, messaging apps etc. Providing this guarantee needs a scalable infrastructure including many computing clusters which are shared by various tasks with different requirements and quality of service in terms of availability, reliability, latency and throughput [ 60 ]. Therefore, to provide required service level (e.g. highly available services), a good understanding of task resource consumption (e.g. memory usage, CPU cycles, and storages) is essential.
As cloud computing has been in its infancy during the last years, the applications that will run on clouds are not well defined [ 59 ]. The Li and Qiu [ 61 ], expressed that the required amount of cloud infrastructure resources for current and future tasks can be predicted according to the major trends of the last decade of the large-scale and grid computing environments. First, singular jobs are mainly split into two data-intensive and compute-intensive tasks categories. It can be said that there are no tightly coupled parallel jobs. Second, the duration of individual tasks is dimensioning with every year; few tasks are still running for longer than 1 h and majority require only a few minute to complete. Third, compute-intensive jobs will be divided into Dag-based workflow and bags-of-tasks (BoTs). But data-intensive jobs may utilize several and different programming models.
A task classification has been done in [ 60 ] based on the tasks’ resource consumption running in the Google Cloud Backend. The results of this study are presented in Table 3 . Cloud computing tasks are classified based on their execution duration, number of required CPU cores and amount of required memory in this study. The essential amount of resources for each class of cloud tasks is represented with three major ‘Small’, ‘Med (Medium)’, and ‘Large’ factors, which are abbreviated as ‘s’, ‘m’ and ‘l’, respectively in the ‘Final Class’ column of Table 3 . Three words in this column represent the duration, cores and memory, correspondingly. In addition, ‘*’ means that all three factors are possible in this type of class. For instance, the Final Class ‘sm*’ refers to a class of tasks having an execution duration as ‘small’ (short-running tasks), the number of required CPU cores are ‘Med’ and they would consume ‘small’, ‘Med’ or ‘large’ amount of memory.
In addition, Foster et al. [ 59 ] characterize the clouds’ application to be loosely coupled, transaction oriented (small tasks in the order of milliseconds to seconds) and likely to be interactive (as opposed to batch-scheduled).
The proposed taxonomy of cloud computing tasks is presented in Fig. 3 . According to our studies, cloud tasks can be classified into two long-running and short-running tasks in terms of tasks’ duration. Therefore based on Table 3 , it can be said that task durations are bimodal, either somewhat less than 30 min or larger than 18 h [ 60 ]. Such behavior results from the characteristics and types of application tasks running on cloud infrastructures. There are two types of long-running tasks. The first are interactive or user-facing tasks which run continuously so as to respond quickly to a user request. The second type of long-running tasks is compute-intensive, such as processing web logs [ 60 ]. Interactive tasks consume a large amount of CPU and memory during periods of a high user request rate. It means that they are CPU-intensive and memory-intensive. In addition since they handle end-user interactions, they are likely latency-sensitive. There are several types of short-running tasks. These tasks dominate the task population. Some short duration tasks are highly parallel operations such as index lookups and searches [ 60 ]. We can also mention HPC tasks. Some tasks can be considered as short memory-intensive tasks which include memory intensive operations like map reduce workers that compute an inverted index. These types of tasks are specified as class 2 in Table 3 . Other tasks which include CPU-intensive operations are considered as short CPU-intensive tasks like map reduce workers which compute aggregation of a log. Finally, it can be said that typical data-intensive workloads consist of short-running, data-parallel tasks. For data-intensive applications, data should be moved across the network, which represents a potential bottleneck [ 62 ].

Cloud tasks taxonomy
According to the proposed cloud tasks taxonomy and previous discussion we can have more understanding of cloud tasks’ requirements and suggest the best approach for providing HA based on the tasks’ types. As the conclusion of this section, it can be said that interactive tasks require more HA from the customer perspectives. Because they are interacting with end users and consuming a large amount of CPU and memory during periods of high user request rate, then by detecting and providing more CPU and Memory resources for these group of tasks, their availability can be improved. In addition, as they are latency sensitive, then providing these resources should be done during a specific threshold. Likewise, for other types of tasks, related requirement and resources for being highly available can be provided.
“Which components play key roles to affect cloud computing HA and reliability?”
As mentioned earlier we identified main constituent components of a cloud computing architecture which are inspired by the Eucalyptus architecture. By answering to “Which” question, we are trying to know the system’s weak points of HA and reliability in this step as illustrated in Fig. 4 . After knowing these weak points, we will be able to think about how we can improve them and find suitable solutions in the next steps. Therefore, to catch this goal all cloud failures and their causes should be classified first. Next, all important reliability and HA measuring tools and metrics to evaluate the importance degree of each cloud components in the proposed architecture will be specified. Some main failure modes of CCSs have been proposed in [ 36 , 63 , 64 ] but as one of the future works of this research, different viewpoints exist for proposing a comprehensive classification of cloud failures. Table 4 presents a summary of these studies. Six main failure modes include software failures, hardware failures, cloud management system failures, security failures, environment failures and human faults.

Proposed roadmap of the “Which” step
One of the important aspects of software failures is database failure and data resource missing [ 36 ]. Therefore one of the HA and reliability issues in cloud computing systems will be based on the user requests to unavailable or removed data resources. For providing HA and reliability for data related services we can use 80/20 rule based on the fact that most of the data requests only access a small part of the data [ 55 ]. So, concentrating on hotspot data which are normally less than 20% of the whole data resource in terms of 80/20 rule for improving system’s availability and reliability could be one of the future approaches of this research.
Hardware failure is another important failure mode in cloud computing datacenters. In [ 65 ], hardware failures of multiple datacenters have been examined for determining explicit failure rates for different components including disks, CPUs, memory, and RAID controllers. One of the most important results of this study is that disk failure is the major source of failures in such datacenters [ 65 ]. Therefore, cloud storage devices or storage controllers as pointed in the proposed architecture can be one of the main components that can affect system reliability. Based on the conclusion of [ 65 ], we propose the hypothesis that failures of components follow the Pareto principle in cloud computing datacenters. This hypothesis can be studied as another future work of this paper. Therefore it can be said that about 80% of cloud system failures are related to storage failures.
Some researches conducted about the networks of CCS show that most of the datacenter networks and switches are highly reliable and only load balancers most often experience faults due to software failures [ 26 , 70 ].
Cloud management system (CMS) is the last important failure classification of Table 4 which will be considered in this section. Cloud management system can be considered as the manager of cloud computing services. A cloud management system uses the combination of software and technologies for handling the cloud environments. In other words, CMS can be considered as a response to the management challenges of cloud computing. At least, a CMS should be able to:
Manage a pool of heterogeneous resources.
Provide remote access for end users.
Monitor system security.
Manage resource allocation policies.
Manage tracking of resource usage.
As aforementioned in [ 71 ], three different types of failures have already been identified for CMSs and include: (1) technological failures that result from hardware problems, (2) hardware limitations creating management errors as a result of limited capability and capacity for processing information and (3) middleware limitations for exchanging information between systems as a result of various technologies using different information and data models. Currently, CMSs can detect the failures and follow the pre-defined procedures to re-establish the communications infrastructure [ 71 ]. However, the most important type of failure is related to content and semantic issues. These failures will occur when management systems operate with incorrect information, when data is changed erroneously after a translation or conversion process, or when data is misinterpreted. So, this kind of problem is still largely unsolved and is a serious problem.
One of the fundamental reasons behind avoiding the adoption and utilization of cloud services is the issue of security. Security is often considered as the main requirement for hosting critical applications in public clouds. Security failure which is one of the most important modes of cloud computing failures can be divided into three general modes which include: customer faults, software security breaches and security policy failure.
According to the Gartner predictions for IT world and users for 2016 and beyond, through 2020, 95% of cloud computing security failures will occur because of customers’ faults [ 68 ]. So, it can be said that customers’ faults will be the most important reason of cloud security failures. In addition, cloud-based software security breach is another serious issue. When cloud services are unavailable because of cloud system failures, this can cause huge problems for users who depend on their daily cloud-based activities, loss of revenue, clients and reputation for businesses. The reported software security breaches in recent years such as Adobe’s security breaches, resulted in service unavailability and cloud system failures [ 69 ].
Design and human-made interaction faults currently dominate as one of the numerous sources of failures in cloud computing environments [ 67 ]. In other words, an external fault can be considered as an improper interaction with system during the operational time by an operator. But because environmental failures and human operational faults are considered as external faults from the system viewpoint, they are beyond the scope of this paper. Based on the previous discussion it can be concluded that hardware component failures and database failures are two most important hotspots for more future studies in this step. Likewise, the most impressive factors among all cloud components can be specified as a new failure classification in future work of this research step. In addition, some reliability and availability measuring tools that would enable us to identify the most effective components in the cloud systems’ availability and reliability will be used. So the second part of this step for answering “which?” question involves identifying and classifying these measures. In the rest of this section, some of these measures will be introduced.
• Recurring faults
As earlier discussed, another goal of this part is to classify all-important reliability and HA evaluation measures. The study in [ 72 ] proposes this point that when a PC component fails, it is much more likely to fail again. This is called recurring faults which can be helpful after identifying faulty components in this step.
•Reliability importance (RI)
Identifying the weaknesses of a complex system is not as easy as identifying these weak components in a simple system such as series systems. In the complex systems, the analyst requires a mathematical approach that will provide the means of identifying the importance of each system component. Reliability Importance (RI) is a suitable measure to identify the relative importance of each component according to the total reliability of the system. The reliability importance, IR i , of component i in a system of n components is given as [ 73 ]:
where R s ( t ): is the system reliability at a certain time, t; R i ( t ): is the component reliability at a certain time, t.
The RI measures the rate of change at the certain time t of the system reliability regarding the components reliability change. The probability that a component can cause system failure at time t, can also be measured by the RI. Both reliability and current position of a system component can affect the calculated reliability importance in Eq. 1 .
So, in this step, the most important components which can have a high impact on cloud computing reliability will be identified. Therefore this step focuses on reliability issues as the first concern.
“When reliability and HA will decrease in cloud computing environments?”
Concentration will be on evaluating the different system states by answering the “When” question from the HA and reliability points of view to identify the causes and times of availability and reliability degradation at this step. Figure 5 shows the proposed roadmap of this step.

Proposed roadmap of the “When” step
Availability and reliability models capture failure and repair behavior of systems and their components. Model-based evaluation methods can be one of the discrete-event simulation models, analytic models or hybrid models using both simulation and analytic parts. An analytic model is made up of a set of equations describing the system behavior. The evaluation measures can be obtained by solving these equations. Actually, analytical models are mathematical models that present an abstraction from the real world system in relation to only the system behaviors and characteristics of interest.
This section introduces the model types used for evaluating the availability and reliability of a system. These types can be classified into these three classes:
Combinatorial model types
The three most common combinatorial model types which can be used for availability and reliability modeling under certain assumptions are “Fault Tree”, “Reliability Block Diagram” and “Reliability Graph”. These three models consider the structural relationships amongst the system components for analytical/numerical validations.
• Reliability block diagram
The reliability block diagram (RBD) is a type of inductive method which can be used for large and complex systems reliability and availability analysis. The series/parallel configuration of RBDs assist in modeling the logical interactions of complex system components failures [ 74 ]. RBDs can also be used to evaluate the dependability, availability and reliability of complex and large scale systems. In other words, it can be concluded that RBDs represent the logical structure of a system with respect to how the reliability of each component can affect the entire system reliability. In the RBD model, components can be organized into three: “Series”, “Parallel” or “k-out-of-n” configurations. In addition, these combinations together can be used in a single block diagram. Each component with the same type that appears more than once in the RBD is assumed to be a copy with independent and identical failure distribution. Every component has a failure probability, a failure rate, a failure distribution function or unavailability attached to it. A study of all existing RBD based reliability analysis techniques has been proposed by [ 74 ].
• Reliability graphs
The reliability graph is a schematic way of evaluating the availability and reliability. Generally, a reliability graph model consists of a set of nodes and edges, where the edges (arcs) represent components that have failure distributions. There is one node without any incoming edges in a reliability graph and is called the reliability graph source. In addition, there is another node without any outgoing edges and is called the sink or terminal or destination node. When there is no path from the source to the sink in a reliability graph model of a system, it is considered as a system failure. The edges can have failure probabilities, failure rates or distribution functions same as the RBDs.
• Fault tree
Fault trees are another type of combinatorial models widely used for assessing the reliability of complex systems through qualitative or quantitative analysis [ 75 ]. Fault trees can represent all the sequences of components failures that cause the entire system failure and stop system functioning, in a treelike structure. This method visualizes the cause of failure which can lead to the top event at different levels of detail up to basic events. Fault Tree Analysis (FTA) is a common probabilistic risk assessment technique that enables investigation of the safety and reliability of systems [ 76 ].
The root of a fault tree can simply be defined as a single and well-defined undesirable event. In the reliability and availability modeling, this undesirable event is the system failure. To evaluate the safety of the system, the potentially hazardous or unsafe condition is considered as an undesirable event. The fault tree is a schematic representation of a combination of events that can lead to the occurrence of a fault in the system.
State-space models
The models discussed in the previous section will be solved by using algorithms which assume that there is a stochastic independence interaction between different system components. Therefore, for availability or reliability modeling, it is assumed that the component failure or repair was not affected by other failures in the system. Therefore, to be able to model more complicated system interactions, other types of availability and reliability models such as state space models should be used.
State space models constitute a powerful method for capturing dependencies amongst system components. In other words, this model is a general approach for availability and reliability modeling which is a collection of stochastic variables which show the state of the system at any arbitrary time. The Markov chain is an example of this model type. A Markov model can be defined as a stochastic model which is used in the modeling of complex systems. It is assumed that future states in a Markov model only depend on the current state of the system. In other words, it is independent of the previous events. There are usually four known Markov models which can be used in different situations. The Markov chain is the simplest type.
A simple type of stochastic process which has the Markov properties can be considered as a Markov chain. The “Markov F Chain” term is used to refer to the sequence of the stochastic variables in this definition.
Reliability/availability modeling of any system may produce less precise results. The use of graceful degradation will make it possible for a system to provide its services at a reduced level in the existence of failures. The Markov reward model (MRM) is the usual method of modeling gracefully degradable systems [ 77 , 78 , 79 , 80 ]. In addition, the other common model types are: (1) Markov reward model or irreducible semi-Markov reward model and (2) stochastic reward nets.
Non-state-space models can help to achieve efficiency in specifying and solving the reliability evaluation, but these models assume that components are completely independent. For example, in RBDs, fault-tree or reliability graph, the components are considered as some completely independent entities in a system in terms of failure and repair behavior. It means these models assume that a component failure in a system cannot affect the function of another component. However, Markov models have the ability to model systems that reject the assumptions made by the non-state-space models but at the cost of the state space explosion.
Hierarchical models
Hierarchical models can assist in solving the state space explosion problem. They can allow the combination of random variables that show different system parameters to have a general distribution [ 81 ]. Therefore, by this approach, we can obtain more realistic reliability/availability models to analyze the complex systems. In other words, large-scale models can be avoided using hierarchical model composition. If the storage issue can be solved, the specification problem will be solved by using briefer model specifications which are transformable to the Markov models.
As a kind of summary for this section, we can express that in the context of availability and reliability modeling, many of the initial works focus on the use of Markov chains [ 82 , 83 , 84 , 85 , 86 ], because a cloud computing system is effectively considered as a complex availability problem. Other studies concentrate on the conceptual problems, priority and hierarchical graphs or the development of performance indices [ 87 ]. As stated earlier, combinatorial model types like RBDs consider the structural relationships amongst the system components which can represent the logical structure of a system with respect to how the reliability of its components affects the system’s reliability. In addition, state space models like Markov chains can be used for the modeling of more complicated interactions between components. Therefore, it seems that using hierarchical hybrid models [ 88 ], for example, combining RBDs and Generalized Stochastic Petri Nets (GSPNs) [ 89 ], RBDs and an MRM [ 90 ] are more suitable for evaluating cloud-based data centers’ availability and reliability.
To have a better understanding of reliability/availability models, the relationship between availability and reliability and their relationship with maintainability for determining the degradation states in details need to be considered, like the study proposed by [ 91 ]. Table 5 shows a summary of this study on these relationships.
Availability is defined as the probability that the system is operating properly at a given time t and when it is accessed for use. In other words, availability is defined as the probability that a system is functional and up at a specified time. At first, it would seem that if a system has a high availability, then it is also expected to have a high reliability. However, this is not necessarily true [ 91 ], as shown in Table 5 .
Reliability shows the probability of a system/component for performing the required functions in a period of time without failure. It does not contain any repair process in its definition. It also accounts for the period of time that it will take the system/component to fail during its operating time. Therefore, according to the definition of availability, it can be said that availability is not only a function of reliability, but it is also a function of maintainability. Table 5 shows the reliability, maintainability, and availability relationships. From this table, it should be noted that an increase in maintainability means a decrease in the repair time and maintenance actions period. As shown in Table 5 , if the reliability can be held constant, even at a high value, this does not directly mean providing high availability, because as the time to repair increases, the availability will decrease. Therefore, even a system with a low reliability could have a high availability provided that the repair time does not take too long.
Finally, for answering the ‘When’ question is to have an appropriate definition of availability. The definition of availability can be flexible, depending on the types of downtimes and actor’s points of view considered in the availability analysis. Therefore, different definition and classifications of availability can be offered. A classification of availability types has been proposed by [ 91 , 92 ]. In the following, four common types of availability will be introduced briefly:
• Instantaneous availability
Instantaneous availability is defined as the probability that a system is operating at any given time. This definition is somehow similar to the reliability function definition which gives the probability that a system will function at the given time t. However, different from the reliability definition, the instantaneous availability contains information on maintainability. According to the instantaneous availability, the system will be operational provided the following conditions could be met:
The required function can be properly provided during time t with probability R(t);
It can provide the required function since the last repair time like u, 0 < u < t, with the following probability:
where m (u) is the system renewal density function.
The instantaneous availability is calculated as:
• Mean availability
The average uptime availability or mean availability can be defined as the proportion of mission time or time period that a system is available for use. The mean value of the instantaneous availability over a specific period of time such as (0, T), is defined by this availability.
• Steady-state availability
The steady state availability can be determined by calculating the limit of the instantaneous availability as the time goes to infinity. In fact, when the time approximates to about four times the MTBF in instantaneous availability, it can be said that the instantaneous availability function approaches the steady state value. Therefore, the steady state availability can be calculated by using the following equation:
• Operational availability
Operational availability can be considered as an important measurement for evaluating the system effectiveness and performance. It evaluates the system availability which includes all the downtime sources, such as diagnostic downtime, administrative downtime, logistic downtime, etc. The operational availability is calculated as:
where the operating cycle is the overall time of the investigated operation period whereas Uptime is the system’s total functional time during the operating cycle. It is important to note that the availability that a customer actually experiences in the system is operational availability which is the availability according to the events that happened to the system.
“How to provide high availability and reliability while preventing performance degradation or supporting graceful degradation?”
As the last important step that should be taken, suitable solutions will be chosen to provide HA and reliability, while supporting graceful degradation based on the previous results as shown in Fig. 6 . Table 6 presents fault tolerance (FT) methods classification in cloud computing environments.

Proposed roadmap of the “How” step
By identifying the states which have higher failure rate and specifying the causes based on the results obtained from “Where?”, “Which?” and “When?” steps, we will be able to provide high available and reliable services in our cloud computing systems. Therefore, appropriate action can be taken according to the specific occurrence and failure type because there is no one-size-fits-all solution in the HA and reliability issues area.
Fault tolerance mechanisms deal with quick repairing and replacement of faulty components for retaining the system. FT in cloud computing systems is the ability to withstand the abrupt changes which occur due to different types of failures. Recovery point objective (RPO) and recovery time objective (RTO) are two major and important parameters in fault management study. The RPO shows the amount of data to be lost as a result of a fault or disaster, whereas RTO shows the minimum downtime for recovering from faults [ 93 ].
Ganesh et al. [ 93 ] presented a study on fault tolerance mechanisms in cloud computing environments. As noted in this paper, there are mainly two standard FT policies available for running real-time applications in the cloud; they are “Proactive Fault Tolerance Policy” and “Reactive Fault Tolerant Policy”. These FT policies are mainly used to provide fault tolerance mechanisms in the cloud.
The proactive fault tolerance policy is used to avoid failures by proactively taking preventive measures [ 95 , 96 , 97 ]. These measures are reserved by studying the pre-fault indicators and predicting the underlying faults. The next step is applying proactive fault tolerance measures by refactoring the code or failure prone components replacement at the development time. Using proactive fault tolerance mechanisms can guarantee that a job execution will be completed without any further reconfiguration [ 98 ].
The principle of reactive fault tolerance policy is based on dealing with measures applied for reducing the effects of the faults that already occurred in the cloud system. Table 6 shows a summary of this study on FT policies and techniques in cloud computing systems.
Although cloud computing systems have improved significantly over the past few years, improvements in computing power depend on system scale and complexity. Modern processing elements are extremely reliable, but they are not perfect [ 99 ]. The overall failure rate of high-performance computing (HPC) systems such as cloud systems, increases with their size [ 99 ]. Therefore, fault tolerating methods are important for systems with high failure rate.
Proactive FT policies in cooperation with failure prediction mechanisms can avoid failures by taking proactive actions. The recovery process overheads can be significantly reduced by using this technology [ 99 ]. Task migration is one of the widely used techniques in Proactive FT techniques. While task migration can avoid failures and achieve much lower overheads than Reactive FT techniques like Checkpointing/Restart, there are two shortcomings in this technique. First, migration will not be performed if there is no spare node for accommodating the processes of the suspect node. The second problem is that task migration is not an appropriate method for software errors [ 100 ]. Thus, a proactive fault tolerance method which only rely on migration cannot gain all advantages of the failure prediction.
One of the other techniques to provide fault tolerance in cloud environments is by using VM migration. Jung et al. [ 101 ] propose a VM migration scheme using Checkpointing to solve the task waiting time problem. A fault tolerant mechanism usually triggers the VM migration before a failure event. It actually backs VM to the same physical server after system maintenance ends [ 102 ].
Redundancy is a common technique for providing high available and reliable systems [ 103 ], but it could not be as effective as expected as a result of particular types of failures such as transient failures and software aging. The most common procedure for combating software aging is to apply software rejuvenation. A software rejuvenation process can be done by restarting the software application. Therefore, this technique will help to restart the application to its standard level of performance and effectively solve the software aging problem. In other words, software rejuvenation is a preventive and proactive technique which is particularly useful for counteracting the appearance of software aging, aimed at cleaning up the internal states of the system to prevent further and future failure events. Without any rejuvenation, both the OS software and the hosted running application software will be degraded in performance with time due to the exhaustion of system resources such as free memory that could finally lead to a system crash, which is very undesirable to HA systems and fatal to mission-critical applications. The disadvantage of rejuvenation is the temporary outage of service. To completely eliminate the service outage during the rejuvenation process, the use of virtualization technology is one of the possible approaches [ 104 ].
The software rejuvenation process can be applied to the system according to the different parameters of software aging or the elapsed time since the last rejuvenation event. Software rejuvenation can be used at different scopes like system, application, process, or thread [ 105 ].
A classification of techniques has been proposed by [ 106 ] which distinguishes between two classes of failure handling techniques, namely, task level failure handling and workflow level failure handling. The recovery techniques that can be performed at the task level for masking the fault effects are called task level techniques. These types of recovery techniques have been widely studied in distributed and parallel environments. These recovery techniques are classified into four different types: retry, alternate resource, checkpoint/restart, and replication techniques. Generally, it can be concluded that the two simplest task level techniques are retry and alternate, as they simply try to execute the same task on the same or alternate resource again after failure.
The checkpoint is mostly efficient for long-running applications. The checkpointing approach has attracted significant attention over the recent years in the context of fault tolerance research like studies that have been carried out by [ 107 , 108 , 109 , 110 ]. Generally, the checkpoint technique periodically saves the state of an application. After the checkpoint, failed tasks can restart from the failure point by moving the task to another resource. There are several different checkpointing solutions for large-scale distributed computing systems. A classification of checkpointing mechanisms have been proposed in [ 111 ]. It shows that these mechanisms can be classified based on four different viewpoints. From one viewpoint, the checkpointing mechanism can be classified into two groups called the incremental checkpointing mechanisms and the full checkpointing mechanisms, depending on whether the newly modified page states are saved or the entire system running states are stored. The second viewpoint classifies the checkpointing mechanisms into two local and global checkpointing mechanisms, according to how checkpointing data is saved, locally or globally. Depending on whether the checkpointing data is saved coordinately or not, the third classification can be proposed, which is organized into two coordinated checkpointing mechanisms and uncoordinated checkpointing mechanisms. Finally, it can be concluded that the last classification is based on saving the checkpointing data on disk or not, and they are called disk and diskless checkpointing mechanisms.
Finally, as the last task level technique, we point to the replication. Running the same task on different computing resources and simultaneously ensures that there is at least one successful completed task which is the replication technique [ 112 , 113 ].
As previously mentioned, workflow-level techniques are the second class of failures handling in distributed systems. Manipulating workflow structure for dealing with erroneous conditions is referred as workflow level technique. In other words, workflow level FTTs change the flow of execution on failure according to the knowledge of task execution context. They can also be classified into four different types: alternate task, redundancy, user defined exception handling and rescue workflow [ 106 ]. The only difference between alternate task and retry technique is that alternate task exchanges a task with a different implementation of the same task with different execution characteristics on the failure of the first one. The rescue workflow technique allows the workflow to continue even when task failure occurs. In another technique, the particular treatment to the task workflow is specified by the user and it is called user defined exception handling technique.
As a conclusion of the previous discussion, it can be said that both proactive and reactive fault tolerance policies have advantages and disadvantages. The results of the experiment show that migration techniques (proactive FT policy) are more efficient than checkpoint/restart techniques (reactive FT policy) [ 98 ]. Even though proactive techniques are more efficient, they are not frequently used. This is because the system is less affected by incorrect predictions due to proactive fault tolerance and also reactive methods are relatively simple to implement as FT techniques are not applied during the development time.
There is a serious gap in cloud computing fault tolerance research area, that is, the mutual impact of cloud performance overhead [ 52 , 114 , 115 , 116 , 117 ] and HA solutions.
There are hot topics like VM Granularity, IaaS Routing Operations (such as live VM migration, concurrent deployment and snapshotting of multiple VMs …), and the inability to isolate shared cloud network and storage resources in the cloud performance overhead research area. All these factors can impact on VM performance, total system performance and therefore VM’s availability and reliability. On the other hand, using additional mechanisms for providing HA and reliability in cloud computing systems can be considered as a system overhead which can have negative effects on system performance.
It seems that interesting and desired results would be achieved as the contribution of this research step by studying these mutual impacts for providing highly available and utilized cloud computing systems and considering performability concerns.
Discussion and open issues
Many research works have been carried out on cloud computing HA and reliability, but there is no comprehensive and complete overview of the entire problem domain. Attempt was made to propose a reference roadmap that covers all the aspects of the problem from different cloud actor’s viewpoints, especially cloud consumers and providers. This study proposed a big picture which divided the problem space into four main steps to cover the various requirements in the desired research area. A specific question was posed for each step that answering these questions will enable cloud providers to offer high available and reliable services. Therefore, while cloud providers can satisfy the cloud consumers’ requirements, they can also have highly utilized resources to achieve more business profits.
The four major questions starting with “Where?”, “Which?”, “When?” and “How” keywords form the main steps of the proposed roadmap. By taking these steps, our purposes can be achieved. In fact, taking each step means understanding the main concern presented by the specific question and proposing suitable solutions for that issue. Some suggestions were proposed as the primary answers for each of these questions which can be helpful for more future work in this research area. Making future research suggestions and proposing efficient solutions for each of these steps in the big picture is one of the important open issues in this study. Therefore, the proposed big picture can lead to future researches in cloud computing in the field of high availability and reliability.
Two main research gaps were specified through the proposed big picture, which have been neglected in the literature review. The first one is related to the providing HA and reliability solutions regardless of considering all cloud actors’ requirements and viewpoints. By proposing “Where” question, attempt was made to consider both cloud consumers and providers which are most important actors in the cloud computing environments. Therefore, not only was attention given to have a high available and reliable system, but also provider’s demands for having highly utilized systems were considered. The second research gap was proposed in “How” question section. As pointed out, adding an additional mechanism to the system can have negative effects on the total system performance. In addition, some performance overhead issues can degrade system availability and reliability. Therefore, this scientific hypothesis that system performance overhead and HA solutions can have the mutual impact on one another was proposed.
This paper presented a reference roadmap of HA and reliability problem in cloud computing systems that can lead to future research papers. By proposing this roadmap, all the different aspects of HA and reliability problem in cloud computing systems were specified. Furthermore, the effects of cloud computing main components on total system failure rate were studied according to the proposed eucalyptus-based architecture in our big picture. In this study, we focus on the comprehensive roadmap and covering all the different related aspects of HA and reliability in cloud environments. In addition, attempt was made to consider not only techniques (‘When’ and ‘How’ steps) that improve availability and reliability, but also characteristics (‘Where’ and ‘Which’ steps) of cloud computing systems. However, we will go into the details of specific technologies for each step as the future work of this study. Therefore, we can assess each step of the proposed solution in a more specific way. Evaluating the mutual impact of system performance overhead and HA solutions using the OpenStack platform is one of the main future works. SDN-based technology such as Espresso in Google cloud is one of the latest technology trends in cloud computing that can make cloud computing environments faster and more available. The application of this approach will be considered as a solution to ‘How’ step in future work. Furthermore, the contributions in this paper raise some other future works of reliability and HA in cloud computing through interesting proposed aspects of the problem. Some other significant future works are as follows:
A comprehensive study of cloud failure modes, causes and failure rate, and reliability/availability measuring tools;
A highly utilized and more profitable cloud economy that can guarantee the provision of highly available and reliable services.
Evaluating availability and reliability of cloud computing system and components based on the proposed architecture;
Studying the mutual impact of HA mechanisms and VM performance overhead.
Ardagna D (2015) Cloud and multi-cloud computing: current challenges and future applications. In: 7th international workshop on principles of engineering service-oriented and cloud systems (PESOS) 2015. IEEE/ACM, Piscataway, pp 1–2
Rastogi G, Sushil R (2015) Cloud computing implementation: key issues and solutions. In: 2nd international conference on computing for sustainable global development (INDIACom). IEEE, Piscataway, pp 320–324
Mell P, Grance T (2011) The NIST definition of cloud computing. Commun ACM 53(6):50
Google Scholar
Buyya R et al (2009) Cloud computing and emerging IT platforms: vision, hype, and reality for delivering computing as the 5th utility. Future Gener Comput Syst 25(6):599–616
Article Google Scholar
Puthal D et al (2015) Cloud computing features, issues, and challenges: a big picture. In: International conference on computational intelligence and networks (CINE). IEEE, Piscataway, pp 116–123
Mesbahi M, Rahmani AM (2016) Load balancing in cloud computing: a state of the art survey. Int J Mod Educ Comput Sci 8(3):64
Mesbahi M, Rahmani AM, Chronopoulos AT (2014) Cloud light weight: a new solution for load balancing in cloud computing. In: International conference (ICDSE) on data science and engineering. IEEE, Piscataway
Saab SA et al (2015) Partial mobile application offloading to the cloud for energy-efficiency with security measures. Sustain Comput Inf Syst 8:38–46
Keegan N et al (2016) A survey of cloud-based network intrusion detection analysis. Hum cent Comput Inf Sci 6(1):19
Article MathSciNet Google Scholar
Younge AJ et al (2012) Providing a green framework for cloud data centers. Handbook of energy-aware and green computing-two, vol set. Chapman and Hall, UK, pp 923–948
Yuan H, Kuo C-CJ, Ahmad I (2010) Energy efficiency in data centers and cloud-based multimedia services: an overview and future directions. In: Green computing conference, 2010 international. IEEE, Piscataway
Zakarya M, Gillam L (2017) Energy efficient computing, clusters, grids and clouds: a taxonomy and survey. Sustain Comput Inf Syst 14:13–33
Zhang Q et al (2014) RESCUE: an energy-aware scheduler for cloud environments. Sustain Comput Inf Syst 4(4):215–224
Bielik N, Ahmad I (2012) Cooperative game theoretical techniques for energy-aware task scheduling in cloud computing. In: Proceedings of the 2012 IEEE 26th international parallel and distributed processing symposium workshops and Ph.D. forum. IEEE Computer Society, Piscataway
Zhu X et al (2016) Fault-tolerant scheduling for real-time scientific workflows with elastic resource provisioning in virtualized clouds. IEEE Trans Parallel Distrib Syst 27(12):3501–3517
Moon Y et al (2017) A slave ants based ant colony optimization algorithm for task scheduling in cloud computing environments. Hum Cent Comput Inf Sci 7(1):28
Motavaselalhagh F, Esfahani FS, Arabnia HR (2015) Knowledge-based adaptable scheduler for SaaS providers in cloud computing. Hum Cent Comput Inf Sci 5(1):16
Gajbhiye A, Shrivastva KMP (2014) Cloud computing: need, enabling technology, architecture, advantages and challenges. In: 2014 5th international conference confluence the next generation information technology summit (Confluence). IEEE, Piscataway, pp 1–7
Durao F et al (2014) A systematic review on cloud computing. J Supercomput 68:1321–1346
Modi C et al (2013) A survey on security issues and solutions at different layers of cloud computing. J Supercomput 63(2):561–592
Dubrova E (2013) Fault-tolerant design. Springer, Berlin
Book MATH Google Scholar
Shooman ML (2002) Reliability of computer systems and networks. Wiley, Hoboken
Book Google Scholar
Dantas J et al (2015) Eucalyptus-based private clouds: availability modeling and comparison to the cost of a public cloud. Computing 97:1121–1140
Article MathSciNet MATH Google Scholar
Son S, Jung G, Jun SC (2013) An SLA-based cloud computing that facilitates resource allocation in the distributed data centers of a cloud provider. J Supercomput 64(2):606–637
Gagnaire M et al (2012) Downtime statistics of current cloud solutions. In: International working group on cloud computing resiliency. Tech. Rep. pp 176–189
Snyder B et al (2015) Evaluation and design of highly reliable and highly utilized cloud computing systems. J Cloud Comput Adv Syst Appl 4(1):11
Ranjithprabhu K, Sasirega D (2014) Eliminating single point of failure and data loss in cloud computing. Int J Sci Res (IJSR) 3(4):2319–7064
Tsidulko J (2017) The 10 biggest cloud outages of 2017 (So far). 2017; https://www.crn.com/slide-shows/cloud/300089786/the-10-biggest-cloud-outages-of-2017-so-far.htm . Accessed 1 Aug 2017
Celesti A, Fazio M, Villari M, Puliafito A (2016) Adding long-term availability, obfuscation, and encryption to multi-cloud storage systems. J Netw Comput Appl 59(C):208–218
Sampaio AM, Barbosa JG (2014) Towards high-available and energy-efficient virtual computing environments in the cloud. Future Gener = Comput Syst 40:30–43
Pérez-Miguel C, Mendiburu A, Miguel-Alonso J (2015) Modeling the availability of Cassandra. J Parallel Distrib Comput 86:29–44
An K et al (2014) A cloud middleware for assuring performance and high availability of soft real-time applications. J Syst Archit 60(9):757–769
Dwarakanathan S, Bass L, Zhu L (2015) Cloud application HA using SDN to ensure QoS. In: 8th international conference on cloud computing. IEEE, Piscataway, pp 1003–1007
Brenner S, Garbers B, Kapitza R (2014). Adaptive and scalable high availability for infrastructure clouds. In: Proceedings of the 14th IFIP WG 6.1. International conference on distributed applications and interoperable systems, vol 8460. Springer, New York, pp 16–30
Leslie LM, Lee YC, Zomaya AY (2015) RAMP: reliability-aware elastic instance provisioning for profit maximization. Journal Supercomput 71(12):4529–4554
Pan Y, Hu N (2014) Research on dependability of cloud computing systems. In: International conference on reliability, maintainability and safety (ICRMS). IEEE, Piscataway, pp 435–439
Hogan M et al (2011) NIST cloud computing standards roadmap. NIST Special Publication, 35
Kibe S, Uehara M, Yamagiwa M (2011) Evaluation of bottlenecks in an educational cloud environment. In: Third international conference on intelligent networking and collaborative systems (INCoS), 2011. IEEE, Piscataway
Arean O (2013) Disaster recovery in the cloud. Netw Secur 2013(9):5–7
Sharma K, Singh KR (2012) Online data back-up and disaster recovery techniques in cloud computing: a review. Int J Eng Innov Technol (IJEIT) 2(5):249–254
Xu L et al (2012) Smart Ring: A model of node failure detection in high available cloud data center. In: IFIP international conference on network and parallel computing. Springer, Berlin
Watanabe Y et al (2012) Online failure prediction in cloud datacenters by real-time message pattern learning. In: IEEE 4th International Conference on cloud computing technology and science (CloudCom), 2012. IEEE, Piscataway
Ongaro D et al (2011) Fast crash recovery in RAMCloud. In: Proceedings of the twenty-third ACM symposium on operating systems principles. ACM, Cascais
Amin Vahdat BK (2017) Espresso makes Google cloud faster, more available and cost effective by extending SDN to the public internet. https://www.blog.google/topics/google-cloud/making-google-cloud-faster-more-available-and-cost-effective-extending-sdn-public-internet-espresso/ . Accessed 4 Apr 2017
Endo PT et al (2016) High availability in clouds: systematic review and research challenges. J Cloud Comput 5(1):16
Liu B et al (2018) Model-based sensitivity analysis of IaaS cloud availability. Future Gener Comput Syst
Torres E, Callou G, Andrade E (2018) A hierarchical approach for availability and performance analysis of private cloud storage services. Computing 1:1–24
Snyder B et al (2015) Evaluation and design of highly reliable and highly utilized cloud computing systems. J Cloud Comput 4(1):1
Jammal M, Kanso A, Heidari P, Shami A (2017) Evaluating High Availability-aware deployments using stochastic petri net model and cloud scoring selection tool. IEEE Trans Serv Comput (1):1–1
Sampaio AM, Barbosa JG (2017) A comparative cost analysis of fault-tolerance mechanisms for availability on the cloud. Sustain Comput Inf Syst. https://doi.org/10.1016/j.suscom.2017.11.006
Sharkh MA et al (2015) Simulating high availability scenarios in cloud data centers: a closer look. In: IEEE 7th international conference on cloud computing technology and science (CloudCom), 2015. IEEE, Piscataway
Xu F et al (2014) Managing performance overhead of virtual machines in cloud computing: a survey, state of the art, and future directions. Proc IEEE 102(1):11–31
Zhang Q, Boutaba R (2014) Dynamic workload management in heterogeneous Cloud computing environments. In: Network operations and management symposium (NOMS). IEEE, Piscataway
Touseau L, Donsez D, Rudametkin W (2008) Towards a sla-based approach to handle service disruptions. In: IEEE international conference on services computing, SCC’08. IEEE, Piscataway
Wang FZ, Zhang L, Deng Y, Zhu W, Zhou J, Wang F (2014) Skewly replicating hot data to construct a power-efficient storage cluster. J Netw Comput Appl 7(1):1–12
Xie T, Sun Y (2009) A file assignment strategy independent of workload characteristic assumptions. ACM Trans Storage (TOS) 5(3):10
MathSciNet Google Scholar
Mesbahi MR, Rahmani AM, Hosseinzadeh M (2017) Highly reliable architecture using the 80/20 rule in cloud computing datacenters. Future Gener Comput Syst 77:77–86
Moor Hall C (2009) How to analyse your business sale—80/20 rule. The chartered institute of marketing, UK, pp 1–6
Foster I et al (2008) Cloud computing and grid computing 360-degree compared. In: Grid computing environments workshop, 2008. GCE’08. IEEE, Piscataway
Mishra AK et al (2010) Towards characterizing cloud backend workloads: insights from Google compute clusters. ACM SIGMETRICS Perform Eval Rev 37(4):34–41
Li X, Qiu J (2014) Cloud computing for data-intensive applications. Springer, Berlin
Jha S et al A tale of two data-intensive paradigms: applications, abstractions, and architectures. In: 2014 IEEE international congress on big data (BigData Congress), 2014. IEEE, Piscataway
Yang X et al (2014) Cloud computing in e-Science: research challenges and opportunities. J Supercomput 70(1):408–464
Barbar JS, Lima GDO, Nogueira A (2014) A model for the classification of failures presented in cloud computing in accordance with the SLA. In: International conference on computational science and computational intelligence (CSCI), 2014. IEEE, Piscataway
Vishwanath KV, Nagappan N (2010) Characterizing cloud computing hardware reliability. In Proceedings of the 1st ACM symposium on cloud computing. ACM, Indianapolis, pp 193–204
Serrano M (2012) Applied ontology engineering in cloud services, networks and management systems. Springer Science & Business Media, Berlin
Pan Y, Hu N (2014) Research on dependability of cloud computing systems. In: International conference on reliability, maintainability and safety (ICRMS), 2014. IEEE. Piscataway
Woods V (2015) Gartner reveals top predictions for it organizations and users for 2016 and beyond. http://www.gartner.com/newsroom/id/3143718 . Accessed 6 Oct 2015
Price D Five high profile cloud-based failures. May 20, 2014; Available from: http://cloudtweaks.com/2014/05/five-high-profile-cloud-based-failures/
Gill P, Jain N, Nagappan N (2011) Understanding network failures in data centers: measurement, analysis, and implications. In: ACM SIGCOMM computer communication review. 2011, ACM, Toronto, pp 350–361
Serrano M, Orozco JMS (2012) Applied ontology engineering in cloud services, networks and management systems. Springer Science & Business Media, Berlin
Nightingale EB, Douceur JR, Orgovan V (2011) Cycles, cells and platters: an empirical analysis of hardware failures on a million consumer PCs. In: Proceedings of the sixth conference on Computer systems. 2011, ACM, New York, pp 343–356
Wang W, Loman J, Vassiliou P (2004) Reliability importance of components in a complex system. In: Reliability and maintainability, 2004 annual symposium-RAMS. IEEE, Piscataway, pp 6–11
Hasan O et al (2015) Reliability block diagrams based analysis: a survey. Analysis 1:1
Ni J, Tang W, Xing Y (2013) A simple algebra for fault tree analysis of static and dynamic systems. IEEE Trans Reliab 62(4):846–861
Behringer, B, Lehser M, Rothkugel S (2014) Towards feature-oriented fault tree analysis. In: 38th International computer software and applications conference workshops (COMPSACW). IEEE, Piscataway
Telek M, Horváth A, Horváth G (2004) Analysis of inhomogeneous Markov reward models. Linear Algeb Appl 386:383–405
Baier C et al (2010) Performability assessment by model checking of Markov reward models. Formal Methods Syst Des 36(1):1–36
Hong Z, Wang Y, Shi M (2012) CTMC-Based Availability Analysis of Cluster System with Multiple Nodes. In: Jin D, Lin S (eds) Advances in Future Computer and Control Systems. Advances in Intelligent and Soft Computing, vol 160. Springer, Berlin, Heidelberg
Chapter Google Scholar
Leangsuksuna C, Shen L, Songa H, Scottb SL, Haddacf I (2003) The Modeling and dependability analysis of high availability OSCAR cluster system. In: Comptes Rendus Du 17ième Symposium Annuel International Sur Les Systèmes Et Applications Du Calcul de Haute Performance Et Le Symposium OSCAR. NRC Research Press, Ottawa, Canada, p 285
Veeraraghavan M, Trivedi K (1988) Hierarchical modeling for reliability and performance measures. Concurrent computations. Springer, Boston, MA, pp 449–474
Kim DS, Machida F, Trivedi KS (2009) Availability modeling and analysis of a virtualized system. In: 15th IEEE pacific rim international symposium on dependable computing, 2009. PRDC’09. IEEE, Piscataway
Ghosh R et al (2012) Interacting Markov chain based hierarchical approach for cloud services. Technical report, IBM (April 2010). http://domino.research.ibm.com/library/cyberdig.nsf/papers/AABCE247ECDECE0F8525771A005D42B6 . Accessed Feb 2018
Che J et al (2011) A markov chain-based availability model of virtual cluster nodes. In: 2011 Seventh international conference on computational intelligence and security (CIS). IEEE, Piscataway
Zheng J, Okamura H, Dohi T (2012) In: Component importance analysis of virtualized system. In: 9th international conference on ubiquitous intelligence and computing and 9th international conference on autonomic and trusted computing (UIC/ATC), 2012. IEEE, Piscataway
Ghosh R et al (2014) Scalable analytics for IAAS cloud availability. IEEE Trans Cloud Comput 2(1):57–70
Ferrari A, Puccinelli D, Giordano S (2012) Characterization of the impact of resource availability on opportunistic computing. In: Proceedings of the first edition of the MCC workshop on Mobile cloud computing. ACM, New York
Chuob S, Pokharel M, Park JS (2011) Modeling and analysis of cloud computing availability based on eucalyptus platform for e-government data center. In: Fifth international conference on innovative mobile and internet services in ubiquitous computing (IMIS). IEEE, Piscataway
Wei B, Lin C, Kong X (2011) Dependability modeling and analysis for the virtual data center of cloud computing. In: 13th International conference on high performance computing and communications (HPCC). IEEE, Piscataway
Dantas J et al (2012) An availability model for eucalyptus platform: an analysis of warm-standy replication mechanism. In: International conference on systems, man, and cybernetics (SMC). IEEE, Piscataway
Relationship between availability and reliability. 2003. http://www.weibull.com/hotwire/issue26/relbasics26.htm . Accessed Feb 2018.
Katukoori VK (1995) Standardizing availability definition. University of New Orleans, New Orleans
Ganesh A, Sandhya M, Shankar S (2014) A study on fault tolerance methods in cloud computing. In: IEEE international advance computing conference (IACC), 2014. IEEE, Piscataway
Jhawar R, Piuri V, Santambrogio M (2013) Fault tolerance management in cloud computing: a system-level perspective. IEEE Syst J 7(2):288–297
Egwutuoha IP et al (2012) A proactive fault tolerance approach to high performance computing (HPC) in the cloud. In: second international conference on cloud and green computing (CGC). IEEE, Piscataway
Jhawar R, Piuri V, Santambrogio M (2013) Fault tolerance management in cloud computing: a system-level perspective. Syst J IEEE 7(2):288–297
Ji X, Ma Y, Ma R, Li P, Ma J, Wang, G et al (2015) A proactive fault tolerance scheme for large scale storage systems. In: International conference on algorithms and architectures for parallel processing. Springer, Cham, pp 337–350
Ganesh A, Sandhya M, Shankar S (2014) A study on fault tolerance methods in cloud computing. In: International advance computing conference (IACC). IEEE, Piscataway
Zhu L et al (2015) Optimizing the fault-tolerance overheads of HPC systems using prediction and multiple proactive actions. J Supercomput 71(10):3668–3694
Cappello F et al (2009) Toward exascale resilience. Int J High Perform Comput Appl 23:374–388
Jung D, Chin S, Chung KS, Yu H (2013) VM migration for fault tolerance in spot instance based cloud computing. In: International conference on grid and pervasive computing. Springer, Berlin, Heidelberg, pp 142–151
Ahmad RW et al (2015) Virtual machine migration in cloud data centers: a review, taxonomy, and open research issues. J Supercomput 71:2473–2515
Zhang J, Li S, Liao X (2016) REDU: reducing redundancy and duplication for multi-failure recovery inerasure-coded storages. J Supercomput 72(9):3281–3296
Yang C-T et al (2014) On improvement of cloud virtual machine availability with virtualization fault tolerance mechanism. Journal Supercomput 69(3):1103–1122
Yang M et al (2014) Software rejuvenation in cluster computing systems with dependency between nodes. Computing 96(6):503–526
Qureshi K et al (2011) A hybrid fault tolerance technique in grid computing system. J Supercomput 56(1):106–128
Nazir B, Qureshi K, Manuel P (2009) Adaptive checkpointing strategy to tolerate faults in economy based grid. Journal of Supercomput 50(1):1–18
Liu H et al (2012) VMckpt: lightweight and live virtual machine checkpointing. Science China Information Sciences 55(12):2865–2880
Du Y et al (2014) FITDOC: fast virtual machines checkpointing with delta memory compression. In: IEEE 17th international conference on computational science and engineering (CSE), 2014. IEEE, Piscataway
Losada N, Cores I, Martín MJ, González P (2017) Resilient MPI applications using an application-levelcheckpointing framework and ULFM. J Supercomput 73(1):100–113
Sun D et al (2013) Analyzing, modeling and evaluating dynamic adaptive fault tolerance strategies in cloud computing environments. J Supercomput 66(1):193–228
Nazir B, Qureshi K, Manuel P (2012) Replication based fault tolerant job scheduling strategy for economy driven grid. J Supercomput 62(2):855–873
Tos U et al (2015) Dynamic replication strategies in data grid systems: a survey. J Supercomput 71(11):4116–4140
Koh Y et al (2007) An analysis of performance interference effects in virtual environments. In: IEEE International symposium on performance analysis of systems and software, 2007. ISPASS 2007. IEEE, Piscataway
Wang P, Huang W, Varela CA (2010) Impact of virtual machine granularity on cloud computing workloads performance. In: 11th IEEE/ACM international conference on grid computing (GRID), 2010. IEEE, Piscataway
Liu X et al (2014) Performance analysis of cloud computing services considering resources sharing among virtual machines. J Supercomput 69(1):357–374
Yang B, Tan F, Dai Y-S (2013) Performance evaluation of cloud service considering fault recovery. J Supercomput 65(1):426–444
Download references
Authors’ contributions
All authors contributed equally to this manuscript. All authors read and approved the final manuscript.
Acknowledgements
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Availability of data and materials
No funding was received.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Author information
Authors and affiliations.
Department of Computer Engineering, Science and Research Branch, Islamic Azad University, Tehran, Iran
Mohammad Reza Mesbahi & Amir Masoud Rahmani
Computer Science, University of Human Development, Sulaimanyah, Iraq
Amir Masoud Rahmani
Iran University of Medical Sciences, Tehran, Iran
Mehdi Hosseinzadeh
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Amir Masoud Rahmani .
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License ( http://creativecommons.org/licenses/by/4.0/ ), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Reprints and permissions
About this article
Cite this article.
Mesbahi, M.R., Rahmani, A.M. & Hosseinzadeh, M. Reliability and high availability in cloud computing environments: a reference roadmap. Hum. Cent. Comput. Inf. Sci. 8 , 20 (2018). https://doi.org/10.1186/s13673-018-0143-8
Download citation
Received : 05 February 2018
Accepted : 16 June 2018
Published : 06 July 2018
DOI : https://doi.org/10.1186/s13673-018-0143-8
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Reliability
- High availability
- Cloud computing
- Big picture
- Original Papers
- Open access
- Published: 20 April 2010
Cloud computing: state-of-the-art and research challenges
- Qi Zhang 1 ,
- Lu Cheng 1 &
- Raouf Boutaba 1
Journal of Internet Services and Applications volume 1 , pages 7–18 ( 2010 ) Cite this article
90k Accesses
2081 Citations
28 Altmetric
Metrics details
Cloud computing has recently emerged as a new paradigm for hosting and delivering services over the Internet. Cloud computing is attractive to business owners as it eliminates the requirement for users to plan ahead for provisioning, and allows enterprises to start from the small and increase resources only when there is a rise in service demand. However, despite the fact that cloud computing offers huge opportunities to the IT industry, the development of cloud computing technology is currently at its infancy, with many issues still to be addressed. In this paper, we present a survey of cloud computing, highlighting its key concepts, architectural principles, state-of-the-art implementation as well as research challenges. The aim of this paper is to provide a better understanding of the design challenges of cloud computing and identify important research directions in this increasingly important area.
Al-Fares M et al (2008) A scalable, commodity data center network architecture. In: Proc SIGCOMM
Amazon Elastic Computing Cloud, aws.amazon.com/ec2
Amazon Web Services, aws.amazon.com
Ananthanarayanan R, Gupta K et al (2009) Cloud analytics: do we really need to reinvent the storage stack? In: Proc of HotCloud
Armbrust M et al (2009) Above the clouds: a Berkeley view of cloud computing. UC Berkeley Technical Report
Berners-Lee T, Fielding R, Masinter L (2005) RFC 3986: uniform resource identifier (URI): generic syntax, January 2005
Bodik P et al (2009) Statistical machine learning makes automatic control practical for Internet datacenters. In: Proc HotCloud
Brooks D et al (2000) Power-aware microarchitecture: design and modeling challenges for the next-generation microprocessors, IEEE Micro
Chandra A et al (2009) Nebulas: using distributed voluntary resources to build clouds. In: Proc of HotCloud
Chang F, Dean J et al (2006) Bigtable: a distributed storage system for structured data. In: Proc of OSDI
Chekuri C, Khanna S (2004) On multi-dimensional packing problems. SIAM J Comput 33(4):837–851
Article MATH MathSciNet Google Scholar
Church K et al (2008) On delivering embarrassingly distributed cloud services. In: Proc of HotNets
Clark C, Fraser K, Hand S, Hansen JG, Jul E, Limpach C, Pratt I, Warfield A (2005) Live migration of virtual machines. In: Proc of NSDI
Cloud Computing on Wikipedia, en.wikipedia.org/wiki/Cloudcomputing , 20 Dec 2009
Cloud Hosting, CLoud Computing and Hybrid Infrastructure from GoGrid, http://www.gogrid.com
Dean J, Ghemawat S (2004) MapReduce: simplified data processing on large clusters. In: Proc of OSDI
Dedicated Server, Managed Hosting, Web Hosting by Rackspace Hosting, http://www.rackspace.com
FlexiScale Cloud Comp and Hosting, www.flexiscale.com
Ghemawat S, Gobioff H, Leung S-T (2003) The Google file system. In: Proc of SOSP, October 2003
Google App Engine, URL http://code.google.com/appengine
Greenberg A, Jain N et al (2009) VL2: a scalable and flexible data center network. In: Proc SIGCOMM
Guo C et al (2008) DCell: a scalable and fault-tolerant network structure for data centers. In: Proc SIGCOMM
Guo C, Lu G, Li D et al (2009) BCube: a high performance, server-centric network architecture for modular data centers. In: Proc SIGCOMM
Hadoop Distributed File System, hadoop.apache.org/hdfs
Hadoop MapReduce, hadoop.apache.org/mapreduce
Hamilton J (2009) Cooperative expendable micro-slice servers (CEMS): low cost, low power servers for Internet-scale services In: Proc of CIDR
IEEE P802.3az Energy Efficient Ethernet Task Force, www.ieee802.org/3/az
Kalyvianaki E et al (2009) Self-adaptive and self-configured CPU resource provisioning for virtualized servers using Kalman filters. In: Proc of international conference on autonomic computing
Kambatla K et al (2009) Towards optimizing Hadoop provisioning in the cloud. In: Proc of HotCloud
Kernal Based Virtual Machine, www.linux-kvm.org/page/MainPage
Krautheim FJ (2009) Private virtual infrastructure for cloud computing. In: Proc of HotCloud
Kumar S et al (2009) vManage: loosely coupled platform and virtualization management in data centers. In: Proc of international conference on cloud computing
Li B et al (2009) EnaCloud: an energy-saving application live placement approach for cloud computing environments. In: Proc of international conf on cloud computing
Meng X et al (2010) Improving the scalability of data center networks with traffic-aware virtual machine placement. In: Proc INFOCOM
Mysore R et al (2009) PortLand: a scalable fault-tolerant layer 2 data center network fabric. In: Proc SIGCOMM
NIST Definition of Cloud Computing v15, csrc.nist.gov/groups/SNS/cloud-computing/cloud-def-v15.doc
Osman S, Subhraveti D et al (2002) The design and implementation of zap: a system for migrating computing environments. In: Proc of OSDI
Padala P, Hou K-Y et al (2009) Automated control of multiple virtualized resources. In: Proc of EuroSys
Parkhill D (1966) The challenge of the computer utility. Addison-Wesley, Reading
Google Scholar
Patil S et al (2009) In search of an API for scalable file systems: under the table or above it? HotCloud
Salesforce CRM, http://www.salesforce.com/platform
Sandholm T, Lai K (2009) MapReduce optimization using regulated dynamic prioritization. In: Proc of SIGMETRICS/Performance
Santos N, Gummadi K, Rodrigues R (2009) Towards trusted cloud computing. In: Proc of HotCloud
SAP Business ByDesign, www.sap.com/sme/solutions/businessmanagement/businessbydesign/index.epx
Sonnek J et al (2009) Virtual putty: reshaping the physical footprint of virtual machines. In: Proc of HotCloud
Srikantaiah S et al (2008) Energy aware consolidation for cloud computing. In: Proc of HotPower
Urgaonkar B et al (2005) Dynamic provisioning of multi-tier Internet applications. In: Proc of ICAC
Valancius V, Laoutaris N et al (2009) Greening the Internet with nano data centers. In: Proc of CoNext
Vaquero L, Rodero-Merino L, Caceres J, Lindner M (2009) A break in the clouds: towards a cloud definition. ACM SIGCOMM computer communications review
Vasic N et al (2009) Making cluster applications energy-aware. In: Proc of automated ctrl for datacenters and clouds
Virtualization Resource Chargeback, www.vkernel.com/products/EnterpriseChargebackVirtualAppliance
VMWare ESX Server, www.vmware.com/products/esx
Windows Azure, www.microsoft.com/azure
Wood T et al (2007) Black-box and gray-box strategies for virtual machine migration. In: Proc of NSDI
XenSource Inc, Xen, www.xensource.com
Zaharia M et al (2009) Improving MapReduce performance in heterogeneous environments. In: Proc of HotCloud
Zhang Q et al (2007) A regression-based analytic model for dynamic resource provisioning of multi-tier applications. In: Proc ICAC
Download references
Author information
Authors and affiliations.
University of Waterloo, Waterloo, Ontario, Canada, N2L 3G1
Qi Zhang, Lu Cheng & Raouf Boutaba
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Raouf Boutaba .
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Reprints and permissions
About this article
Cite this article.
Zhang, Q., Cheng, L. & Boutaba, R. Cloud computing: state-of-the-art and research challenges. J Internet Serv Appl 1 , 7–18 (2010). https://doi.org/10.1007/s13174-010-0007-6
Download citation
Received : 08 January 2010
Accepted : 25 February 2010
Published : 20 April 2010
Issue Date : May 2010
DOI : https://doi.org/10.1007/s13174-010-0007-6
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Cloud computing
- Data centers
- Virtualization
Advances, Systems and Applications
- Open access
- Published: 12 July 2021
Survey on serverless computing
- Hassan B. Hassan 1 ,
- Saman A. Barakat 2 &
- Qusay I. Sarhan 2
Journal of Cloud Computing volume 10 , Article number: 39 ( 2021 ) Cite this article
30k Accesses
46 Citations
1 Altmetric
Metrics details
Serverless computing has gained importance over the last decade as an exciting new field, owing to its large influence in reducing costs, decreasing latency, improving scalability, and eliminating server-side management, to name a few. However, to date there is a lack of in-depth survey that would help developers and researchers better understand the significance of serverless computing in different contexts. Thus, it is essential to present research evidence that has been published in this area. In this systematic survey, 275 research papers that examined serverless computing from well-known literature databases were extensively reviewed to extract useful data. Then, the obtained data were analyzed to answer several research questions regarding state-of-the-art contributions of serverless computing, its concepts, its platforms, its usage, etc. We moreover discuss the challenges that serverless computing faces nowadays and how future research could enable its implementation and usage.
Introduction
Cloud computing emerged after the appearance of virtualization in software and hardware infrastructures; hence cloud providers increasingly adopted it to offer their services to customers [ 1 , 2 ]. Customers can access these cloud services via the Internet. Software developers have been using cloud technologies in their software solutions owing to their benefits including scalability, availability, and flexibility [ 3 ].
In general, cloud computing is divided into three main categories based on the provision of services, which are software as a service (SaaS), platform as a service (PaaS), and infrastructure as a service (IaaS). In the SaaS category, cloud providers offer different types of software as services to the users. For example, Google provides many applications as a service (e.g., Gmail, Google docs, Google sheets, and Google forms). In this type of cloud, the user is not responsible for the services development, deployment, and management. The user here only uses them without worrying about their settings, configurations, etc. Meanwhile, in the PaaS, cloud companies provide services such as network access, storage, servers, and operating systems to be purchased by developers. The developers access these services to deploy, run, and manage their applications. In this kind of cloud, the developer is responsible for the deployment and management (settings and configurations) of their software to ensure that the application is running, while they do not control the services. Finally, in the IaaS category, the cloud consumers control and manage services such as network access, servers, operating systems, and storage.
Managing cloud services is not an easy task at all. The authors in [ 4 ] have addressed several challenges while managing a cloud environment by a user such as availability, load balancing, auto-scaling, security, monitoring, etc. For example, the cloud user has to ensure the availability of the services in which if a single machine failure occurs, it does not affect the whole services. Also, he/she has to consider distributing copies of the services geographically to protect them when disasters happen. Another challenge is load balancing. In this case, the cloud user has to ensure that requests to the services are balanced to utilize all resources efficiently.
These challenges have led to introduce another cloud computing model, which is called serverless cloud computing [ 4 ]. Serverless cloud computing offers backend as a service (BaaS) and function as a service (FaaS), as shown in Fig. 1 . The BaaS includes services like storage, messaging, user management, etc. While, the FaaS enables developers to deploy and execute their code on computing platforms. The FaaS relies on the services provided by the BaaS such as a database, messaging, user authentications, etc. The FaaS is considered as the most dominant model of serverless, and it is also known as “event-driven functions” [ 5 , 6 ].

Serverless architecture
Serverless cloud model was for the first time introduced by Amazon Lambda in 2014, after which cloud companies like Google and Microsoft adopted it in 2016. Serverless cloud computing adds an additional abstraction layer to the existing cloud computing paradigms, while it abstracts away the server-side management from the developers [ 7 ]. Serverless model lets the developers focus on the application logic rather than the server-side management and configurations. For example, the developers deploy their applications to the serverless cloud as functions see Fig. 1 . Then, the cloud provider takes responsibility for managing, scaling, and providing different resources to ensure the smooth running of these functions [ 8 , 9 ].
However, FaaS and the term “serverless” could be used interchangeably, as the FaaS platform automatically configures and maintains the execution context of functions and connects them to cloud services without requiring server provision by developers [ 10 , 11 ]. We refer to the FaaS when we use the term serverless computing.
Serverless cloud computing has many good characteristics [ 12 , 13 ], one of which is scalability. Scaling could be vertical or horizontal; vertical scaling adds or removes cores from the running container, while horizontal scaling creates new containers or eliminates running ones without affecting the current resource allocations [ 14 ]. In serverless computing, the applications automatically scale up and down on demand, and the developer does not have to concern themselves about the scaling issues. For example, when an application runs on a serverless cloud, it will scale up automatically when the application requests increase. Another characteristic of serverless computing is the payment per resource usage. This paradigm of cloud computing charges developers based on the actual resource usage. For example, deploying an application will not cost the developer in the case where the application is idle, and the serverless provider will only charge whenever the application has started using resources.
However, any new technology will face numerous technical and operational issues and obstacles at the beginning. Since the recent introduction of serverless cloud computing, several drawbacks have been identified [ 7 ]. Serverless cloud computing lacks tools that help managing and monitoring serverless applications. Moreover, it might comprise security concerns. Further, the serverless providers have a vendor lock-in problem. Nevertheless, serverless cloud computing has gained positive attention in the industry, despite that it has not been studied extensively in academic research [ 7 ].
Therefore, the aim of this research is to answer some crucial research questions related to serverless cloud computing and thereby help researchers as well as developers to better understand serverless cloud computing and contribute to its development.
The rest of this paper is structured as follows: “ Related works ” section presents the related works for this study. “ Research methodology ” section describes in detail the research methodology used to conduct this survey study. “ Results ” section presents the results and outcomes of the study. “ Threats to validity ” section presents the threats to validity of this study. Finally, the conclusions of the study are provided in “ Conclusions ” section.
Related works
The most relevant studies published on the topic are briefly presented here. The authors in [ 15 ] and [ 16 ] discussed some important background to the origin and evolution of serverless computing and the long road that serverless computing has taken over the years. The authors in [ 9 ] thoroughly discussed the true meaning of serverless architectures and how they are changing the way in which applications are built, deployed, and distributed.
Numerous studies focused on technical interpretations of serverless computing, while other more recent research suggested various benefits that it brings to developers. Nowadays, this type of computing is being used in several ways. In an empirical study, the authors in [ 17 ] aimed to investigate the development practices of serverless computing in the industry. They concluded that for developers, it remains a barrier to adopt the right mindset to best utilize the tools inherent to serverless architecture. More documentation and easier access to such resources would help developers to embrace the possibilities that serverless computing has to offer.
The concept of serverless computing within the scope of the IT industry has the great potential of progressively increasing its capabilities to involve a wider set of domains. Thus, the implementation of serverless computing is not restricted only to the enhancement of infrastructure, and it can be employed for many different purposes, e.g., serverless messaging, neural network training [ 18 ], video processing [ 19 ], and big data [ 20 ]. Undeniably, their contributions are valuable to the general public and researchers in the field, as it is of primarily importance to comprehend how this technology works.
However, it is presently crucial to provide more than only theories and concepts: it is time to weigh the benefits and drawbacks of serverless computing and to analyze how far the field has progressed, to assess what remains to be done and improved. As an example, the authors in [ 21 ] discussed some possible new abstraction levels to reduce processing limitations. The authors in [ 22 ] discussed the results from an open-source framework to achieve on-premises serverless computing that can process big workloads with a scalable and sensible usage of resources. We can infer from these related publications that researchers everywhere are working to determine how to best exploit the potential that serverless computing frameworks could introduce to software development.
In [ 23 ], the authors described how serverless computing is becoming the next step in the evolution of cloud computing and its platforms. In our paper, we focus on the ongoing challenges, benefits, and drawbacks of using it.
The authors in [ 24 ] have conducted a systematic exploration of serverless computing-related research papers. As they mentioned, their work is not a survey, but it is a supporting source for future research papers. They proposed an open dataset for serverless computing papers. The dataset includes 60 papers for the period (2016-July 2018). Also, they have analyzed the dataset according to bibliometric, content, technology, and produced statistics about each section. In contrast, our paper aims to conduct a systematic survey. In this survey, we try to find answers to several critical questions related to serverless computing. In addition to that, our study covered the duration (2016–2020) and thus 275 papers have been considered.
The authors in [ 25 ] mainly focused on scheduling tasks in the cloud. They described the various techniques in scheduling workflows to reduce the execution time, cost, or both. Moreover, they proposed a hybrid method by both FaaS and IaaS. The small tasks could be executed remotely using the FaaS, which reduces the execution cost; hence, the number of virtual machines will be decreased as well. Therefore, the whole focus would be on the long-running tasks on IaaS.
The authors in [ 26 ] covered only 24 research papers during 2017–2019. In their paper, they considered both the white and grey literatures. Besides, they identified 32 characteristics of serverless and the possible issues related to them, only eight of them were stated by both white and grey literatures while the remaining are from grey literature only. All the characteristics are explained and presented briefly. In our paper, 275 research papers from 2016–2020 have been covered and more research questions have been answered. Besides, a well-defined systematic literature study process has been employed. Thus, the grey literature has been excluded in our paper and, our results are reproducible compared to their results.
The authors in [ 27 ] mainly concentrated on difficulties and gaps in data-centric and distributed computing using FaaS. Additionally, they evaluated the severity of these challenges via taking three case studies from big data and distributed computing settings: model training, low-latency prediction serving using the batch and, distributed computing. While our paper is a broad and comprehensive study on FaaS, 275 research papers are taken from the white literature during 2016–2020.
The paper [ 28 ] presented only four use cases of FaaS: event-triggered computing, video broadcasting, Internet of Things (IoT) data processing, and shared delivery system. Additionally, the paper only compared three platforms namely, Amazon web services (AWS) Lambda, Google Cloud Function, and Microsoft Azure Function. On the other hand, our paper presents a comprehensive study about FaaS. We identified in detail eight use cases: chatbot, information retrieval, file processing, smart grid, security, networks and, mobile and IoT. Moreover, our paper compared ten FaaS platforms namely, AWS Lambda, Apache OpenWhisk, Microsoft Azure functions, Google Cloud functions, OpenLambda, IBM Cloud functions, OpenFaaS, Knative, FunctionStage, Huawei Cloud, and Nuclio.
The authors in [ 29 ] covered only 15 papers during 2016–2018. They took both the white and grey literatures into account. On the other hand, our paper includes 275 research papers published in the period 2016–2020; they are taken from the white literature only. Moreover, our paper has formulated and answered eight clear and well-defined research questions.
The authors in [ 30 ] focused on the FaaS performance evaluation and their publication trends during 2016–2019. They identified the most commonly evaluated FaaS platforms. Additionally, they evaluated the performance features for benchmark types, micro-benchmarks, and common features across FaaS platforms. Moreover, they presented the most common platform configurations in FaaS, namely language runtimes, function triggers, and external services. This paper presents a survey of the most important and state of the art aspects of FaaS. Besides, comprehensive theoretical aspects of FaaS are covered taking from the white literature during 2016–2020.
The authors in [ 11 ] have conducted a systematic mapping study on serverless cloud computing. The main aim of their study is to concentrate on FaaS engineering. They raised two main concerns: (a) identifying publication research that considers developing or modifying serverless platforms and tools. (b) identifying the challenges and drivers related to these publications. On the other hand, our study extends the challenges and issues related to serverless computing. Moreover, we provide more details about serverless computing platforms and the use of these platforms in the literature. Also, it provides a detailed comparison among the most widely used serverless platforms. Besides, it addresses more aspects of serverless cloud computing such as application areas of serverless computing, future directions of serverless computing, etc.
The authors in [ 7 ] provided useful observations about serverless computing, its architecture, and use cases. Also, they discussed the challenges and benefits of moving forward from monolithic applications and the differences between traditional cloud services and serverless computing. Our work has extended the details of their work regarding the benefits and drawbacks of using serverless computing. It has also included more use cases and workloads to deepen the findings of previous studies.
The authors in [ 4 ] presented a technical report on serverless computing. They covered the serverless emergence with its limitations, including limited storage for fine-grained tasks, lack of coordination among functions, inadequate performance for standard communication patterns, and functions’ performance. Also, they compared AWS serverful with AWS serverless. Moreover, they also explained the challenges of architecture, networking, security, and abstractions of serverless computing. They identified five application areas including, video encoding in real-time, MapReduce, linear algebra, machine learning training, and databases. While our paper has covered 275 research papers from 2016–2020 forming a well-defined systematic literature study. We also identified 21 serverless challenges and issues. Besides, we compared serverless with the traditional cloud computing paradigm. We identified more application areas including, chatbot, information retrieval, file processing, smart grid, security, networks, IoT, and edge computing.
The authors in [ 31 ] presented a white paper based on published research papers during 2015–2017. They outlined the serverless definition alongside its advantages and disadvantages. Also, they classified serverless use-cases into six categories, namely, backends, web applications, chatbots, big data, IT automation, and Amazon Alexa. Moreover, they addressed a few research questions including, the need for the stateless feature in serverless, whether serverless could execute long-running tasks, programming models, serverless standards, and the importance of serverless for scientific research. While our paper is a comprehensive study on FaaS; we covered 275 research papers which are taken from the grey literature during 2016–2020. In our paper, eight application areas have been identified as mentioned earlier. We have identified and answered ten research questions that cover many aspects of the topic in detail compared to the aforementioned study.
We are in fact addressing with this paper ten important research questions about the topic, potentially making it a more complete guide to the development and use of serverless computing. Our work contributes to the analysis of the serverless paradigm in the context of similar applications and how could they better fit specific computing needs. Moreover, information about the current state of serverless platforms, tools, and frameworks has been updated for this survey. This due to the importance of the topic and its potential to change how both the industry and academia have managed the deployment of cloud applications until now. Updated information about the area could benefit future studies focused on the serverless computing paradigm as they make researchers aware of the latest resources and opportunities in the area.
Research methodology
Research questions.
In this study, a number of research questions (RQs) have been identified and answered. Each RQ addresses a particular aspect of serverless computing as follows.
RQ1. What is the number and distribution of studies published on serverless computing in the period (2016–2020)?
RQ2. Which researchers, organizations, and countries are active in serverless computing research?
RQ3. What are the differences between serverless computing and traditional cloud computing?
RQ4. What are the benefits of using serverless computing?
RQ5. What are the most used software platforms that enable serverless computing in the literature?
RQ6. What are the application areas of serverless computing in the literature?
RQ7. What are the challenges and issues of using serverless computing?
RQ8. What tools are available for serverless computing? (serverless tools)
RQ9. What are the available research approaches to analyze the migration of monolithic applications to serverless computing?
RQ10. What are the potential future directions of research on serverless computing?
Search strategy
Literature sources.
In this study, five standard online databases have been selected as sources that index the literature of software engineering and computer science. These sources are presented in Table 1 .
Search string
To find the publications relevant to this study, the following extensive search string has been applied on the database sources of literature:
(serverless OR FaaS OR “function as a service” OR “function-as-a-service”) AND (computing OR paradigm OR architecture OR model OR application OR function OR service OR platform OR programming)
To obtain the best publication list, a generic search string is created. It contains serverless cloud computing-related keywords. The string with duration (2016 - 2020) have been applied to all libraries. Because the Springer Link library covers many fields, the result of search was greater than other libraries. This because the keyword FaaS is used in many research areas for different purposes. For instance, fish as a service (FaaS) and FPGA as a fervice (FaaS). Therefore, we used Computer Science subject filter with Springer Link, ScienceDirect, and Scopus to reduce the number of incorrect papers. The results of the initial search are shown in Fig. 2 . Additionally, some inaccurate results have been obtained due to the partial similarity to FaaS, such as the federal aviation administration (FAA). The results of the initial search were 5,021 papers in total.

Results of papers selection process
After obtaining the initial list of publications, some filters have been applied to reduce the number of incorrect results based on their relation to the serverless computing and FaaS topics. Most of the papers have been analyzed based on the title and abstract. However, when we were unable to make a decision based on the title and the abstract, we read the content of the paper to ascertain whether to include or exclude. As a result, the list of papers which are related to serverless computing has been decreased to 549 papers.
After filtering the papers based on the title and abstract, we merged all the papers that were relevant to serverless cloud computing, which was 549 papers into a single dataset. Then we removed the duplicated papers based on the combination of a title, author names, publication year, and venue. Thus, the number of publications has been reduced to 489 papers.
Then, the publications have been selected based on the content of the paper and based on a set of inclusion/exclusion criteria (see the following section) that have been selected carefully. Eventually, we could obtain 254 papers that are related to serverless cloud computing. In the next step, we applied backward snowballing to increase the set of relevant papers to serverless cloud computing. In this phase, we could add 21 more papers to our list of papers. As a result, the total numbers of relevant papers become 275 papers. The list of these papers and its meta-data have been published in Zenodo website as a dataset [ 32 ].
Paper inclusion/exclusion criteria
To decide whether a publication is relevant to the scope of this research, a set of inclusion and exclusion criteria have been established and employed as follows:
Inclusion criteria:
Publications in the field of software engineering and computer science.
Publications published online from 2016 – 2020.
Publications related directly to serverless computing.
Exclusion criteria:
Publications not published in English.
Publications without accessible full text.
Publications not formally peer reviewed (e.g., gray literature).
Publications not published electronically.
Publications that are duplicates of other previous publications.
The selected publications were carefully read to answer the raised RQs. Here, a short title is used to represent each RQ. The following subsections present and discuss the results based on each RQ.
Distribution of publications (RQ1)
Publication frequency.
All the selected papers of this study were analyzed to determine their frequency and evolution. Figure 3 shows the results of this analysis. The results show that the average number of publications per year is approximately 55 papers.

Published papers per year
Serverless computing has trended a significant engagement over the past two years. This boost has been caused by industry, academia, and developers for several reasons. The first important reason is the attractive engagement opportunities that serverless offers cloud providers. Serverless nature equipped cloud providers with more convenient and efficient methods to manage and utilize idle computing resources. Another reason is that the billing is only on the basis of function execution time and resource allocation. Also, the developers are not required to be aware of the underlying infrastructure and workflows. Hence, this attracts cloud providers and businesses to migrate and support serverless alongside many directions. At the same time, researchers are paying more attention to serverless as it is becoming the future paradigm for cloud computing. Moreover, current challenges and limits in serverless computing draw attention to more academics to address the issues and enhance the currently available features. For the aforementioned reasons, developers and customers are well encouraged and satisfied to select serverless computing for developing applications and services.
Publication venue
The distribution of the selected papers in various publication venues is shown in Fig. 4 . The percentages of publications in conference papers, workshop papers, symposium papers, and journal papers are approximately 62%, 11%, 14%, and 13%, respectively. However, almost 13% of the studies have been published in journals, which indicates the immaturity of research in serverless computing [ 33 , 34 ]. It is worth mentioning that some conference papers were published as book chapters. Thus, the original venues, which are conferences, of such papers were considered.

Published papers ratio per each venue
Following the interpretation of publications, the most productive and primary journals, symposiums, conferences, and workshops venues related to serverless computing can be clarified. Due to their long names, abbreviations are used in this paper. The active journals are shown in Fig. 5 and their full names can be found in Table 2 . It can be observed from the figure that the top and vital three journals are “FGCS”, “IoT”, and “JSS”. Also, it can be noticed that the top three journals contain almost 34% of the published journal papers, while the others own approximately 66%.

Published papers vs. journal name
The active conferences are shown in Fig. 6 and their full names are presented in Table 3 . The “WOSC”, “Cloud”, “UCC”, “SoCC”, and “Middleware” are considered the most active conferences that hold approximately 28% of the published conference papers. By including other conferences with three published papers or more, then approximately 23% of the conference papers are published in annual conferences. The majority (almost 49%) of the conference papers were published at individual conferences, which are denoted as “Others” in Fig. 6 .

Published papers vs. conference name
Active researchers (RQ2)
Serverless computing is a vital research area through the contribution of several scholars. Yet, the researchers are counted active if they contributed to more than two research studies, as presented in Fig. 7 . The figure shows that the top six active researchers are “Pedro Garcáa López”, “Erwin Van Eyk”, “Alexandru Iosup”, “Marc Sánchez-Artigas”, “Sebastian Werner”, and “Wes Lloyd”. Table 4 presents the active nations, research institutions, researchers, references to the published papers, and the total number of publications.

Active researchers based on the published papers
The active nations in the number of papers are obtained from the information presented in Table 4 by extracting the institutional affiliation of the authors and co-authors. An overview of the most active nations and the total number of publications is shown in Fig. 8 . It is observable that the United States and Germany are the largest contributors to papers published on serverless computing with 104 and 39 published papers, respectively.

Active countries
Serverless computing vs. traditional cloud
computing (RQ3) There are several differences between serverless and traditional cloud computing. In the traditional cloud architecture, the server acts as a monolithic system containing all business logic. Meanwhile, the serverless architecture is modeled into smaller, event-driven, and stateless ‘triggers’ (events) and ‘actions’ (functions) [ 175 ]. Each component handles different pieces of data and runs independently [ 176 ]. Spreading business logic into smaller functions increase the development efficiency [ 77 , 177 ] and also decreases the chance of a single point of failure [ 77 ]. On the other hand, the component dependency within monolithic applications affects the availability of other services adversely.
In a serverless architecture, the developers are unable to take control of listening to the TCP socket, managing load balancers, maintenance or configuration of the server, as well as provisioning and resource allocation. Therefore, there is no need for system administrators; the developers only focus on handling client requests and paying attention to deliver valuable services [ 8 ].
Serverless computing also differs from monolithic computing as the functions have shorter life cycles.
The traditional monitoring and debugging tools that are used in monolithic applications are not included in the serverless architecture; the developers are compelled to use built-in tools for debugging and monitoring. The computing power is no longer a concern for the developers in the serverless paradigm, as it could scale horizontally almost indefinitely [ 178 , 179 ]. Meanwhile, in the client-server architecture, it usually requires dedicating two server instances; the primary instance and a second in case if the former fails. This leads to higher costs in the monolith paradigm. Serverless architecture could be more economical for unsteady load conditions while the server-based is more suitable for steady loads [ 152 ]. As serverless applications scale up and down according to the requests, thus, unlike the traditional systems, it is unnecessary to keep the sessions in the memory [ 8 ]. Hence, it is difficult to keep track across requests.
FaaS boosts the security level as cloud providers continuously update their infrastructure with the latest security patches; this also removes the security burden on developers [ 17 ]. Directly accessing the backend resources in the traditional model is considered a critical security issue. Thus, any requests from the clients and internal functions in the serverless environment must go through a distributed request-level authorization mechanism that strengthens the security level [ 8 ]. Additionally, denial of service (DoS) attacks are controlled, as it is more difficult to attack distributed servers than a single server [ 175 ]. However, some security concerns remain due to the third-party API usage [ 9 ]. Besides, there is a lack of tools to identify vulnerabilities and access control risks. Table 5 summarizes the aforementioned differences.
Benefits of serverless computing (RQ4)
Serverless computing offers numerous benefits to its users, and Table 6 presents papers that states these benefits. This section summarizes those benefits as follows:
Cost effective
Serverless applications are abstracted from server infrastructure, which results in cost-based services depending on usage [ 180 ]. For example, applications run whenever a user makes a request to a service within the application. The cloud vendors charge only for the used space, and there is no cost while their applications are in an idle state.
Scalability
Serverless reasonably solved the resource allocation problem [ 191 ]. Therefore, developers do not have to concern themselves with the application scalability, because the application will scale automatically whenever user application requests are increased. If there are numerous requests to a function within the application, the serverless providers will start servers to handle these requests.
Server-side management
In serverless computing, developers do not need to concern themselves with the server-side and its management. Serverless cloud providers take care of managing and maintaining the hardware and software required to deploy applications. In addition to that, they handle all administration operations to let developers focus on different kinds of resources such as central processing unit (CPU), memory, and storage.
Easy to deploy
Serverless applications are easy to deploy. For example, to deploy an application, developers only need to upload some functions and release a new product. The serveless will take care of deployment management and infrastructure related concerns such as server provisioning and scaling.
Decrease latency
Serverless applications are not hosted on a specific server; the code can run from any server in any location. Therefore, cloud vendors can run the application on servers near the end user’ location. This reduces latency, because end user requests do not have to travel across the Internet to access the original server.
Serverless platforms in the literature (RQ5)
The software platforms are generally implemented to deal with resources from several clouds and ensure proper running of client applications. The heterogeneous nature of the cloud providers’ infrastructure (hardware and operating systems) led to the necessity to direct the developers’ focus to the functional part, rather than the underlying infrastructure [ 199 ].
With the emergence of the first serverless platform, AWS Lambda by Amazon in 2014 [ 8 ], cloud computing has evolved to a new generation referred to as serverless computing. However, serverless was not a brand-new paradigm; it emerged after the advancements in adopting virtual machines and container technologies [ 120 ]. By 2016, other competitors, namely Google, Microsoft, and IBM followed the trend. Several commercial and open-source platforms offer serverless computing. The well-known commercial systems are AWS Lambda, Google Cloud Functions, and Azure functions. Alternately, there are several open source platforms available including IBM Cloud Functions, and Apache OpenWhisk.
There are several criteria to help developers in selecting a serverless platform: cost, performance, supported programming languages and model, deployment easiness, easiness in composing functions from different providers, security, and monitoring and debugging tools [ 184 ].
Table 7 presents the serverless platforms used in the considered papers of this study. It can be noted that “AWS Lambda”, “Apache OpenWhisk”, and “Azure Functions” are the most used platforms with 78, 23, and 11 published papers, respectively. However, it is worth mentioning that each platform has its own set of features and differs from others.
The application areas of serverless computing in the literature (RQ6)
Serverless computing can be utilized in a number of application areas as follows:
A chatbot application is developed using serverless computing, which enables interaction with users via voice or text commands. Within this application, six functionalities have been implemented, namely the Date, News, Jokes, Weather, Music Tutor, and Alarm Service. For example, a user can ask for the current date using a voice or text command. The request is routed to a required serverless action on OpenWhisk for further processing. The Date action is activated via the issued command and retrieves the current date to the user in the form of text or voice [ 44 ].
Another example is the ticketing chatbot service developed using serverless computing and natural language processing (NLP). The architecture of the system consists of three parts: (1) the node.js Webhook, which works based on hypertext transfer protocol (HTTP) POST or GET requests (2) Wit.AI, which is a NLP service (3) Ticket.com, which is a ticketing order API. For example, when a user books a flight ticket; a specific function on Webhook will be activated, which routes the user query to the Wit.AI service. Wit.AI will process the query and extract useful parameters from the request such as destination, date, and time, then send it back to Webhook. After receiving the processed query from Wit.Ai; another action will be triggered and pass the processed query to Tickt.com API to retrieve flight information such as the flight number, airline name, departure time, and ticket price from several airline companies. Finally, Webhook will provide flight information to the user [ 44 , 179 , 248 ].
Information retrieval
A search engine web-based application is developed based on serverless architecture. Search engine functionalities are implemented as Amazon lambda functions. The search engine executes all the details of retrieval processing after receiving the user query (e.g., tokenization, stop-word removal, term weighting, similarity calculation, and ranking). Then, it sends back the results to the user as documents stored in the DynamoDB database to be accessed using the web application interface [ 173 ].
File processing
Serverless computing can been utilized in file processing applications [ 119 , 249 ]. For instance, in [ 119 ] a model for highly parallel file processing applications based on serverless architecture is proposed. This model provides users with different ways to process their files.
The first method is by using the API gateway. In this method, users submit files using the HTTP request employing the API gateway to a lambda function to process the file (e.g., medical images and video files).
The second method is by uploading/reading files to the Amazon simple storage service (Amazon S3) bucket. This method provides the user with three different ways to execute a lambda function using S3 buckets: (a) by uploading a file to S3 buckets. When the file is uploaded, S3 creates an event to invoke a lambda function; (b) by copying a file from another bucket to the bucket linked with the lambda function. This will cause the trigger of an event from S3 to invoke a lambda function as in the previous manner; (c) by specifying a bucket where the files to be processed are stored. Then, for each file found, the lambda function is invoked in parallel using an S3 bucket.
The third method is by specifying the output file. By this method, the user can set a chain of lambda functions to be invoked by S3 buckets. In this case, the user defines the input/output buckets for each of the lambda functions. Thus, the output bucket can be used as an input to another lambda function [ 119 ]. Here, serverless functions can handle different types of data (stored in files) such as sensory, textual, and biological data [ 200 ]. Also, many preprocessing operations using NLP may be applied to data files before processing, such as stemming and noise removal [ 78 ].
A MATLAB simulation scenario is created to illustrate the use of the smart grid with serverless cloud computing to control and manage electrical loads (devices). In this scenario, the Simulink tool is employed for simulation. A MATLAB program is developed to indicate the start and end of the simulated grid model via a batch file. The batch file is used to upload grid model data generated by the program to Amazon S3. Afterwards, a lambda function in the serverless side will be activated to process the uploaded data, and subsequently the result will be sent back to the batch file as a response. In return, the program will read continuously the response from the batch file and interpret its content to manage the electrical switch (loads) [ 201 ].
Also, An electrical overload warning system is implemented in the smart grid, based on serverless architecture. The system uses some Amazon web services, including S3, lambda functions, simple notification service (SNS), and CloudWatch. S3 is used as a storage service in the system. Lambda functions constitute a computing service that executes the code of the application. CloudWatch is a monitoring tool that monitors AWS resources and applications. The SNS is a notification service that sends and receives notifications.
The main sections of this warning system consist of data collection, data acquisition, data analysis, data mining, conclusion verification, and conclusion publishing. In this architecture, the AWS Lambda is used in data analysis and data mining. AWS CloudWatch is used for data conclusion verification. The SNS is used to generate alarms. For instance, the data is uploaded to S3, and subsequently, a lambda function is activated for data analysis and data mining. After the lambda function execution, its log data is stored in CloudWatch logs. CloudWatch is used for conclusion verification. CloudWatch defines an alarm size to a specific value, upon which it compares the value of log data with a predefined alarm size to check the current state. Then, the CloudWatch uses SNS for publishing conclusions. If the receiving data is greater than the alarm size, an alarm signal will be triggered and send an email via SNS [ 5 ].
An automated threat detection system is introduced using serverless cloud computing and Kubernetes. Kubernetes is an open source system to automatically deploy and manage application containers [ 243 , 250 ]. The system deals with threats (e.g., software vulnerabilities and insecure configurations) automatically based on user-defined policies. The system includes a vulnerability scanner (VS), which is a thread detection component. Whenever users deploy new application containers, the containers are registered with the VS, and a scanner agent is installed. When a thread is detected by the scanner, a notification is sent to the OpenWhisk component, which activates a serverless function that takes actions to reduce the threat. OpenWhisk will invoke a Kubernetes API extension and let the security enforcement operator (SEO) handle the operation [ 35 ].
Serverless cloud computing has been employed in different networking domains[ 175 , 188 , 251 , 252 ]. In [ 188 ], a variety of networking fields including software-defined networking (SDN) which can utilize advantages of serverless computing architecture have been discussed. The SDN is a network architecture approach that enables the network to be manageable and adaptive. This architecture separates the network control plane from the forwarding functions (the data plane). This decoupling enables network switches to become a simple forwarding device, and the network control is implemented as a network application that executed on a logically centralized controller. Serverless computing can be used in the SDN controllers. These controllers can be implemented as independent functions deployed on serverless platforms. For example, when a packet arrives to the SDN forwarding device, the device will parse the packet header and forward it to the SDN controller. The functions within the SDN controller will be activated then it will determine what action to be taken with the packet. After that, it will send the information to the forwarding device. The action might be modifying the header, dropping the packet, etc.
Serverless computing has been utilized in many IoT applications, as shown in Table 8 . For example, a camera can be installed to monitor a house, after which processing images captured by the camera can be performed by some serverless functions provided by the OpenWhisk platform. When a camera detects an interesting object such as a car or a human, the camera sends its pictures to the serverless platform for further processing. To extract features, a serverless function is called to perform feature extraction and then reports its status to the users [ 232 ].
Edge computing
Serverless cloud computing and edge computing have been used to build different kinds of applications, as presented in Table 8 . For instance, the authors of [ 217 ] have implemented an autonomous mobile robot (AMR) system based on serverless computing and edge computing. The system consists of three main components: an AMR with NVIDIA Jetson TX2 module for edge computing, a serverless architecture based on AWS, and a cross-platform mobile application developed using React Native. The main idea of the system is to deliver a package to a user. For example, the user will interact with the mobile application to send a package. Once the delivery request has been received from the user, the AWS IoT can activate related lambda functions, such as position coordinate. Then, the AMR would start its mission, sending the package to the receiver’s location. Also, facial images were regularly retrieved by AWS lambda to identify the receiver’s face. Finally, the task is completed when the receiver’s identification is confirmed [ 217 ].
Serverless computing challenges and issues (RQ7)
Studying the literature reveals a number of challenges and issues posed by employing serverless computing. These challenges cover the functional and non-functional aspects of serverless computing as follows:
Cost and pricing model
Cost is a fundamental challenge; therefore, serverless computing providers should reduce the usage of resources to the minimum, while functioning in both execution and idle states. Further, the pricing model is another challenge in serverless computing compared to other cloud computing approaches. For example, the CPU bound is cheap, whereas the input/output (I/O) bound functions may be more expensive from dedicated servers. Table 9 presents papers that investigate issues on cost and pricing models in serverless cloud computing.
Serverless computing can scale to zero while there is no request for functions and services. Scaling to zero leads to a problem called cold start. A cold start occurs when serverless functions remain idle for some time, and the next time these functions are invoked, a longer start time is required. Methods and techniques to reduce the cold start problem are crucial as a result, many papers have been studied this problem, as shown in Table 9 .
Resource limits
In serverless computing, resources are required to ensure that the platform can deal with load increasing. This includes CPU usage, memory, execution time, and bandwidth [ 94 , 202 , 210 , 235 , 280 ].
Security is the most challenging issue in serverless cloud computing. One of the security issues is isolation, because functions are running on a shared platform by many users. Therefore, strong isolation is required. Another security issue is trust when it comes to process-sensitive data. The serverless applications work with many system components, which must function correctly to maintain security properties. Table 9 presents several papers associated with serverless security.
Serverless computing must ensure function scalability and elasticity. For example, when many requests are issued to a serverless application, these requests should all be served and the used serverless cloud provider should provide the required resources to process all these requests and should scale up with the number of requests [ 210 , 280 , 281 ].
Long-running
Serverless computing runs function in a limited and short execution time, while there are some tasks might require long execution time. This does not support long execution running, since these functions are stateless, which means that if the function is paused it cannot be resumed again [ 11 , 202 , 234 , 280 ].
Programming & debugging
There is currently a lack of debugging tools. Further, monitoring tools are required, since developers need to monitor the application and observe how functions are working. More advanced integrated development environments (IDEs) are needed, so developers can perform refactoring functions, such as merging or splitting functions, and reverting functions to the previous version. Moreover, logs from serverless function invocations need to be sent to the developer and provide detailed stack traces. When an error occurs, a good method is required to report details on the occurrence to the developer. The equivalent of a stack trace for serverless computing is currently not available. Table 9 shows many papers that consider programming and debugging challenges and issues.
Vendor lock-in
The FaaS paradigm separates the code from the data, which leads the functions to depend strongly on the could provider’s ecosystem for storing, obtaining, and transferring data [ 282 ]. This issue makes the customers dependent on the serverless provider for products and services, and the customers cannot easily use different vendors in the future without substantial cost. Thus, customers have to wait on the serverless provider for additional services [ 9 , 130 , 202 ].
Performance
Serverless computing has many performance challenges and issues such as scheduling and service calling overhead. For instance, scheduling means when a serverless function is activated in response to an event this function should be mapped to a specific resource (e.g., container or VM) to be run. The resource can have a significant effect on performance based on available resources, location of input data and code, load balancing, etc. Table 9 shows papers related to serverless performance.
Fault tolerance
It refers to a system that continues working and provides its services despite the failure in some components. It mostly occurs when some containers fail. To overcome this challenge, a basic retry mechanism is used [ 11 , 210 , 235 ].
Function composition
Serverless cloud vendors provide users the ability to deploy small stateless functions to the cloud to handle a specific task. However, some complex tasks require multiple functions to work with each other collaboratively to be performed. Therefore, more research needs to be done on how function composition can be used effectively and efficiently in serverless cloud computing [ 11 , 38 , 235 ].
Resource sharing
Functions in serverless cloud computing share resources to achieve inexpensive cloud computing. Sharing resources among functions and other serverless components is a challenging task. Therefore, good techniques are required to be investigated to achieve this goal [ 98 , 210 , 283 ].
A serverless application consists of many small functions. These functions work together to accomplish the application’s functionality. Therefore, integration testing for these functions is a crucial issue to make sure that the application works properly [ 9 , 84 , 284 ].
Naming and addressing system
Users deploy functions to serverless cloud computing to solve problems. These functions cannot listen to network communications. The existing serverless cloud computing frameworks do not support this feature. Instead, they use third party services such as Amazon S3 to communicate with other functions. Therefore, finding the internet protocol (IP) address of a function by other functions and services is a challenging issue in serverless cloud computing [ 98 ].
Legacy systems
Legacy systems refer to old technologies, techniques, hardware, and software systems that are still in use. It should be possible to reach these systems from serverless cloud computing. Also, these systems might be required to be transferred to cloud computing. Therefore, more work needs to be done on the migration process and how the functions can be extracted from legacy systems to be deployed as serverless cloud functions [ 84 , 119 , 120 , 210 , 280 ].
Managing hybrid cloud
In a hybrid cloud, a developer may deploy an application to different clouds (hybrid cloud). For example, if some functions of an application are on a specific serverless cloud vendor and others are hosted on other public clouds; then, managing these functions and their interactions is a challenging issue [ 84 , 210 , 280 ].
Lack of quality of service (QoS) support
Existing serverless platforms and frameworks do not provide users the control over the QoS of serverless functions [ 235 ]. Cold starts, queuing, and orchestration are the main reasons affecting the QoS in serverless computing [ 8 ].
Architecture complexity
A serverless application may consist of several functions; the number of functions increases the complexity of the architecture. Managing these functions and services related to the application also leads to a complex architecture [ 9 ].
Interactions tracking
Stateful requests are usually used by real-life applications. It means deployed systems keep track of the state of users’ interactions and store them on the server-side for further uses. However, in stateless serverless functions, it is not obvious how these functions will handle and manage the states of each user [ 210 , 280 ].
Concurrency management
Concurrency means a function can handle any number of requests whenever a function is invoked. For example, if a request has been made to a serverless function, the function will process that request. However, if another request has been made to that function and the function is still processing the previous request, then the serverless should provide another instance of that function to serve the new request [ 210 , 280 ].
Support for heterogeneous hardware
Existing serverless platforms may not support some specialized hardware such as graphics processing unit (GPU) and field programmable gate arrays (FPGAs). This is a challenging issue for vendors to provide support for heterogeneous hardware [ 210 , 280 ].
Tools available for serverless computing (RQ8)
Nowadays, various providers strive to facilitate the adjustable use and allocation of machine resources on the cloud [ 9 ]. Likewise, plenty of supportive tools and services are aiding developers to more efficiently manage and deploy applications using serverless computing. Serverless computing is auto-scalable, reliable, and easily accessible [ 203 ]; for these reasons, big cloud providers such as Amazon, Microsoft, Google, IBM have realized the importance of offering frameworks, IDEs, software development kits (SDKs), function development kits (FDK), migrating mechanisms, logs, and monitoring tools to enhance and simplify the development, testing, deployment, and monitoring of serverless applications [ 17 ]. For instance, Amazon offers Cloud9 IDE for local deploying and testing [ 205 ].
Apart from the cloud providers’ specific tools, plenty of third-party tools exist for the developers. With the concept of these tools, developers can build and deploy applications on multi-cloud providers. Developers are also able to control platforms and resources by programming. The advantages of this are linking the applications with auto-scaling controllers and including advanced self-mechanisms into the code to automatically configure, secure, optimize, and recover the cloud applications. The core advantage of this feature is the acceleration in applying changes to the application environment [ 272 ].
There are several tools available to model serverless applications, which are based on deployment models as either imperative or declarative. The imperative model defines the execution steps to obtain a specific deployment task. While the declarative model describes the structure of a desired application deployment. However, to fully benefit from employing a serverless architecture, cloud providers should address issues that have arisen with the use of a serverless paradigm. For instance, debugging tools are unable to track and identify the exact reason behind errors [ 44 ], as most of them are limited to what cloud providers offer [ 179 ]. Although many powerful tools have been mentioned in this study and can be used in serverless computing in real scenarios, there is still a great opportunity to develop further tools and services.
Migration of monolithic applications to serverless computing (RQ9)
The nature of most existing applications is monolithic. Monolithic applications have several drawbacks; they are characterized by continuous growth in complexity and size over time.
The bigger size of the monolithic applications leads to slower startup time. Moreover, novice developers face difficulties in digesting the traditional programming paradigm. Economically, monolithic systems take more effort to be developed and debugged. Furthermore, integrating the latest technological development into monolithic systems is a tough and expensive process. Generally, monolithic applications are designed to be tightly coupled – the entire application will be unable to run or compile if one component is missing or fails [ 128 ]. It is also difficult to scale the application when multiple components have limited resources.
Another drawback is that updating any component will require redeployment of the entire project. The migration process to serverless computing involves transferring the legacy application code to serverless functions. This process could be more efficient and functional in applications with less size [ 76 ].
The key challenging aspect of migration is about extracting the serverless computing from the monolithic systems. There are several approaches to accomplish this task, one of them is Lift and shift [ 205 ]. This technique transfers the whole infrastructure to the cloud, however, this method also brings the already existing problems within the source to the destination. In [ 205 ] the authors proposed toLambda to automatically refactor, test, and deploy the monolithic applications (Java) into microservices (AWS Lambda Node.js). While rebuilding the legacy application from scratch is recommended for applications that no longer depend on the existing cloud services [ 130 ].
However, not all applications are suitable for migration to serverless computing [ 76 , 128 ]; therefore, the first important aspect to be considered before rebuilding the applications is whether it would save money [ 188 ]. For such cases, newly desired features could be implemented and added via serverless computing as an extension to the current systems [ 128 ].
The other approach is to refactor the entire legacy code into FaaS services. During the migration phase, it is crucial to address the coupling of the systems not only in the application logic but also in the databases, as more functions will call the same database. However, migrating the server-side while keeping the user interface could lead to problems. Moreover, the client cannot obtain integrated data by a single request. As the functions are decoupled into smaller entities, the server is unable to aggregate data from different entities. Thus, it is the client’s responsibility to call the necessary entities to achieve this task [ 76 ].
Future directions of research (RQ10)
As the evolution of serverless computing is relatively new, there are several research paths available to be focused on as follows:
Function startup
One of the major research opportunities is overcoming the cold start problem without affecting the primary feature of serverless which is scaling to zero [ 160 , 188 ]. The first call of functions needs initializing the required libraries, which will cause a cold start. To bypass this, the computing resources will be warm for a certain time. Hence, upcoming requests will be handled faster. This could be performed via enhancing scheduling policies and developing more accurate function performance measurements [ 86 ]. Serverless providers follow their approaches to keep the functions in the warm pool. However, most of them are based on the number of requests for a certain time. Thus, if a function is not called frequently, it will suffer again from the cold start.
Very few studies such as [ 272 ] suggested a periodic event scheduler for Kotless (a serverless framework for Kotlin) which will trigger a list of warm functions every few minutes. The authors of the study claimed that this will reduce the cold start without bringing extra costs. While in [ 233 ] argues that pre-warming methods are unnecessarily using resources with idle containers. The researchers are still working to avoid cold start by reducing high delayed function startups via optimizing compute resources [ 11 ].
Recycling and rebalancing minutes and hours of idle runtime is an expensive process for cloud providers. Therefore, reducing the cold start penalties will help cloud providers in the first place and hence customers. The authors in [ 202 ] proposed FaaStest an autonomous approach based on machine learning to capture the function call behavior and then dynamically select the optimal ones. This technique could reduce the cold start by 90%. They proposed a strategy to predict functions invoking time and warming the function using fine-grained regression method [ 285 ]. However, overcoming the issue of function startups is still considered as a research direction to be more investigated.
Keeping a guaranteed QoS level in the software level agreement (SLA) that describes the lower service level offered by the service providers [ 166 ] is a major obstacle for cloud providers to offer optimal performance metrics [ 167 , 207 ]. However, serverless frameworks should consider the objectives of both providers and users [ 242 ]; customers and developers have none or little QoS support over the functions [ 236 ]. In addition, the auto-scaling feature lacks QoS guarantees. This lack of QoS affects the performance of serverless applications. Increasing response time leads to decreasing the QoS level [ 207 ]. It also raises the cost of the service [ 236 ]. Therefore, achieving an ideal resource allocation management is a complicated and challenging task as several objectives should be fulfilled together [ 209 ]. Hence, providing more efficient QoS management of functions by the auto-scaling is essential to be considered without degrading the fault-tolerance features and increasing the cost.
Pricing is crucial for both customers and cloud providers. However, there is a shortage in pricing models, as there is an imbalance in needs between serverless providers, developers, and service end-users [ 236 ]. The pricing scheme for most cloud providers is based on the number of functions’ requests and execution time-the quantity of consumed resources [ 123 , 200 ]. Currently, FaaS is less expensive when functions are bound to I/O than CPU. Moreover, services that dynamically adjust resource consumption are unable to predict the optical computing technology. It is crucial to implement solutions that offer cost-effective computing resources. FaStest reduced the cost by 50% via learning the behavioral pattern of functions using machine learning [ 202 ]. Price estimation has a great impact on selecting the most optimal provider. Therefore there should be more researches on developing tools to predict the pricing in advance.
Since the serverless emergence, researchers are working on the open question of how to decompose legacy systems into FaaS without degrading performance [ 208 ]. Several works have been done on migrating to FaaS [ 76 , 130 , 286 ]. The currently available automated tools for migrating legacy code into FaaS are not fully practical due to the remaining manual work that needs to be done [ 17 ]. Therefore, finding optimal automatic migration solutions for existing legacy systems is an interesting research direction [ 130 ]. Moreover, research on tools for checking whether a legacy system will fit the serverless paradigm is a crucial line. Also, developing and enhancing automatic and semi-automatic analysis strategies based on artificial intelligence could be another future research field.
Debugging, testing, and benchmarking
The available tools for testing, debugging, and deployment are immature, this prevents some developers from entering the serverless environment. The shortage of tools in FaaS is a core problem, particularly the testing tools [ 17 ]. Moreover, most FaaS environments lack powerful local emulation platforms for testing. Therefore, developers are mostly depending on the server-side, which is expensive. Developers need to be ensured about the adequate testing tools before diving into the serverless world. A challenging aspect in benchmarking is the lack of information due to the heterogeneity of the cloud provider data center: hardware, software, and configurations [ 287 ]. Additionally, benchmarking FaaS platforms should take advantage of analyzing the cloud services, which lacks limited accessible measurements and hidden modification of services over time [ 55 ]. Thus, it is essential to have transparent, fair, and standardized benchmarking tools available for developers.
Threats to validity
Several threats might impact the validity of the literature mapping studies. In this paper, popular instructions and guidelines were taken into account to avoid threats to validity as follows:
Coverage of research questions: All up-to-date research aspects of serverless computing might not be included in this study. To overcome this threat, the brainstorming was conducted by all the authors in determining the most current research questions in the area.
Coverage of related papers: The process of obtaining all the related studies in serverless computing cannot be secured. In this study, various literature databases were employed; moreover, the method based on different terms and synonymous is followed by all the authors in determining the related questions.
Paper inclusion/exclusion criteria: The individual bias and interpretation could affect the implementation of the criteria. Therefore, to solve this problem, the agreements of all authors were considered in excluding or including a paper.
Accuracy of data extraction: The individual experience effects extracting the data, therefore online meetings were conducted after the data extraction process by each author. During the meetings, the outcomes from each author were compared with other findings to determine the differences and reach a final consensus.
Reproducibility of the study: Whether other researchers could obtain similar outcomes of this study is another threat. Thus, to address this, the research methodology contains the well-explained steps and actions conducted in this paper (as shown in “ Research methodology ” section).
Conclusions
The contributions of the work presented in this paper are threefold: (a) a methodical review of related literature on the topic of serverless computing, to address the issue of the lack of compiling information on the state-of-the-art of the field; (b) a comparison of the platforms and tools used in serverless computing; (c) an extensive analysis of the differences, benefits, and issues related to serverless computing, to provide a more complete understanding of the topic. Given the fast evolution and growing interest in the field, this survey focused on gathering the most outstanding trends and outcomes of serverless computing, as described by recent researchers. This survey could significantly reduce ambiguity and the entry barrier for novice developers to adapt to the serverless environment. Furthermore, the findings presented in this study could be of great value for future researchers interested in further investigating serverless computing. Finally, it is worth mentioning that the interest that both commercial and academic efforts fueled into studying, developing, and implementing serverless tools in forthcoming years could help maximize the potential that serverless computing could bring to the IT community.
Availability of data and materials
Not applicable.
Großmann M, Ioannidis C, Le DT (2019) Applicability of serverless computing in fog computing environments for iot scenarios In: Proceedings of the 12th IEEE/ACM International Conference on Utility and Cloud Computing Companion (UCC ‘19 Companion), 29–34.. Association for Computing Machinery, New York. https://doi.org/10.1145/3368235.3368834 .
Google Scholar
Boza EF, Abad CL, Villavicencio M, Quimba S, Plaza JA (2017) Reserved, on demand or serverless: Model-based simulations for cloud budget planning In: 2017 IEEE Second Ecuador Technical Chapters Meeting (ETCM), 1–6. https://doi.org/10.1109/ETCM.2017.8247460 .
Villamizar M, Garcés O, Ochoa L, Castro H, Salamanca L, Verano M, Casallas R, Gil S, Valencia C, Zambrano A, Lang M (2017) Cost comparison of running web applications in the cloud using monolithic, microservice, and aws lambda architectures. SOCA 11(2):233–247. https://doi.org/10.1007/s11761-017-0208-y .
Article Google Scholar
Jonas E, Schleier-Smith J, Sreekanti V, Tsai C-C, Khandelwal A, Pu Q, Shankar V, Carreira J, Krauth K, Yadwadkar N, Gonzalez JE, Popa RA, Stoica I, Patterson DA (2019) Cloud Programming Simplified: A Berkeley View on Serverless Computing. http://arxiv.org/abs/1902.03383. Accessed 6 Jan 2021.
Geng X, Ma Q, Pei Y, Xu Z, Zeng W, Zou J (2018) Research on early warning system of power network overloading under serverless architecture In: 2018 2nd IEEE Conference on Energy Internet and Energy System Integration (EI2), 1–6. https://doi.org/10.1109/EI2.2018.8582355 .
Kulkarni SG, Liu G, Ramakrishnan KK, Wood T (2019) Living on the edge: Serverless computing and the cost of failure resiliency In: 2019 IEEE International Symposium on Local and Metropolitan Area Networks (LANMAN), 1–6. https://doi.org/10.1109/LANMAN.2019.8846970 .
Baldini I, Castro P, Chang K, Cheng P, Fink S, Ishakian V, Mitchell N, Muthusamy V, Rabbah R, Slominski A, Suter P (2017) Serverless Computing: Current Trends and Open Problems In: Research Advances in Cloud Computing, 1–20.. Springer, Singapore. https://doi.org/10.1007/978-981-10-5026-8_1 .
Adzic G, Chatley R (2017) Serverless computing: Economic and architectural impact In: Proceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering (ESEC/FSE 2017), 884–889.. Association for Computing Machinery, New York. https://doi.org/10.1145/3106237.3117767 .
Chapter Google Scholar
Jambunathan B, Yoganathan K (2018) Architecture decision on using microservices or serverless functions with containers In: 2018 International Conference on Current Trends Towards Converging Technologies (ICCTCT), 1–7. https://doi.org/10.1109/ICCTCT.2018.8551035 .
Wolski R, Krintz C, Bakir F, George G, Lin W-T (2019) Cspot: Portable, multi-scale functions-as-a-service for iot In: Proceedings of the 4th ACM/IEEE Symposium on Edge Computing (SEC ‘19), 236–249.. Association for Computing Machinery, New York. https://doi.org/10.1145/3318216.3363314 .
Yussupov V, Breitenbücher U, Leymann F, Wurster M (2019) A systematic mapping study on engineering function-as-a-service platforms and tools In: Proceedings of the 12th IEEE/ACM International Conference on Utility and Cloud Computing (UCC’19), 229–240.. Association for Computing Machinery, New York. https://doi.org/10.1145/3344341.3368803 .
Brenner S, Kapitza R (2019) Trust more, serverless In: Proceedings of the 12th ACM International Conference on Systems and Storage (SYSTOR ‘19), 33–43.. Association for Computing Machinery, New York. https://doi.org/10.1145/3319647.3325825 .
Kuhlenkamp J, Werner S (2018) Benchmarking faas platforms: Call for community participation In: 2018 IEEE/ACM International Conference on Utility and Cloud Computing Companion (UCC Companion), 189–194. https://doi.org/10.1109/UCC-Companion.2018.00055 .
Somma G, Ayimba C, Casari P, Romano SP, Mancuso V (2020) When less is more: Core-restricted container provisioning for serverless computing In: IEEE INFOCOM 2020 - IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), 1153–1159. https://doi.org/10.1109/INFOCOMWKSHPS50562.2020.9162876 .
Sewak M, Singh S (2018) Winning in the era of serverless computing and function as a service In: 2018 3rd International Conference for Convergence in Technology (I2CT), 1–5. https://doi.org/10.1109/I2CT.2018.8529465 .
van Eyk E, Toader L, Talluri S, Versluis L, Ută̧ A, Iosup A (2018) Serverless is more: From paas to present cloud computing. IEEE Internet Comput 22(5):8–17. https://doi.org/10.1109/MIC.2018.053681358 .
Leitner P, Wittern E, Spillner J, Hummer W (2019) A mixed-method empirical study of function-as-a-service software development in industrial practice. J Syst Softw 149:340–359. https://doi.org/10.1016/j.jss.2018.12.013 .
Feng L, Kudva P, Da Silva D, Hu J (2018) Exploring serverless computing for neural network training In: 2018 IEEE 11th International Conference on Cloud Computing (CLOUD), 334–341. https://doi.org/10.1109/CLOUD.2018.00049 .
Ao L, Izhikevich L, Voelker GM, Porter G (2018) Sprocket: A serverless video processing framework In: Proceedings of the ACM Symposium on Cloud Computing (SoCC ‘18), 263–274.. Association for Computing Machinery, New York. https://doi.org/10.1145/3267809.3267815 .
Werner S, Kuhlenkamp J, Klems M, Müller J, Tai S (2018) Serverless big data processing using matrix multiplication as example In: 2018 IEEE International Conference on Big Data (Big Data), 358–365. https://doi.org/10.1109/BigData.2018.8622362 .
Al-Ali Z, Goodarzy S, Hunter E, Ha S, Han R, Keller E, Rozner E (2018) Making serverless computing more serverless In: 2018 IEEE 11th International Conference on Cloud Computing (CLOUD), 456–459. https://doi.org/10.1109/CLOUD.2018.00064 .
Pérez A, Risco S, Naranjo DM, Caballer M, Moltó G (2019) On-premises serverless computing for event-driven data processing applications In: 2019 IEEE 12th International Conference on Cloud Computing (CLOUD), 414–421. https://doi.org/10.1109/CLOUD.2019.00073 .
Glikson A, Nastic S, Dustdar S (2017) Deviceless edge computing: Extending serverless computing to the edge of the network In: Proceedings of the 10th ACM International Systems and Storage Conference (SYSTOR ‘17).. Association for Computing Machinery, New York. https://doi.org/10.1145/3078468.3078497 .
Al-Ameen M, Spillner J (2019) A systematic and open exploration of faas research In: Proceedings of the European Symposium on Serverless Computing and Applications (CEUR Workshop Proceedings ; 2330), 30–35.. CEUR-WS, Zurich. https://doi.org/10.21256/zhaw-3271 .
Alqaryouti O, Siyam N (2018) Serverless computing and scheduling tasks on cloud: A review. Am Sci Res J Eng Technol Sci (ASRJETS) 40(1):235–247.
Taibi D, El Ioini N, Pahl C, Niederkofler J (2020) Patterns for Serverless Functions (Function-as-a-Service): A Multivocal Literature Review In: Proceedings of the 10th International Conference on Cloud Computing and Services Science - Volume 1: CLOSER, 181–192. https://doi.org/10.5220/0009578501810192 .
Hellerstein JM, Faleiro J, Gonzalez JE, Schleier-Smith J, Sreekanti V, Tumanov A, Wu C (2018) Serverless Computing: One Step Forward, Two Steps Back. http://arxiv.org/abs/1812.03651. Accessed 4 Oct 2021.
Rajan AP (2020) A review on serverless architectures - function as a service (faas) in cloud computing. Telecommun Comput Electron Control 18(1):530–537. https://doi.org/10.12928/telkomnika.v18i1.12169 .
Sadaqat M, Colomo-Palacios R, Knudsen LES (2018) Serverless Computing: A Multivocal Literature Review. NOKOBIT - Norsk Konferanse for Organisasjoners Bruk Av Informasjonsteknologi 26(1):1–13.
Scheuner J, Leitner P (2020) Function-as-a-service performance evaluation: A multivocal literature review. J Syst Softw 170:110708. https://doi.org/10.1016/j.jss.2020.110708 .
Fox GC, Ishakian V, Muthusamy V, Slominski A (2017) Status of Serverless Computing and Function-as-a-Service(FaaS) in Industry and Research. arXiv e-prints:1708–08028. http://arxiv.org/abs/1708.08028. Accessed 6 Jan 2021.
Hassan HB, Barakat SA, Sarhan QI (2021) Serverless Literature Dataset. Zenodo. https://doi.org/10.5281/zenodo.4660553 .
Pedreira O, García F, Brisaboa N, Piattini M (2015) Gamification in software engineering - a systematic mapping. Inf Softw Technol 57:157–168.
Lopez-herrejon RE, Linsbauer L, Egyed A (2015) A systematic mapping study of search-based software engineering for software product lines. Inf Softw Technol 61:33–51.
Bila N, Dettori P, Kanso A, Watanabe Y, Youssef A (2017) Leveraging the serverless architecture for securing linux containers In: 2017 IEEE 37th International Conference on Distributed Computing Systems Workshops (ICDCSW), 401–404. https://doi.org/10.1109/ICDCSW.2017.66 .
Chang KS, Fink SJ (2017) Visualizing serverless cloud application logs for program understanding In: 2017 IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC), 261–265. https://doi.org/10.1109/VLHCC.2017.8103476 .
Ishakian V, Muthusamy V, Slominski A (2018) Serving deep learning models in a serverless platform In: 2018 IEEE International Conference on Cloud Engineering (IC2E), 257–262. https://doi.org/10.1109/IC2E.2018.00052 .
Baldini I, Cheng P, Fink SJ, Mitchell N, Muthusamy V, Rabbah R, Suter P, Tardieu O (2017) The serverless trilemma: Function composition for serverless computing In: Proceedings of the 2017 ACM SIGPLAN International Symposium on New Ideas, New Paradigms, and Reflections on Programming and Software (Onward! 2017), 89–103.. Association for Computing Machinery, New York. https://doi.org/10.1145/3133850.3133855 .
Kanso A, Youssef A (2017) Serverless: Beyond the cloud In: Proceedings of the 2nd International Workshop on Serverless Computing (WoSC ‘17), 6–10.. Association for Computing Machinery, New York. https://doi.org/10.1145/3154847.3154854 .
Koller R, Williams D (2017) Will serverless end the dominance of linux in the cloud? In: Proceedings of the 16th Workshop on Hot Topics in Operating Systems (HotOS ‘17), 169–173.. Association for Computing Machinery, New York. https://doi.org/10.1145/3102980.3103008 .
Mukhi NK, Prabhu S, Slawson B (2017) Using a serverless framework for implementing a cognitive tutor: Experiences and issues In: Proceedings of the 2nd International Workshop on Serverless Computing (WoSC ‘17), 11–15.. Association for Computing Machinery, New York. https://doi.org/10.1145/3154847.3154852 .
Nadgowda S, Bila N, Isci C (2017) The less server architecture for cloud functions In: Proceedings of the 2nd International Workshop on Serverless Computing (WoSC ‘17), 22–27.. Association for Computing Machinery, New York. https://doi.org/10.1145/3154847.3154850 .
Klimovic A, Wang Y, Stuedi P, Trivedi A, Pfefferle J, Kozyrakis C (2018) Pocket: Elastic ephemeral storage for serverless analytics In: Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation (OSDI’18), 427–444.. USENIX Association, USA.
Yan M, Castro P, Cheng P, Ishakian V (2016) Building a chatbot with serverless computing In: Proceedings of the 1st International Workshop on Mashups of Things and APIs (MOTA ‘16), 1–4.. Association for Computing Machinery, New York. https://doi.org/10.1145/3007203.3007217 .
Barcelona-Pons D, García-López P, Ruiz A, Gómez-Gómez A, París G, Sánchez-Artigas M (2019) Faas orchestration of parallel workloads In: Proceedings of the 5th International Workshop on Serverless Computing (WOSC ‘19), 25–30.. Association for Computing Machinery, New York. https://doi.org/10.1145/3366623.3368137 .
Barcelona-Pons D, Sánchez-Artigas M, París G, Sutra P, García-López P (2019) On the faas track: Building stateful distributed applications with serverless architectures In: Proceedings of the 20th International Middleware Conference (Middleware ‘19), 41–54.. Association for Computing Machinery, New York. https://doi.org/10.1145/3361525.3361535 .
Kaviani N, Kalinin D, Maximilien M (2019) Towards serverless as commodity: A case of knative In: Proceedings of the 5th International Workshop on Serverless Computing (WOSC ‘19), 13–18.. Association for Computing Machinery, New York. https://doi.org/10.1145/3366623.3368135 .
Byrne A, Nadgowda S, Coskun AK (2020) Ace: Just-in-time serverless software component discovery through approximate concrete execution In: Proceedings of the 2020 Sixth International Workshop on Serverless Computing (WoSC’20), 37–42.. Association for Computing Machinery, New York. https://doi.org/10.1145/3429880.3430098 .
Sánchez-Artigas M, Eizaguirre GT, Vernik G, Stuart L, García-López P (2020) Primula: A Practical Shuffle/Sort Operator for Serverless Computing. Association for Computing Machinery, New York.
Book Google Scholar
Parás G, Garcáa-López P, Sánchez-Artigas M (2020) Serverless elastic exploration of unbalanced algorithms In: 2020 IEEE 13th International Conference on Cloud Computing (CLOUD), 149–157. https://doi.org/10.1109/CLOUD49709.2020.00033 .
López PG, Arjona A, Sampé J, Slominski A, Villard L (2020) Triggerflow: Trigger-based orchestration of serverless workflows In: Proceedings of the 14th ACM International Conference on Distributed and Event-Based Systems (DEBS ’20), 3–14.. Association for Computing Machinery, New York. https://doi.org/10.1145/3401025.3401731 .
Carver B, Zhang J, Wang A, Anwar A, Wu P, Cheng Y (2020) Wukong: A scalable and locality-enhanced framework for serverless parallel computing In: Proceedings of the 11th ACM Symposium on Cloud Computing (SoCC ’20), 1–15.. Association for Computing Machinery, New York. https://doi.org/10.1145/3419111.3421286 .
Klimovic A, Wang Y, Kozyrakis C, Stuedi P, Pfefferle J, Trivedi A (2018) Understanding ephemeral storage for serverless analytics In: Proceedings of the 2018 USENIX Conference on Usenix Annual Technical Conference (USENIX ATC ’18), 789–794.. USENIX Association, USA.
Wang A, Zhang J, Ma X, Anwar A, Rupprecht L, Skourtis D, Tarasov V, Yan F, Cheng Y (2020) Infinicache: Exploiting ephemeral serverless functions to build a cost-effective memory cache In: 18th USENIX Conference on File and Storage Technologies (FAST 20), 267–281.. USENIX Association, Santa Clara.
Kuhlenkamp J, Werner S, Borges MC, El Tal K, Tai S (2019) An evaluation of faas platforms as a foundation for serverless big data processing In: Proceedings of the 12th IEEE/ACM International Conference on Utility and Cloud Computing (UCC’19), 1–9.. Association for Computing Machinery, New York. https://doi.org/10.1145/3344341.3368796 .
Werner S, Girke R, Kuhlenkamp J (2020) An evaluation of serverless data processing frameworks In: Proceedings of the 2020 Sixth International Workshop on Serverless Computing (WoSC’20), 19–24.. Association for Computing Machinery, New York. https://doi.org/10.1145/3429880.3430095 .
Kuhlenkamp J, Werner S, Borges MC, Ernst D, Wenzel D (2020) Benchmarking elasticity of faas platforms as a foundation for objective-driven design of serverless applications In: Proceedings of the 35th Annual ACM Symposium on Applied Computing (SAC ’20), 1576–1585.. Association for Computing Machinery, New York. https://doi.org/10.1145/3341105.3373948 .
Werner S, Kuhlenkamp J, Pallas F, Anders N, Mucaj N, Tsaplina O, Schmidt C, Yildirim K (2020) Diminuendo! tactics in support of faas migrations. In: Paasivaara M Kruchten P (eds)Agile Processes in Software Engineering and Extreme Programming – Workshops, 125–132.. Springer, Cham.
Kuhlenkamp J, Werner S, Tai S (2020) The ifs and buts of less is more: A serverless computing reality check In: 2020 IEEE International Conference on Cloud Engineering (IC2E), 154–161. https://doi.org/10.1109/IC2E48712.2020.00023 .
Pfandzelter T, Bermbach D (2020) tinyfaas: A lightweight faas platform for edge environments In: 2020 IEEE International Conference on Fog Computing (ICFC), 17–24. https://doi.org/10.1109/ICFC49376.2020.00011 .
Bermbach D, Karakaya A-S, Buchholz S (2020) Using application knowledge to reduce cold starts in faas services In: Proceedings of the 35th Annual ACM Symposium on Applied Computing (SAC ’20), 134–143.. Association for Computing Machinery, New York. https://doi.org/10.1145/3341105.3373909 .
Bermbach D, Maghsudi S, Hasenburg J, Pfandzelter T (2020) Towards auction-based function placement in serverless fog platforms In: 2020 IEEE International Conference on Fog Computing (ICFC), 25–31. https://doi.org/10.1109/ICFC49376.2020.00012 .
Garcia Lopez P, Sanchez-Artigas M, Paris G, Barcelona Pons D, Ruiz Ollobarren A, Arroyo Pinto D2018. Comparison of faas orchestration systems. https://doi.org/10.1109/ucc-companion.2018.00049 .
Sampé J, Sánchez-Artigas M, García-López P, París G (2017) Data-driven serverless functions for object storage In: Proceedings of the 18th ACM/IFIP/USENIX Middleware Conference (Middleware ‘17), 121–133.. Association for Computing Machinery, New York. https://doi.org/10.1145/3135974.3135980 .
Sampé J, Vernik G, Sánchez-Artigas M, García-López P (2018) Serverless data analytics in the ibm cloud In: Proceedings of the 19th International Middleware Conference Industry (Middleware ‘18), 1–8.. Association for Computing Machinery, New York. https://doi.org/10.1145/3284028.3284029 .
Mirabelli ME, García-López P, Vernik G (2020) Bringing scaling transparency to proteomics applications with serverless computing In: Proceedings of the 2020 Sixth International Workshop on Serverless Computing (WoSC’20), 55–60.. Association for Computing Machinery, New York. https://doi.org/10.1145/3429880.3430101 .
Carreira J, Fonseca P, Tumanov A, Zhang A, Katz R (2019) Cirrus: A serverless framework for end-to-end ml workflows In: Proceedings of the ACM Symposium on Cloud Computing (SoCC ‘19), 13–24.. Association for Computing Machinery, New York. https://doi.org/10.1145/3357223.3362711 .
Sreekanti V, Wu C, Chhatrapati S, Gonzalez JE, Hellerstein JM, Faleiro JM (2020) A fault-tolerance shim for serverless computing In: Proceedings of the Fifteenth European Conference on Computer Systems (EuroSys ’20).. Association for Computing Machinery, New York. https://doi.org/10.1145/3342195.3387535 .
Ichnowski J, Lee W, Murta V, Paradis S, Alterovitz R, Gonzalez JE, Stoica I, Goldberg K (2020) Fog robotics algorithms for distributed motion planning using lambda serverless computing In: 2020 IEEE International Conference on Robotics and Automation (ICRA), 4232–4238. https://doi.org/10.1109/ICRA40945.2020.9196651 .
Zhang W, Fang V, Panda A, Shenker S (2020) Kappa: A programming framework for serverless computing In: Proceedings of the 11th ACM Symposium on Cloud Computing (SoCC ’20), 328–343.. Association for Computing Machinery, New York. https://doi.org/10.1145/3419111.3421277 .
Shankar V, Krauth K, Vodrahalli K, Pu Q, Recht B, Stoica I, Ragan-Kelley J, Jonas E, Venkataraman S (2020) Serverless linear algebra In: Proceedings of the 11th ACM Symposium on Cloud Computing (SoCC ’20), 281–295.. Association for Computing Machinery, New York. https://doi.org/10.1145/3419111.3421287 .
Gupta V, Carrano D, Yang Y, Shankar V, Courtade T, Ramchandran K (2020) Serverless straggler mitigation using error-correcting codes In: 2020 IEEE 40th International Conference on Distributed Computing Systems (ICDCS), 135–145. https://doi.org/10.1109/ICDCS47774.2020.00019 .
Wu C, Sreekanti V, Hellerstein JM (2020) Transactional causal consistency for serverless computing In: Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data (SIGMOD ’20), 83–97.. Association for Computing Machinery, New York. https://doi.org/10.1145/3318464.3389710 .
Pu Q, Venkataraman S, Stoica I (2019) Shuffling, fast and slow: Scalable analytics on serverless infrastructure In: Proceedings of the 16th USENIX Conference on Networked Systems Design and Implementation (NSDI’19), 193–206.. USENIX Association, USA.
Lloyd W, Ramesh S, Chinthalapati S, Ly L, Pallickara S (2018) Serverless computing: An investigation of factors influencing microservice performance In: 2018 IEEE International Conference on Cloud Engineering (IC2E), 159–169. https://doi.org/10.1109/IC2E.2018.00039 .
Lloyd W, Vu M, Zhang B, David O, Leavesley G (2018) Improving application migration to serverless computing platforms: Latency mitigation with keep-alive workloads In: 2018 IEEE/ACM International Conference on Utility and Cloud Computing Companion (UCC Companion), 195–200. https://doi.org/10.1109/UCC-Companion.2018.00056 .
Al-Masri E, Diabate I, Jain R, Lam MHL, Nathala SR (2018) A serverless iot architecture for smart waste management systems In: 2018 IEEE International Conference on Industrial Internet (ICII), 179–180. https://doi.org/10.1109/ICII.2018.00034 .
Fotouhi M, Chen D, Lloyd WJ (2019) Function-as-a-service application service composition: Implications for a natural language processing application In: Proceedings of the 5th International Workshop on Serverless Computing (WOSC ‘19), 49–54.. Association for Computing Machinery, New York. https://doi.org/10.1145/3366623.3368141 .
Niu X, Kumanov D, Hung L-H, Lloyd W, Yeung KY (2019) Leveraging serverless computing to improve performance for sequence comparison In: Proceedings of the 10th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics (BCB ‘19), 683–687.. Association for Computing Machinery, New York. https://doi.org/10.1145/3307339.3343465 .
Cordingly R, Yu H, Hoang V, Perez D, Foster D, Sadeghi Z, Hatchett R, Lloyd WJ (2020) Implications of programming language selection for serverless data processing pipelines In: 2020 IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), 704–711. https://doi.org/10.1109/DASC-PICom-CBDCom-CyberSciTech49142.2020.00120 .
Cordingly R, Shu W, Lloyd WJ (2020) Predicting performance and cost of serverless computing functions with saaf In: 2020 IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), 640–649. https://doi.org/10.1109/DASC-PICom-CBDCom-CyberSciTech49142.2020.00111 .
Cordingly R, Yu H, Hoang V, Sadeghi Z, Foster D, Perez D, Hatchett R, Lloyd W (2020) The serverless application analytics framework: Enabling design trade-off evaluation for serverless software In: Proceedings of the 2020 Sixth International Workshop on Serverless Computing (WoSC’20), 67–72.. Association for Computing Machinery, New York. https://doi.org/10.1145/3429880.3430103 .
Toader L, Uta A, Musaafir A, Iosup A (2019) Graphless: Toward serverless graph processing In: 2019 18th International Symposium on Parallel and Distributed Computing (ISPDC), 66–73. https://doi.org/10.1109/ISPDC.2019.00012 .
van Eyk E, Iosup A, Seif S, Thömmes M (2017) The spec cloud group’s research vision on faas and serverless architectures In: Proceedings of the 2nd International Workshop on Serverless Computing (WoSC ‘17), 1–4.. Association for Computing Machinery, New York. https://doi.org/10.1145/3154847.3154848 .
van Eyk E, Iosup A, Abad CL, Grohmann J, Eismann S (2018) A spec rg cloud group’s vision on the performance challenges of faas cloud architectures In: Companion of the 2018 ACM/SPEC International Conference on Performance Engineering (ICPE ‘18), 21–24.. Association for Computing Machinery, New York. https://doi.org/10.1145/3185768.3186308 .
van Eyk E, Grohmann J, Eismann S, Bauer A, Versluis L, Toader L, Schmitt N, Herbst N, Abad CL, Iosup A (2019) The spec-rg reference architecture for faas: From microservices and containers to serverless platforms. IEEE Internet Comput 23(6):7–18. https://doi.org/10.1109/MIC.2019.2952061 .
van Eyk E, Scheuner J, Eismann S, Abad CL, Iosup A (2020) Beyond microbenchmarks: The spec-rg vision for a comprehensive serverless benchmark In: Companion of the ACM/SPEC International Conference on Performance Engineering (ICPE ’20), 26–31.. Association for Computing Machinery, New York. https://doi.org/10.1145/3375555.3384381 .
Eismann S, Grohmann J, van Eyk E, Herbst N, Kounev S (2020) Predicting the costs of serverless workflows In: Proceedings of the ACM/SPEC International Conference on Performance Engineering (ICPE ’20), 265–276.. Association for Computing Machinery, New York. https://doi.org/10.1145/3358960.3379133 .
van Eyk E, Iosup A (2018) Addressing performance challenges in serverless computing In: ICT. OPEN.
Hendrickson S, Sturdevant S, Harter T, Venkataramani V, Arpaci-Dusseau AC, Arpaci-Dusseau RH (2016) Serverless computation with openlambda In: 8th USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 16), 1–7.. USENIX Association, Denver.
Oakes E, Yang L, Zhou D, Houck K, Harter T, Arpaci-Dusseau AC, Arpaci-Dusseau RH (2018) Sock: Rapid task provisioning with serverless-optimized containers In: Proceedings of the 2018 USENIX Conference on Usenix Annual Technical Conference (USENIX ATC ‘18), 57–69.. USENIX Association, USA.
Oakes E, Yang L, Houck K, Harter T, Arpaci-Dusseau AC, Arpaci-Dusseau RH (2017) Pipsqueak: Lean lambdas with large libraries In: 2017 IEEE 37th International Conference on Distributed Computing Systems Workshops (ICDCSW), 395–400. https://doi.org/10.1109/ICDCSW.2017.32 .
Singhvi A, Khalid J, Akella A, Banerjee S (2020) Snf: Serverless network functions In: Proceedings of the 11th ACM Symposium on Cloud Computing (SoCC ’20), 296–310.. Association for Computing Machinery, New York. https://doi.org/10.1145/3419111.3421295 .
Wang L, Li M, Zhang Y, Ristenpart T, Swift M (2018) Peeking behind the curtains of serverless platforms In: Proceedings of the 2018 USENIX Conference on Usenix Annual Technical Conference (USENIX ATC ’18), 133–145.. USENIX Association, USA.
Abad CL, Boza EF, van Eyk E (2018) Package-aware scheduling of faas functions In: Companion of the 2018 ACM/SPEC International Conference on Performance Engineering (ICPE ‘18), 101–106.. Association for Computing Machinery, New York. https://doi.org/10.1145/3185768.3186294 .
Aumala G, Boza E, Ortiz-Avilés L, Totoy G, Abad C (2019) Beyond load balancing: Package-aware scheduling for serverless platforms In: 2019 19th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID), 282–291. https://doi.org/10.1109/CCGRID.2019.00042 .
Alpernas K, Flanagan C, Fouladi S, Ryzhyk L, Sagiv M, Schmitz T, Winstein K (2018) Secure serverless computing using dynamic information flow control. Proc ACM Program Lang 2(OOPSLA):1–26. https://doi.org/10.1145/3276488 .
Kaffes K, Yadwadkar NJ, Kozyrakis C (2019) Centralized core-granular scheduling for serverless functions In: Proceedings of the ACM Symposium on Cloud Computing (SoCC ‘19), 158–164.. Association for Computing Machinery, New York. https://doi.org/10.1145/3357223.3362709 .
Choi S, Shahbaz M, Prabhakar B, Rosenblum M (2019) λ -nic: Interactive serverless compute on smartnics In: Proceedings of the ACM SIGCOMM 2019 Conference Posters and Demos (SIGCOMM Posters and Demos ’19), 151–152.. Association for Computing Machinery, New York. https://doi.org/10.1145/3342280.3342341 .
Manner J, Endreß M, Heckel T, Wirtz G (2018) Cold start influencing factors in function as a service In: 2018 IEEE/ACM International Conference on Utility and Cloud Computing Companion (UCC Companion), 181–188. https://doi.org/10.1109/UCC-Companion.2018.00054 .
Manner J, Kolb S, Wirtz G (2019) Troubleshooting serverless functions: a combined monitoring and debugging approach. SICS Softw-Intensiv Cyber-Physical Syst 34(2):99–104. https://doi.org/10.1007/s00450-019-00398-6 .
Winzinger S, Wirtz G (2019) Model-based analysis of serverless applications In: 2019 IEEE/ACM 11th International Workshop on Modelling in Software Engineering (MiSE), 82–88. https://doi.org/10.1109/MiSE.2019.00020 .
Winzinger S, Wirtz G (2020) Applicability of coverage criteria for serverless applications In: 2020 IEEE International Conference on Service Oriented Systems Engineering (SOSE), 49–56. https://doi.org/10.1109/SOSE49046.2020.00013 .
Prechtl M, Lichtenthäler R, Wirtz G (2020) Investigating possibilites for protecting and hardening installable faas platforms. In: Dustdar S (ed)Service-Oriented Computing, 107–126.. Springer, Cham.
Gias AU, Casale G (2020) Cocoa: Cold start aware capacity planning for function-as-a-service platforms In: 2020 28th International Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems (MASCOTS), 1–8. https://doi.org/10.1109/MASCOTS50786.2020.9285966 .
Chatley R, Allerton T (2020) Nimbus: Improving the developer experience for serverless applications In: 2020 IEEE/ACM 42nd International Conference on Software Engineering: Companion Proceedings (ICSE-Companion), 85–88.
Casale G, Artač M, van den Heuvel W-J, van Hoorn A, Jakovits P, Leymann F, Long M, Papanikolaou V, Presenza D, Russo A, Srirama SN, Tamburri DA, Wurster M, Zhu L (2020) Radon: rational decomposition and orchestration for serverless computing. SICS Softw-Intens Cyber-Phys Syst 35(1):77–87. https://doi.org/10.1007/s00450-019-00413-w .
Vandebon J, Coutinho JGF, Luk W, Nurvitadhi E, Naik M (2020) Slate: Managing heterogeneous cloud functions In: 2020 IEEE 31st International Conference on Application-specific Systems, Architectures and Processors (ASAP), 141–148. https://doi.org/10.1109/ASAP49362.2020.00032 .
Kim J, Lee K (2019) Functionbench: A suite of workloads for serverless cloud function service In: 2019 IEEE 12th International Conference on Cloud Computing (CLOUD), 502–504. https://doi.org/10.1109/CLOUD.2019.00091 .
Kim J, Park J, Lee K (2019) Network resource isolation in serverless cloud function service In: 2019 IEEE 4th International Workshops on Foundations and Applications of Self* Systems (FAS*W), 182–187. https://doi.org/10.1109/FAS-W.2019.00051 .
Park J, Kim H, Lee K (2020) Evaluating concurrent executions of multiple function-as-a-service runtimes with microvm In: 2020 IEEE 13th International Conference on Cloud Computing (CLOUD), 532–536. https://doi.org/10.1109/CLOUD49709.2020.00080 .
Choi J, Lee K (2020) Evaluation of network file system as a shared data storage in serverless computing In: Proceedings of the 2020 Sixth International Workshop on Serverless Computing (WoSC’20), 25–30.. Association for Computing Machinery, New York. https://doi.org/10.1145/3429880.3430096 .
Kim J, Lee K (2020) I/o resource isolation of public cloud serverless function runtimes for data-intensive applications. Clust Comput 23(3):2249–2259. https://doi.org/10.1007/s10586-020-03103-4 .
Wu M, Mi Z, Xia Y (2020) A survey on serverless computing and its implications for jointcloud computing In: 2020 IEEE International Conference on Joint Cloud Computing, 94–101. https://doi.org/10.1109/JCC49151.2020.00023 .
Li Z, Chen Q, Xue S, Ma T, Yang Y, Song Z, Guo M (2020) Amoeba: Qos-awareness and reduced resource usage of microservices with serverless computing In: 2020 IEEE International Parallel and Distributed Processing Symposium (IPDPS), 399–408. https://doi.org/10.1109/IPDPS47924.2020.00049 .
Du D, Yu T, Xia Y, Zang B, Yan G, Qin C, Wu Q, Chen H (2020) Catalyzer: Sub-millisecond startup for serverless computing with initialization-less booting In: Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’20), 467–481.. Association for Computing Machinery, New York. https://doi.org/10.1145/3373376.3378512 .
Yu T, Liu Q, Du D, Xia Y, Zang B, Lu Z, Yang P, Qin C, Chen H (2020) Characterizing serverless platforms with serverlessbench In: Proceedings of the 11th ACM Symposium on Cloud Computing (SoCC ’20), 30–44.. Association for Computing Machinery, New York. https://doi.org/10.1145/3419111.3421280 .
Liu J, Mi Z, Huang Z, Hua Z, Xia Y (2020) Hcloud: A serverless platform for jointcloud computing In: 2020 IEEE International Conference on Joint Cloud Computing, 86–93. https://doi.org/10.1109/JCC49151.2020.00022 .
Pérez A, Moltó G, Caballer M, Calatrava A (2019) A programming model and middleware for high throughput serverless computing applications In: Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing (SAC ‘19), 106–113.. Association for Computing Machinery, New York. https://doi.org/10.1145/3297280.3297292 .
Pérez A, Moltó G, Caballer M, Calatrava A (2018) Serverless computing for container-based architectures. Future Generation Computer Systems 83:50–59. https://doi.org/10.1016/j.future.2018.01.022 .
Giménez-Alventosa V, Moltó G, Caballer M (2019) A framework and a performance assessment for serverless mapreduce on aws lambda. Future Generation Computer Systems 97:259–274. https://doi.org/10.1016/j.future.2019.02.057 .
Naranjo DM, Risco S, de Alfonso C, Pérez A, Blanquer I, Moltó G (2020) Accelerated serverless computing based on gpu virtualization. J Parallel Distrib Comput 139:32–42. https://doi.org/10.1016/j.jpdc.2020.01.004 .
Wang H, Niu D, Li B (2019) Distributed machine learning with a serverless architecture In: IEEE INFOCOM 2019 - IEEE Conference on Computer Communications, 1288–1296. https://doi.org/10.1109/INFOCOM.2019.8737391 .
Ghaemi S, Khazaei H, Musilek P (2020) Chainfaas: An open blockchain-based serverless platform. IEEE Access 8:131760–131778. https://doi.org/10.1109/ACCESS.2020.3010119 .
Goli A, Hajihassani O, Khazaei H, Ardakanian O, Rashidi M, Dauphinee T (2020) Migrating from monolithic to serverless: A fintech case study In: Companion of the ACM/SPEC International Conference on Performance Engineering (ICPE ’20), 20–25.. Association for Computing Machinery, New York. https://doi.org/10.1145/3375555.3384380 .
Mahmoudi N, Khazaei H (2020) Performance modeling of serverless computing platforms. IEEE Trans Cloud Comput:1–1. https://doi.org/10.1109/TCC.2020.3033373 .
Mahmoudi N, Khazaei H (2020) Temporal performance modelling of serverless computing platforms In: Proceedings of the 2020 Sixth International Workshop on Serverless Computing (WoSC’20), 1–6.. Association for Computing Machinery, New York. https://doi.org/10.1145/3429880.3430092 .
Wurster M, Breitenbücher U, Képes K, Leymann F, Yussupov V (2018) Modeling and automated deployment of serverless applications using tosca In: 2018 IEEE 11th Conference on Service-Oriented Computing and Applications (SOCA), 73–80. https://doi.org/10.1109/SOCA.2018.00017 .
Yussupov V, Breitenbücher U, Hahn M, Leymann F (2019) Serverless parachutes: Preparing chosen functionalities for exceptional workloads In: 2019 IEEE 23rd International Enterprise Distributed Object Computing Conference (EDOC), 226–235. https://doi.org/10.1109/EDOC.2019.00035 .
Yussupov V, Breitenbücher U, Leymann F, Müller C (2019) Facing the unplanned migration of serverless applications: A study on portability problems, solutions, and dead ends In: Proceedings of the 12th IEEE/ACM International Conference on Utility and Cloud Computing (UCC’19), 273–283.. Association for Computing Machinery, New York. https://doi.org/10.1145/3344341.3368813 .
Spillner J (2019) Serverless computing and cloud function-based applications In: Proceedings of the 12th IEEE/ACM International Conference on Utility and Cloud Computing Companion (UCC ‘19 Companion), 177–178.. Association for Computing Machinery, New York. https://doi.org/10.1145/3368235.3370269 .
Murphy S, Persaud L, Martini W, Bosshard B (2020) On the use of web assembly in a serverless context. In: Paasivaara M Kruchten P (eds)Agile Processes in Software Engineering and Extreme Programming – Workshops, 141–145.. Springer, Cham.
Spillner J (2020) Resource management for cloud functions with memory tracing, profiling and autotuning In: Proceedings of the 2020 Sixth International Workshop on Serverless Computing (WoSC’20), 13–18.. Association for Computing Machinery, New York. https://doi.org/10.1145/3429880.3430094 .
Spillner J, Mateos C, Monge DA (2018) Faaster, better, cheaper: The prospect of serverless scientific computing and hpc. In: Mocskos E Nesmachnow S (eds)High Performance Computing, 154–168.. Springer, Cham.
Alder F, Asokan N, Kurnikov A, Paverd A, Steiner M (2019) S-faas: Trustworthy and accountable function-as-a-service using intel sgx In: Proceedings of the 2019 ACM SIGSAC Conference on Cloud Computing Security Workshop (CCSW’19), 185–199.. Association for Computing Machinery, New York. https://doi.org/10.1145/3338466.3358916 .
Kuriata A, Illikkal RG (2020) Predictable performance for qos-sensitive, scalable, multi-tenant function-as-a-service deployments. In: Paasivaara M Kruchten P (eds)Agile Processes in Software Engineering and Extreme Programming – Workshops, 133–140.. Springer, Cham.
Mohan A, Sane H, Doshi K, Edupuganti S, Nayak N, Sukhomlinov V (2019) Agile cold starts for scalable serverless In: Proceedings of the 11th USENIX Conference on Hot Topics in Cloud Computing (HotCloud’19), 21.. USENIX Association, USA.
Shahrad M, Fonseca R, Goiri I, Chaudhry G, Batum P, Cooke J, Laureano E, Tresness C, Russinovich M, Bianchini R (2020) Serverless in the wild: Characterizing and optimizing the serverless workload at a large cloud provider In: 2020 USENIX Annual Technical Conference (USENIX ATC 20), 205–218.
Obetz M, Das A, Castiglia T, Patterson S, Milanova A (2020) Formalizing event-driven behavior of serverless applications. In: Brogi A, Zimmermann W, Kritikos K (eds)Service-Oriented and Cloud Computing, 19–29.. Springer, Cham.
Das A, Imai S, Patterson S, Wittie MP (2020) Performance optimization for edge-cloud serverless platforms via dynamic task placement In: 2020 20th IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing (CCGRID), 41–50. https://doi.org/10.1109/CCGrid49817.2020.00-89 .
Das A, Leaf A, Varela CA, Patterson S (2020) Skedulix: Hybrid cloud scheduling for cost-efficient execution of serverless applications In: 2020 IEEE 13th International Conference on Cloud Computing (CLOUD), 609–618. https://doi.org/10.1109/CLOUD49709.2020.00090 .
Obetz M, Patterson S, Milanova A (2019) Static call graph construction in aws lambda serverless applications In: Proceedings of the 11th USENIX Conference on Hot Topics in Cloud Computing (HotCloud’19), 20.. USENIX Association, USA.
Lin W, Krintz C, Wolski R, Zhang M, Cai X, Li T, Xu W (2018) Tracking causal order in aws lambda applications In: 2018 IEEE International Conference on Cloud Engineering (IC2E), 50–60. https://doi.org/10.1109/IC2E.2018.00027 .
George G, Bakir F, Wolski R, Krintz C (2020) Nanolambda: Implementing functions as a service at all resource scales for the internet of things In: 2020 IEEE/ACM Symposium on Edge Computing (SEC), 220–231. https://doi.org/10.1109/SEC50012.2020.00035 .
Zhang M, Krintz C, Wolski R (2020) Stoic: Serverless teleoperable hybrid cloud for machine learning applications on edge device In: 2020 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), 1–6. https://doi.org/10.1109/PerComWorkshops48775.2020.9156239 .
Datta P, Kumar P, Morris T, Grace M, Rahmati A, Bates A (2020) Valve: Securing function workflows on serverless computing platforms In: Proceedings of The Web Conference 2020 (WWW ’20), 939–950.. Association for Computing Machinery, New York. https://doi.org/10.1145/3366423.3380173 .
Sankaran A, Datta P, Bates A (2020) Workflow integration alleviates identity and access management in serverless computing In: Annual Computer Security Applications Conference (ACSAC ’20), 496–509.. Association for Computing Machinery, New York. https://doi.org/10.1145/3427228.3427665 .
Elgamal T (2018) Costless: Optimizing cost of serverless computing through function fusion and placement In: 2018 IEEE/ACM Symposium on Edge Computing (SEC), 300–312. https://doi.org/10.1109/SEC.2018.00029 .
Dehury CK, Srirama SN, Chhetri TR (2020) Ccodamic: A framework for coherent coordination of data migration and computation platforms. Futur Gener Comput Syst 109:1–16. https://doi.org/10.1016/j.future.2020.03.029 .
Dehury C, Jakovits P, Srirama SN, Tountopoulos V, Giotis G (2020) Data pipeline architecture for serverless platform. In: Muccini H, Avgeriou P, Buhnova B, Camara J, Caporuscio M, Franzago M, Koziolek A, Scandurra P, Trubiani C, Weyns D, Zdun U (eds)Software Architecture, 241–246.. Springer, Cham.
Sarkar S, Wankar R, Srirama SN, Suryadevara NK (2020) Serverless management of sensing systems for fog computing framework. IEEE Sensors J 20(3):1564–72. https://doi.org/10.1109/JSEN.2019.2939182 .
Malawski M, Gajek A, Zima A, Balis B, Figiela K (2017) Serverless execution of scientific workflows: Experiments with hyperflow, aws lambda and google cloud functions. Futur Gener Comput Syst:1–13. https://doi.org/10.1016/j.future.2017.10.029 .
Moczurad P, Malawski M (2018) Visual-textual framework for serverless computation: A luna language approach In: 2018 IEEE/ACM International Conference on Utility and Cloud Computing Companion (UCC Companion), 169–74. https://doi.org/10.1109/UCC-Companion.2018.00052 .
Pawlik M, Banach P, Malawski M (2020) Adaptation of workflow application scheduling algorithm to serverless infrastructure. In: Schwardmann U, Boehme C, B. Heras D, Cardellini V, Jeannot E, Salis A, Schifanella C, Manumachu RR, Schwamborn D, Ricci L, Sangyoon O, Gruber T, Antonelli L, Scott SL (eds)Euro-Par 2019: Parallel Processing Workshops, 345–356.. Springer, Cham.
Akhtar N, Raza A, Ishakian V, Matta I (2020) Cose: Configuring serverless functions using statistical learning In: IEEE INFOCOM 2020 - IEEE Conference on Computer Communications, 129–38. https://doi.org/10.1109/INFOCOM41043.2020.9155363 .
Cadden J, Unger T, Awad Y, Dong H, Krieger O, Appavoo J (2020) Seuss: Skip redundant paths to make serverless fast In: Proceedings of the Fifteenth European Conference on Computer Systems (EuroSys ’20).. Association for Computing Machinery, New York. https://doi.org/10.1145/3342195.3392698 .
Balla D, Maliosz M, Simon C (2020) Open source faas performance aspects In: 2020 43rd International Conference on Telecommunications and Signal Processing (TSP), 358–364. https://doi.org/10.1109/TSP49548.2020.9163456 .
Pelle I, Czentye J, Dóka J, Kern A, Gerő BP, Sonkoly B (2020) Operating latency sensitive applications on public serverless edge cloud platforms. IEEE Internet Things J:1–1. https://doi.org/10.1109/JIOT.2020.3042428 .
Balla D, Maliosz M, Simon C, Gehberger D (2020) Tuning runtimes in open source faas. In: Hsu C-H, Kallel S, Lan K-C, Zheng Z (eds)Internet of Vehicles. Technologies and Services Toward Smart Cities, 250–266.. Springer, Cham.
Carver B, Zhang J, Wang A, Cheng Y (2019) In search of a fast and efficient serverless dag engine In: 2019 IEEE/ACM Fourth International Parallel Data Systems Workshop (PDSW), 1–10. https://doi.org/10.1109/PDSW49588.2019.00005 .
Gadepalli PK, McBride S, Peach G, Cherkasova L, Parmer G (2020) Sledge: A Serverless-First, Light-Weight Wasm Runtime for the Edge. Association for Computing Machinery, New York.
Gadepalli PK, Peach G, Cherkasova L, Aitken R, Parmer G (2019) Challenges and opportunities for efficient serverless computing at the edge In: 2019 38th Symposium on Reliable Distributed Systems (SRDS), 261–2615. https://doi.org/10.1109/SRDS47363.2019.00036 .
Somu N, Daw N, Bellur U, Kulkarni P (2020) Panopticon: A comprehensive benchmarking tool for serverless applications In: 2020 International Conference on COMmunication Systems NETworkS (COMSNETS), 144–151. https://doi.org/10.1109/COMSNETS48256.2020.9027346 .
Bajaj D, Bharti U, Goel A, Gupta SC (2020) Partial migration for re-architecting a cloud native monolithic application into microservices and faas. In: Badica C, Liatsis P, Kharb L, Chahal D (eds)Information, Communication and Computing Technology, 111–124.. Springer, Singapore.
Daw N, Bellur U, Kulkarni P (2020) Xanadu: Mitigating Cascading Cold Starts in Serverless Function Chain Deployments. Association for Computing Machinery, New York.
HoseinyFarahabady M, Lee YC, Zomaya AY, Tari Z (2017) A qos-aware resource allocation controller for function as a service (faas) platform. In: Maximilien M, Vallecillo A, Wang J, Oriol M (eds)Service-Oriented Computing, 241–255.. Springer, Cham. https://doi.org/10.1007/978-3-319-69035-3_17 .
Kim YK, HoseinyFarahabady MR, Lee YC, Zomaya AY, Jurdak R (2018) Dynamic control of cpu usage in a lambda platform In: 2018 IEEE International Conference on Cluster Computing (CLUSTER), 234–244. https://doi.org/10.1109/CLUSTER.2018.00041 .
Kim YK, HoseinyFarahabady MR, Lee YC, Zomaya AY (2020) Automated fine-grained cpu cap control in serverless computing platform. IEEE Transactions on Parallel and Distributed Systems 31(10):2289–2301. https://doi.org/10.1109/TPDS.2020.2989771 .
Suresh A, Somashekar G, Varadarajan A, Kakarla VR, Upadhyay H, Gandhi A (2020) Ensure: Efficient scheduling and autonomous resource management in serverless environments In: 2020 IEEE International Conference on Autonomic Computing and Self-Organizing Systems (ACSOS), 1–10. https://doi.org/10.1109/ACSOS49614.2020.00020 .
Suresh A, Gandhi A (2019) Fnsched: An efficient scheduler for serverless functions In: Proceedings of the 5th International Workshop on Serverless Computing (WOSC ’19), 19–24.. Association for Computing Machinery, New York. https://doi.org/10.1145/3366623.3368136 .
Hunhoff E, Irshad S, Thurimella V, Tariq A, Rozner E (2020) Proactive serverless function resource management In: Proceedings of the 2020 Sixth International Workshop on Serverless Computing (WoSC’20), 61–66.. Association for Computing Machinery, New York. https://doi.org/10.1145/3429880.3430102 .
Tariq A, Pahl A, Nimmagadda S, Rozner E, Lanka S (2020) Sequoia: Enabling quality-of-service in serverless computing In: Proceedings of the 11th ACM Symposium on Cloud Computing (SoCC ’20), 311–327.. Association for Computing Machinery, New York. https://doi.org/10.1145/3419111.3421306 .
Crane M, Lin J (2017) An exploration of serverless architectures for information retrieval In: Proceedings of the ACM SIGIR International Conference on Theory of Information Retrieval (ICTIR ‘17), 241–244.. Association for Computing Machinery, New York. https://doi.org/10.1145/3121050.3121086 .
Kim Y, Lin J (2018) Serverless data analytics with flint In: 2018 IEEE 11th International Conference on Cloud Computing (CLOUD), 451–455. https://doi.org/10.1109/CLOUD.2018.00063 .
Król M, Psaras I (2017) Nfaas: Named function as a service In: Proceedings of the 4th ACM Conference on Information-Centric Networking (ICN ‘17), 134–144.. Association for Computing Machinery, New York. https://doi.org/10.1145/3125719.3125727 .
Parres-Peredo A, Piza-Davila I, Cervantes F (2019) Building and evaluating user network profiles for cybersecurity using serverless architecture In: 2019 42nd International Conference on Telecommunications and Signal Processing (TSP), 164–167. https://doi.org/10.1109/TSP.2019.8768825 .
Ivanov V, Smolander K (2018) Implementation of a devops pipeline for serverless applications. In: Kuhrmann M, Schneider K, Pfahl D, Amasaki S, Ciolkowski M, Hebig R, Tell P, Klünder J, Küpper S (eds)Product-Focused Software Process Improvement, 48–64.. Springer, Cham. https://doi.org/10.1007/978-3-030-03673-7_4 .
Chen H, Zhang L-J (2018) Fbaas: Functional blockchain as a service. In: Chen S, Wang H, Zhang L-J (eds)Blockchain – ICBC 2018, 243–250.. Springer, Cham. https://doi.org/10.1007/978-3-319-94478-4_17 .
Lehvä J, Mäkitalo N, Mikkonen T (2018) Case study: Building a serverless messenger chatbot. In: Garrigós I Wimmer M (eds)Current Trends in Web Engineering, 75–86.. Springer, Cham. https://doi.org/10.1007/978-3-319-74433-9_6 .
Poth A, Schubert N, Riel A (2020) Sustainability efficiency challenges of modern it architectures – a quality model for serverless energy footprint. In: Yilmaz M, Niemann J, Clarke P, Messnarz R (eds)Systems, Software and Services Process Improvement, 289–301.. Springer, Cham.
Deese A (2018) Implementation of unsupervised k-means clustering algorithm within amazon web services lambda In: 2018 18th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID), 626–632. https://doi.org/10.1109/CCGRID.2018.00093 .
Jangda A, Pinckney D, Brun Y, Guha A (2019) Formal foundations of serverless computing. Proc ACM Program Lang 3(OOPSLA):1–26. https://doi.org/10.1145/3360575 .
Back T, Andrikopoulos V (2018) Using a microbenchmark to compare function as a service solutions. In: Kritikos K, Plebani P, de Paoli F (eds)Service-Oriented and Cloud Computing, 146–160.. Springer, Cham. https://doi.org/10.1007/978-3-319-99819-0\_11 .
Kritikos K, Skrzypek P (2018) A review of serverless frameworks In: 2018 IEEE/ACM International Conference on Utility and Cloud Computing Companion (UCC Companion), 161–168. https://doi.org/10.1109/UCC-Companion.2018.00051 .
Kritikos K, Skrzypek P (2019) Simulation-as-a-service with serverless computing In: 2019 IEEE World Congress on Services (SERVICES), vol. 2642-939X, 200–205. https://doi.org/10.1109/SERVICES.2019.00056 .
Ast M, Gaedke M (2017) Self-contained web components through serverless computing In: Proceedings of the 2nd International Workshop on Serverless Computing (WoSC ‘17), 28–33.. Association for Computing Machinery, New York. https://doi.org/10.1145/3154847.3154849 .
Trach B, Oleksenko O, Gregor F, Bhatotia P, Fetzer C (2019) Clemmys: Towards secure remote execution in faas In: Proceedings of the 12th ACM International Conference on Systems and Storage (SYSTOR ‘19), 44–54.. Association for Computing Machinery, New York. https://doi.org/10.1145/3319647.3325835 .
Aditya P, Akkus IE, Beck A, Chen R, Hilt V, Rimac I, Satzke K, Stein M (2019) Will serverless computing revolutionize nfv?Proc IEEE 107(4):667–678. https://doi.org/10.1109/JPROC.2019.2898101 .
Baresi L, Filgueira Mendonça D, Garriga M (2017) Empowering low-latency applications through a serverless edge computing architecture. In: De Paoli F, Schulte S, Broch Johnsen E (eds)Service-Oriented and Cloud Computing, 196–210.. Springer, Cham.
Tang Y, Yang J (2020) Lambdata: Optimizing serverless computing by making data intents explicit In: 2020 IEEE 13th International Conference on Cloud Computing (CLOUD), 294–303. https://doi.org/10.1109/CLOUD49709.2020.00049 .
Ali A, Pinciroli R, Yan F, Smirni E (2020) Batch: Machine learning inference serving on serverless platforms with adaptive batching In: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC ’20), 1–15.
Christidis A, Moschoyiannis S, Hsu C-H, Davies R (2020) Enabling serverless deployment of large-scale ai workloads. IEEE Access 8:70150–70161. https://doi.org/10.1109/ACCESS.2020.2985282 .
Aske A, Zhao X (2018) Supporting multi-provider serverless computing on the edge In: Proceedings of the 47th International Conference on Parallel Processing Companion (ICPP ‘18).. Association for Computing Machinery, New York. https://doi.org/10.1145/3229710.3229742 .
Gunasekaran JR, Thinakaran P, Nachiappan NC, Srivatsa Kannan R, Kandemir MT, Das CR (2020) Characterizing bottlenecks in scheduling microservices on serverless platforms In: 2020 IEEE 40th International Conference on Distributed Computing Systems (ICDCS), 1197–1198. https://doi.org/10.1109/ICDCS47774.2020.00195 .
Dziurzanski P, Swan J, Indrusiak LS (2018) Value-based manufacturing optimisation in serverless clouds for industry 4.0 In: Proceedings of the Genetic and Evolutionary Computation Conference (GECCO ‘18), 1222–1229.. Association for Computing Machinery, New York. https://doi.org/10.1145/3205455.3205501 .
Mujezinović A, Ljubović V (2019) Serverless architecture for workflow scheduling with unconstrained execution environment In: 2019 42nd International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), 242–246. https://doi.org/10.23919/MIPRO.2019.8756833 .
Tricomi G, Giosa D, Merlino G, Romeo O, Longo F (2020) Toward a function-as-a-service framework for genomic analysis In: 2020 IEEE International Conference on Smart Computing (SMARTCOMP), 314–319. https://doi.org/10.1109/SMARTCOMP50058.2020.00070 .
Fingler H, Akshintala A, Rossbach CJ (2019) Usetl: Unikernels for serverless extract transform and load why should you settle for less? In: Proceedings of the 10th ACM SIGOPS Asia-Pacific Workshop on Systems (APSys ’19), 23–30.. Association for Computing Machinery, New York. https://doi.org/10.1145/3343737.3343750 .
Soltani B, Ghenai A, Zeghib N (2018) Towards distributed containerized serverless architecture in multi cloud environment. Proc Comput Sci 134:121–128. https://doi.org/10.1016/j.procs.2018.07.152. The 15th International Conference on Mobile Systems and Pervasive Computing (MobiSPC 2018) / The 13th International Conference on Future Networks and Communications (FNC-2018) / Affiliated Workshops.
Crespo-Cepeda R, Agapito G, Vazquez-Poletti JL, Cannataro M (2019) Challenges and opportunities of amazon serverless lambda services in bioinformatics In: Proceedings of the 10th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics (BCB ‘19), 663–668.. Association for Computing Machinery, New York. https://doi.org/10.1145/3307339.3343462 .
Dash S, Dash DK (2016) Serverless cloud computing framework for smart grid architecture In: 2016 IEEE 7th Power India International Conference (PIICON), 1–6. https://doi.org/10.1109/POWERI.2016.8077240 .
Horovitz S, Amos R, Baruch O, Cohen T, Oyar T, Deri A (2019) Faastest - machine learning based cost and performance faas optimization. In: Coppola M, Carlini E, D’Agostino D, Altmann J, Bañares JÁ (eds)Economics of Grids, Clouds, Systems, and Services, 171–186.. Springer, Cham. https://doi.org/10.1007/978-3-030-13342-9\_15 .
Bardsley D, Ryan L, Howard J (2018) Serverless performance and optimization strategies In: 2018 IEEE International Conference on Smart Cloud (SmartCloud), 19–26. https://doi.org/10.1109/SmartCloud.2018.00012 .
Jackson D, Clynch G (2018) An investigation of the impact of language runtime on the performance and cost of serverless functions In: 2018 IEEE/ACM International Conference on Utility and Cloud Computing Companion (UCC Companion), 154–160. https://doi.org/10.1109/UCC-Companion.2018.00050 .
Kaplunovich A (2019) Tolambda–automatic path to serverless architectures In: 2019 IEEE/ACM 3rd International Workshop on Refactoring (IWoR), 1–8. https://doi.org/10.1109/IWoR.2019.00008 .
Lee H, Satyam K, Fox G (2018) Evaluation of production serverless computing environments In: 2018 IEEE 11th International Conference on Cloud Computing (CLOUD), 442–450. https://doi.org/10.1109/CLOUD.2018.00062 .
Asghar T, Rasool S, Iqbal MU, Qayyum Z, Mian AN, Ubakanma G (2018) Feasibility of serverless cloud services for disaster management information systems In: 2018 IEEE 20th International Conference on High Performance Computing and Communications; IEEE 16th International Conference on Smart City; IEEE 4th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), 1054–1057. https://doi.org/10.1109/HPCC/SmartCity/DSS.2018.00175 .
McGrath G, Brenner PR (2017) Serverless computing: Design, implementation, and performance In: 2017 IEEE 37th International Conference on Distributed Computing Systems Workshops (ICDCSW), 405–410. https://doi.org/10.1109/ICDCSW.2017.36 .
Christoforou A, Andreou AS (2018) An effective resource management approach in a faas environment In: ESSCA@UCC, 2–8.
Rajan RAP (2018) Serverless architecture - a revolution in cloud computing In: 2018 Tenth International Conference on Advanced Computing (ICoAC), 88–93. https://doi.org/10.1109/ICoAC44903.2018.8939081 .
Rahman MM, Hasibul Hasan M (2019) Serverless architecture for big data analytics In: 2019 Global Conference for Advancement in Technology (GCAT), 1–5. https://doi.org/10.1109/GCAT47503.2019.8978443 .
Huber F, Körber N, Mock M (2019) Selena: A serverless energy management system In: Proceedings of the 5th International Workshop on Serverless Computing (WOSC ‘19), 7–12.. Association for Computing Machinery, New York. https://doi.org/10.1145/3366623.3368134 .
Aytekin A, Johansson M (2019) Exploiting serverless runtimes for large-scale optimization In: 2019 IEEE 12th International Conference on Cloud Computing (CLOUD), 499–501. https://doi.org/10.1109/CLOUD.2019.00090 .
Gabbrielli M, Giallorenzo S, Lanese I, Montesi F, Peressotti M, Zingaro SP (2019) No more, no less: A formal model for serverless computing. In: Riis Nielson H Tuosto E (eds)Coordination Models and Languages, 148–157.. Springer, Cham. https://doi.org/10.1007/978-3-030-22397-7_9 .
Fasogbon P, You Y, Aksu E (2020) 3d human model creation on a serverless environment In: 2020 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), 118–122. https://doi.org/10.1109/ISMAR-Adjunct51615.2020.00044 .
Dash S, Sodhi R, Sodhi B (2020) A serverless cloud computing framework for real-time appliance-usage recommendation In: 2020 21st National Power Systems Conference (NPSC), 1–6. https://doi.org/10.1109/NPSC49263.2020.9331847 .
Thong Tran T, Zhang Y-C, Liao W-T, Lin Y-J, Li M-C, Huang H-S (2020) An autonomous mobile robot system based on serverless computing and edge computing In: 2020 21st Asia-Pacific Network Operations and Management Symposium (APNOMS), 334–337. https://doi.org/10.23919/APNOMS50412.2020.9236976 .
Witte PA, Louboutin M, Modzelewski H, Jones C, Selvage J, Herrmann FJ (2020) An event-driven approach to serverless seismic imaging in the cloud. IEEE Trans Parallel Distributed Syst 31(9):2032–2049. https://doi.org/10.1109/TPDS.2020.2982626 .
Ghosh BC, Addya SK, Somy NB, Nath SB, Chakraborty S, Ghosh SK (2020) Caching techniques to improve latency in serverless architectures In: 2020 International Conference on COMmunication Systems NETworkS (COMSNETS), 666–669. https://doi.org/10.1109/COMSNETS48256.2020.9027427 .
Quaresma D, Fireman D, Pereira TE (2020) Controlling garbage collection and request admission to improve performance of faas applications In: 2020 IEEE 32nd International Symposium on Computer Architecture and High Performance Computing (SBAC-PAD), 175–182. https://doi.org/10.1109/SBAC-PAD49847.2020.00033 .
Birman Y, Hindi S, Katz G, Shabtai A (2020) Cost-effective malware detection as a service over serverless cloud using deep reinforcement learning In: 2020 20th IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing (CCGRID), 420–429. https://doi.org/10.1109/CCGrid49817.2020.00-51 .
Quang T, Peng Y (2020) Device-driven on-demand deployment of serverless computing functions In: 2020 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), 1–6. https://doi.org/10.1109/PerComWorkshops48775.2020.9156140 .
Gunasekaran JR, Thinakaran P, Nachiappan NC, Kandemir MT, Das CR (2020) Fifer: Tackling Resource Underutilization in the Serverless Era. Association for Computing Machinery, New York.
Müller I, Marroquín R, Alonso G (2020) Lambada: Interactive data analytics on cold data using serverless cloud infrastructure In: Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data (SIGMOD ’20), 115–130.. Association for Computing Machinery, New York. https://doi.org/10.1145/3318464.3389758 .
Chahal D, Ojha R, Ramesh M, Singhal R (2020) Migrating large deep learning models to serverless architecture In: 2020 IEEE International Symposium on Software Reliability Engineering Workshops (ISSREW), 111–116. https://doi.org/10.1109/ISSREW51248.2020.00047 .
Jain P, Munjal Y, Gera J, Gupta P (2020) Performance analysis of various server hosting techniques. Proc Comput Sci 173:70–77. https://doi.org/10.1016/j.procs.2020.06.010. International Conference on Smart Sustainable Intelligent Computing and Applications under ICITETM2020.
Khatri D, Khatri SK, Mishra D (2020) Potential bottleneck and measuring performance of serverless computing: A literature study In: 2020 8th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), 161–164. https://doi.org/10.1109/ICRITO48877.2020.9197837 .
Kehrer S, Zietlow D, Scheffold J, Blochinger W (2020) Self-tuning serverless task farming using proactive elasticity control. Clust Comput. https://doi.org/10.1007/s10586-020-03158-3 .
Kelly D, Glavin F, Barrett E (2020) Serverless computing: Behind the scenes of major platforms In: 2020 IEEE 13th International Conference on Cloud Computing (CLOUD), 304–312. https://doi.org/10.1109/CLOUD49709.2020.00050 .
Ivan C, Vasile R, Dadarlat V (2019) Serverless computing: An investigation of deployment environments for web apis. Computers 8(2). https://doi.org/10.3390/computers8020050 .
Baresi L, Filgueira Mendonça D (2019) Towards a serverless platform for edge computing In: 2019 IEEE International Conference on Fog Computing (ICFC), 1–10. https://doi.org/10.1109/ICFC.2019.00008 .
Hall A, Ramachandran U (2019) An execution model for serverless functions at the edge In: Proceedings of the International Conference on Internet of Things Design and Implementation (IoTDI ‘19), 225–236.. Association for Computing Machinery, New York. https://doi.org/10.1145/3302505.3310084 .
Akkus IE, Chen R, Rimac I, Stein M, Satzke K, Beck A, Aditya P, Hilt V (2018) Sand: Towards high-performance serverless computing In: Proceedings of the 2018 USENIX Conference on Usenix Annual Technical Conference (USENIX ATC ‘18), 923–935.. USENIX Association, USA.
Keshavarzian A, Sharifian S, Seyedin S (2019) Modified deep residual network architecture deployed on serverless framework of iot platform based on human activity recognition application. Futur Gener Comput Syst 101:14–28. https://doi.org/10.1016/j.future.2019.06.009 .
Palade A, Kazmi A, Clarke S (2019) An evaluation of open source serverless computing frameworks support at the edge In: 2019 IEEE World Congress on Services (SERVICES), vol. 2642-939X, 206–211. https://doi.org/10.1109/SERVICES.2019.00057 .
Shahrad M, Balkind J, Wentzlaff D (2019) Architectural implications of function-as-a-service computing In: Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO ‘52), 1063–1075.. Association for Computing Machinery, New York. https://doi.org/10.1145/3352460.3358296 .
Cicconetti C, Conti M, Passarella A (2020) A decentralized framework for serverless edge computing in the internet of things. IEEE Trans Netw Serv Manag:1–1. https://doi.org/10.1109/TNSM.2020.3023305 .
De Palma G, Giallorenzo S, Mauro J, Zavattaro G (2020) Allocation priority policies for serverless function-execution scheduling optimisation. In: Kafeza E, Benatallah B, Martinelli F, Hacid H, Bouguettaya A, Motahari H (eds)Service-Oriented Computing, 416–430.. Springer, Cham.
Djemame K, Parker M, Datsev D (2020) Open-source serverless architectures: an evaluation of apache openwhisk In: 2020 IEEE/ACM 13th International Conference on Utility and Cloud Computing (UCC), 329–335. https://doi.org/10.1109/UCC48980.2020.00052 .
Chadha M, Jindal A, Gerndt M (2020) Towards federated learning using faas fabric In: Proceedings of the 2020 Sixth International Workshop on Serverless Computing (WoSC’20), 49–54.. Association for Computing Machinery, New York. https://doi.org/10.1145/3429880.3430100 .
Cheng B, Fuerst J, Solmaz G, Sanada T (2019) Fog function: Serverless fog computing for data intensive iot services In: 2019 IEEE International Conference on Services Computing (SCC), 28–35. https://doi.org/10.1109/SCC.2019.00018 .
Mohanty SK, Premsankar G, di Francesco M (2018) An evaluation of open source serverless computing frameworks In: 2018 IEEE International Conference on Cloud Computing Technology and Science (CloudCom), 115–120. https://doi.org/10.1109/CloudCom2018.2018.00033 .
Li J, Kulkarni SG, Ramakrishnan KK, Li D (2019) Understanding open source serverless platforms: Design considerations and performance In: Proceedings of the 5th International Workshop on Serverless Computing (WOSC ‘19), 37–42.. Association for Computing Machinery, New York. https://doi.org/10.1145/3366623.3368139 .
Nguyen HD, Zhang C, Xiao Z, Chien AA (2019) Real-time serverless: Enabling application performance guarantees In: Proceedings of the 5th International Workshop on Serverless Computing (WOSC ’19), 1–6.. Association for Computing Machinery, New York. https://doi.org/10.1145/3366623.3368133 .
Saha A, Jindal S (2018) Emars: Efficient management and allocation of resources in serverless In: 2018 IEEE 11th International Conference on Cloud Computing (CLOUD), 827–830. https://doi.org/10.1109/CLOUD.2018.00113 .
Solaiman K, Adnan MA (2020) Wlec: A not so cold architecture to mitigate cold start problem in serverless computing In: 2020 IEEE International Conference on Cloud Engineering (IC2E), 144–153. https://doi.org/10.1109/IC2E48712.2020.00022 .
Chan A, Wang K-TA, Kumar V (2019) BalloonJVM : Dynamically Resizable Heap for FaaS In: CLOUD COMPUTING 2019 : The Tenth International Conference on Cloud Computing, GRIDs, and Virtualization, 99–104.
Handoyo E, Arfan M, Soetrisno YAA, Somantri M, Sofwan A, Sinuraya EW (2018) Ticketing chatbot service using serverless nlp technology In: 2018 5th International Conference on Information Technology, Computer, and Electrical Engineering (ICITACEE), 325–330. https://doi.org/10.1109/ICITACEE.2018.8576921 .
Zhang M, Zhu Y, Zhang C, Liu J (2019) Video processing with serverless computing: A measurement study In: Proceedings of the 29th ACM Workshop on Network and Operating Systems Support for Digital Audio and Video (NOSSDAV ’19), 61–66.. Association for Computing Machinery, New York. https://doi.org/10.1145/3304112.3325608 .
Fan D, He D (2020) A scheduler for serverless framework base on kubernetes In: Proceedings of the 2020 4th High Performance Computing and Cluster Technologies Conference; 2020 3rd International Conference on Big Data and Artificial Intelligence (HPCCT; BDAI 2020), 229–232.. Association for Computing Machinery, New York. https://doi.org/10.1145/3409501.3409503 .
Thomas S, Ao L, Voelker GM, Porter G (2020) Particle: Ephemeral endpoints for serverless networking In: Proceedings of the 11th ACM Symposium on Cloud Computing (SoCC ’20), 16–29.. Association for Computing Machinery, New York. https://doi.org/10.1145/3419111.3421275 .
Gramaglia M, Serrano P, Banchs A, Garcia-Aviles G, Garcia-Saavedra A, Perez R (2020) The case for serverless mobile networking In: 2020 IFIP Networking Conference (Networking), 779–784.
Danayi A, Sharifian S (2018) Pess-mina: A proactive stochastic task allocation algorithm for faas edge-cloud environments In: 2018 4th Iranian Conference on Signal Processing and Intelligent Systems (ICSPIS), 27–31. https://doi.org/10.1109/ICSPIS.2018.8700543 .
Mendki P (2020) Evaluating webassembly enabled serverless approach for edge computing In: 2020 IEEE Cloud Summit, 161–166. https://doi.org/10.1109/IEEECloudSummit48914.2020.00031 .
Chaudhry SR, Palade A, Kazmi A, Clarke S (2020) Improved qos at the edge using serverless computing to deploy virtual network functions. IEEE Internet Things J 7(10):10673–10683. https://doi.org/10.1109/JIOT.2020.3011057 .
Benedict S (2020) Serverless blockchain-enabled architecture for iot societal applications. IEEE Trans Comput Soc Syst 7(5):1146–1158. https://doi.org/10.1109/TCSS.2020.3008995 .
Cicconetti C, Conti M, Passarella A (2020) Uncoordinated access to serverless computing in mec systems for iot. Comput Netw 172:107184. https://doi.org/10.1016/j.comnet.2020.107184 .
Qiang W, Dong Z, Jin H (2018) Se-lambda: Securing privacy-sensitive serverless applications using sgx enclave. In: Beyah R, Chang B, Li Y, Zhu S (eds)Security and Privacy in Communication Networks, 451–470.. Springer, Cham. https://doi.org/10.1007/978-3-030-01701-9\_25 .
Prasetyadi G, Hantoro UT, Mutiara AB, Muslim A, Refianti R (2019) Heresy: A serverless web application to store compressed and encrypted document in the form of url In: 2019 Fourth International Conference on Informatics and Computing (ICIC), 1–5. https://doi.org/10.1109/ICIC47613.2019.8985735 .
Kim B, Heo S, Lee J, Jeong S, Lee Y, Kim H (2020) Compiler-assisted semantic-aware encryption for efficient and secure serverless computing. IEEE Internet Things J:1–1. https://doi.org/10.1109/JIOT.2020.3031550 .
O’Meara W, Lennon RG (2020) Serverless computing security: Protecting application logic In: 2020 31st Irish Signals and Systems Conference (ISSC), 1–5. https://doi.org/10.1109/ISSC49989.2020.9180214 .
Agache A, Brooker M, Iordache A, Liguori A, Neugebauer R, Piwonka P, Popa D-M (2020) Firecracker: Lightweight virtualization for serverless applications In: 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI 20), 419–434.. USENIX Association, Santa Clara.
Pinto D, Dias JP, Sereno Ferreira H2018. Dynamic allocation of serverless functions in iot environments. https://doi.org/10.1109/euc.2018.00008 .
Mejáa A, Marcillo D, Guaño M, Gualotuña T (2020) Serverless based control and monitoring for search and rescue robots In: 2020 15th Iberian Conference on Information Systems and Technologies (CISTI), 1–6. https://doi.org/10.23919/CISTI49556.2020.9140444 .
Meißner D, Erb B, Kargl F, Tichy M (2018) Retro- λ : An event-sourced platform for serverless applications with retroactive computing support In: Proceedings of the 12th ACM International Conference on Distributed and Event-Based Systems (DEBS ‘18), 76–87.. Association for Computing Machinery, New York. https://doi.org/10.1145/3210284.3210285 .
Zhang T, Xie D, Li F, Stutsman R (2019) Narrowing the gap between serverless and its state with storage functions In: Proceedings of the ACM Symposium on Cloud Computing (SoCC ‘19), 1–12.. Association for Computing Machinery, New York. https://doi.org/10.1145/3357223.3362723 .
Grogan J, Mulready C, McDermott J, Urbanavicius M, Yilmaz M, Abgaz Y, McCarren A, MacMahon ST, Garousi V, Elger P, Clarke P (2020) A multivocal literature review of function-as-a-service (faas) infrastructures and implications for software developers. In: Yilmaz M, Niemann J, Clarke P, Messnarz R (eds)Systems, Software and Services Process Improvement, 58–75.. Springer, Cham.
Qin S, Wu H, Wu Y, Yan B, Xu Y, Zhang W (2020) Nuka: A generic engine with millisecond initialization for serverless computing In: 2020 IEEE International Conference on Joint Cloud Computing, 78–85. https://doi.org/10.1109/JCC49151.2020.00021 .
Zuk P, Rzadca K (2020) Scheduling methods to reduce response latency of function as a service In: 2020 IEEE 32nd International Symposium on Computer Architecture and High Performance Computing (SBAC-PAD), 132–140. https://doi.org/10.1109/SBAC-PAD49847.2020.00028 .
Shen J, Yu H, Zheng Z, Sun C, Xu M, Wang J (2020) Serpens: A high-performance serverless platform for nfv In: 2020 IEEE/ACM 28th International Symposium on Quality of Service (IWQoS), 1–10. https://doi.org/10.1109/IWQoS49365.2020.9213030 .
Ginzburg S, Freedman MJ (2020) Serverless isn’t server-less: Measuring and exploiting resource variability on cloud faas platforms In: Proceedings of the 2020 Sixth International Workshop on Serverless Computing (WoSC’20), 43–48.. Association for Computing Machinery, New York. https://doi.org/10.1145/3429880.3430099 .
Tankov V, Golubev Y, Bryksin T (2019) Kotless: A serverless framework for kotlin In: 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE), 1110–1113. https://doi.org/10.1109/ASE.2019.00114 .
Vahidinia P, Farahani B, Aliee FS (2020) Cold start in serverless computing: Current trends and mitigation strategies In: 2020 International Conference on Omni-layer Intelligent Systems (COINS), 1–7. https://doi.org/10.1109/COINS49042.2020.9191377 .
Silva P, Fireman D, Pereira TE (2020) Prebaking Functions to Warm the Serverless Cold Start. Association for Computing Machinery, New York.
Tan B, Liu H, Rao J, Liao X, Jin H, Zhang Y (2020) Towards lightweight serverless computing via unikernel as a function In: 2020 IEEE/ACM 28th International Symposium on Quality of Service (IWQoS), 1–10. https://doi.org/10.1109/IWQoS49365.2020.9213020 .
Cordasco G, D’Auria M, Negro A, Scarano V, Spagnuolo C (2020) Fly: A domain-specific language for scientific computing on faas. In: Schwardmann U, Boehme C, B. Heras D, Cardellini V, Jeannot E, Salis A, Schifanella C, Manumachu RR, Schwamborn D, Ricci L, Sangyoon O, Gruber T, Antonelli L, Scott SL (eds)Euro-Par 2019: Parallel Processing Workshops, 531–544.. Springer, Cham.
Nupponen J, Taibi D (2020) Serverless: What it is, what to do and what not to do In: 2020 IEEE International Conference on Software Architecture Companion (ICSA-C), 49–50. https://doi.org/10.1109/ICSA-C50368.2020.00016 .
Reuter A, Back T, Andrikopoulos V (2020) Cost efficiency under mixed serverless and serverful deployments In: 2020 46th Euromicro Conference on Software Engineering and Advanced Applications (SEAA), 242–245. https://doi.org/10.1109/SEAA51224.2020.00049 .
Mahajan K, Figueiredo D, Misra V, Rubenstein D (2019) Optimal pricing for serverless computing In: 2019 IEEE Global Communications Conference (GLOBECOM), 1–6. https://doi.org/10.1109/GLOBECOM38437.2019.9013156 .
Lynn T, Rosati P, Lejeune A, Emeakaroha V (2017) A preliminary review of enterprise serverless cloud computing (function-as-a-service) platforms In: 2017 IEEE International Conference on Cloud Computing Technology and Science (CloudCom), 162–169. https://doi.org/10.1109/CloudCom.2017.15 .
Enes J, Expósito RR, Touriño J (2020) Real-time resource scaling platform for big data workloads on serverless environments. Futur Gener Comput Syst 105:361–379. https://doi.org/10.1016/j.future.2019.11.037 .
Elsakhawy M, Bauer M (2020) Faas2f: A framework for defining execution-sla in serverless computing In: 2020 IEEE Cloud Summit, 58–65. https://doi.org/10.1109/IEEECloudSummit48914.2020.00015 .
Bhattacharjee A, Chhokra AD, Kang Z, Sun H, Gokhale A, Karsai G (2019) Barista: Efficient and scalable serverless serving system for deep learning prediction services In: 2019 IEEE International Conference on Cloud Engineering (IC2E), 23–33. https://doi.org/10.1109/IC2E.2019.00-10 .
Maissen P, Felber P, Kropf P, Schiavoni V (2020) Faasdom: A benchmark suite for serverless computing In: Proceedings of the 14th ACM International Conference on Distributed and Event-Based Systems (DEBS ’20), 73–84.. Association for Computing Machinery, New York. https://doi.org/10.1145/3401025.3401738 .
Xu Z, Zhang H, Geng X, Wu Q, Ma H (2019) Adaptive function launching acceleration in serverless computing platforms In: 2019 IEEE 25th International Conference on Parallel and Distributed Systems (ICPADS), 9–16. https://doi.org/10.1109/ICPADS47876.2019.00011 .
Soltani B, Ghenai A, Zeghib N (2018) A migration-based approach to execute long-duration multi-cloud serverless functions. In: Maamri R Belala F (eds)Proceedings of the 3rd International Conference on Advanced Aspects of Software Engineering, ICAASE 2018, Constantine, Algeria, December 1-2, 2018 (CEUR Workshop Proceedings), vol. 2326, 42–50.
Martins H, Araujo F, da Cunha PR (2020) Benchmarking serverless computing platforms. J Grid Comput 18(4):691–709. https://doi.org/10.1007/s10723-020-09523-1 .
Download references
Acknowledgements
Author information, authors and affiliations.
Software Engineering and Embedded Systems (SEES) Research Group, College of Medicine, University of Duhok, Duhok, Kurdistan Region, Iraq
Hassan B. Hassan
Software Engineering and Embedded Systems (SEES) Research Group, Department of Computer Science, College of Science, University of Duhok, Duhok, Kurdistan Region, Iraq
Saman A. Barakat & Qusay I. Sarhan
You can also search for this author in PubMed Google Scholar
Contributions
Authors’ contributions.
Conceptualization: HBH, SAB, and QIS; methodology: HBH, SAB, and QIS; validation: HBH, SAB, and QIS; formal analysis: HBH, SAB, and QIS; investigation: HBH, SAB, and QIS; resources: HBH; data curation, HBH and SAB; writing—original draft preparation: HBH, SAB, and QIS; writing—review and editing: HBH, SAB, and QIS; visualization: SAB; supervision: QIS; It is noted that all authors cooperated with each other to achieve suitable information flow across the entire paper. The authors read and approved the final manuscript.
Authors’ information
Hassan B. Hassan received the B.Sc. degree in Computer Science from University of Duhok, Iraq, in 2010. He completed the M.Sc. degree in Web Applications and Services, from Leicester University, UK, in 2015. He is currently working as an assistant lecturer at the college of medicine, University of Duhok, Iraq. His main areas of research interest are cloud computing, web programming, big data, and human computer interaction.
Saman A. Barakat received the B.Sc. degree in Computer Science from University of Duhok, Iraq, in 2008. He completed the M.Sc. degree in Advanced Computer Science, from Newcastle University, UK, in 2012. He is currently working as a lecturer at the college of science, University of Duhok, Iraq. His main areas of research interest are cloud computing, and software engineering.
Qusay I. Sarhan received the B.Sc. degree in Software Engineering from University of Mosul, Iraq, in 2007 and the M.Tech. degree in Software Engineering from Jawaharlal Nehru Technological University, India, in 2011. Currently, he is a lecturer and the leader of Software Engineering and Embedded Systems (SEES) research group at University of Duhok, Iraq. He has a couple of national and international publications and his research interests include software engineering, internet of things, and embedded systems.
Corresponding author
Correspondence to Qusay I. Sarhan .
Ethics declarations
Competing interests.
The authors declare that they have no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Hassan, H.B., Barakat, S.A. & Sarhan, Q.I. Survey on serverless computing. J Cloud Comp 10 , 39 (2021). https://doi.org/10.1186/s13677-021-00253-7
Download citation
Received : 01 July 2020
Accepted : 21 June 2021
Published : 12 July 2021
DOI : https://doi.org/10.1186/s13677-021-00253-7
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Cloud computing
- Serverless computing
- Serverless platforms
- Serverless benefits
- Serverless challenges
Green cloud computing adoption challenges and practices: a client’s perspective-based empirical investigation
- Original Article
- Published: 11 August 2023
- Volume 25 , pages 427–446, ( 2023 )
Cite this article

- Ashfaq Ahmad 1 ,
- Rafiq Ahmad Khan 1 , 2 ,
- Siffat Ullah Khan 1 ,
- Hathal Salamah Alwageed 3 ,
- Abdullah A. Al-Atawi 4 &
- Youngmoon Lee 5
333 Accesses
Explore all metrics
Over the last decade, the widespread adoption of cloud computing has spawned a new branch of the computing industry known as green cloud computing. Cloud computing is improving, and data centers are increasing at regular frequencies to meet the demands of users. On the other hand, cloud providers pose major environmental risks because massive data centers use a large amount of energy and leave a carbon footprint. One possible solution to this issue is the use of green cloud computing. However, clients face significant difficulties in adopting green cloud computing. This study aims to understand the problems faced by client organizations while considering green cloud computing. In addition, this study aims to empirically identify the solution to the challenges faced by green cloud computing practitioners. A questionnaire survey approach was used to get insight into green cloud computing practitioners concerning the challenges they faced and their solutions. Data were obtained from sixty-nine professionals in green cloud computing. The results revealed that “lack of quality of service”, “lack of dynamic response”, and “lack of services to satisfy client’s requirements” are critical for green cloud computing. In addition, sixty-three practices for addressing the challenges in green cloud computing are also identified. The identified challenges and practices of green cloud computing will benefit the client organizations to update and revise their process to consider green cloud computing. In addition, it will also assist vendor organizations in developing, planning, and managing systems concerning client satisfaction.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Price includes VAT (Russian Federation)
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
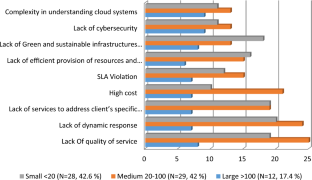
Similar content being viewed by others

Questionnaire Design

Research Methodology: An Introduction

The theory contribution of case study research designs
Ahmad A, Khan SU, Khan HU, Khan GM, Ilyas M (2021a) Challenges and practices identification via a systematic literature review in the adoption of green cloud computing: client’s side approach. IEEE Access 9:81828–81840
Article Google Scholar
Ahmad Z, Jehangiri AI, Ala’anzy MA, Othman M, Latip R, Zaman SKU, Umar AI (2021b) Scientific workflows management and scheduling in cloud computing: taxonomy, prospects, and challenges. IEEE Access 9:53491–53508
Ajmal MS, Iqbal Z, Khan FZ, Bilal M, Mehmood RM (2021) Cost-based energy efficient scheduling technique for dynamic voltage and frequency scaling system in cloud computing. Sustain Energy Technol Assess 45:101210
Google Scholar
Akbar MA, Mahmood S, Alsalman H, Razzaq A, Gumaei A, Riaz MT (2020a) Identification and prioritization of cloud based global software development best practices. IEEE Access 8:191242–191262
Akbar MA, Alsalman H, Khan AA, Mahmood S, Meshram C, Gumaei AH, Riaz MT (2020b) Multicriteria decision making taxonomy of cloud-based global software development motivators. IEEE Access 8:185290–185310
Akbar MA, Mahmood S, Meshram C, Alsanad A, Gumaei A, AlQahtani SA (2022a) Barriers of managing cloud outsource software development projects: a multivocal study. Multimeda Tools Appl 81(25):35571–35594
Akbar MA, Khan AA, Mahmood S, Mishra A (2022b) SRCMIMM: the software requirements change management and implementation maturity model in the domain of global software development industry. Inf Technol Manag. https://doi.org/10.1007/s10799-022-00364-w
Alarifi A, Dubey K, Amoon M, Altameem T, Abd El-Samie FE, Altameem A, Sharma S, Nasr AA (2020) Energy-efficient hybrid framework for green cloud computing. IEEE Access 8:115356–115369
Ali M, Khan SU, Vasilakos AV (2015) Security in cloud computing: Opportunities and challenges. Inf Sci 305:357–383
Article MathSciNet Google Scholar
Bharany S, Badotra S, Sharma S, Rani S, Alazab M, Jhaveri RH, Gadekallu TR (2022) Energy efficient fault tolerance techniques in green cloud computing: a systematic survey and taxonomy. Sustain Energy Technol Assess 53:102613
Chen H, Zhu X, Guo H, Zhu J, Qin X, Wu J (2015) Towards energy-efficient scheduling for real-time tasks under uncertain cloud computing environment. J Syst Softw 99:20–35
Corbin J, Strauss A (2014) Basics of qualitative research: techniques and procedures for developing grounded theory. Sage publications, Thousand Oaks
Creswell JW, Creswell JD (2017) Research design: qualitative, quantitative, and mixed methods approaches. Sage publications, Thousand Oaks
MATH Google Scholar
Dube P, Grabarnik G, Shwartz L (2012) Suits: how to make a global it service provider sustainable? IEEE Network Operations and Management Symposium, Maui, HI, USA, pp 1352–1359
Fang D, Liu X, Liu L, Yang H (2014) OCSO: Off-the-cloud service optimization for green efficient service resource utilization. J Cloud Comput 3(1):1–17
Fielding NG, Lee NFRM, Lee RM (1998) Computer analysis and qualitative research. Sage, Thousand Oaks
Gai K, Qiu M, Zhao H, Tao L, Zong Z (2016) Dynamic energy-aware cloudlet-based mobile cloud computing model for green computing. J Netw Comput Appl 59:46–54
Glaser BG (1978) Theoretical sensitivity. Mill valley. Sociology Press, CA
Goyal Y, Arya MS, Nagpal S (2015) Energy efficient hybrid policy in green cloud computing. In: Proceedings of the 2015 International Conference on Green Computing and Internet of Things (ICGCIoT). IEEE, pp 1065–1069
Ismail AH, El-Bahnasawy NA, Hamed HF (2019) AGCM: active queue management-based green cloud model for mobile edge computing. Wirel Pers Commun 105(3):765–785
Joy N, Chandrasekaran K, Binu A (2015) A study on energy efficient cloud computing. In: Proceedings of the 2015 IEEE International Conference on Computational Intelligence and Computing Research (ICCIC). IEEE, pp 1–6
Khan RA, Khan SU (2015) A survey based study on communication and coordination challenges in offshore software development outsourcing relationships from vendors’ perspective. In: Proceedings of the 4th international multi-topic conference (IMTIC), Mehran University
Khan RA, Khan SU (2018) A preliminary structure of software security assurance model. In: Proceedings of the 13th international conference on global software engineering, Gothenburg, Sweden, pp 137–140
Khan SU, Niazi M, Ahmad R (2012) Empirical investigation of success factors for offshore software development outsourcing vendors. IET Softw 6(1):1–15
Khan RU, Khan SU, Khan R, Ali S (2015) Motivators in green IT-outsourcing from vendor’s perspective: a systematic literature review. Proc Pak Acad Sci 52:345–360
Khan RA, Wang J, Arif M, Khan SU, Idris MY (2016) An exploratory study of communication and coordination challenges in offshore software development outsourcing: results of systematic literature review and empirical study. Sci Int (Lahore) 28(5):4819–4836
Khan RA, Idris MY, Khan SU, Ilyas M, Ali S, Din AU, Murtaza G, Khan AW, Jan SU (2019) An evaluation framework for communication and coordination processes in offshore software development outsourcing relationship: using fuzzy methods. IEEE Access 7:112879–112906
Khan RA, Khan SU, Ilyas M, Idris MY (2020) The state of the art on secure software engineering: a systematic mapping study. In Proceedings of the evaluation and assessment in software engineering, Trondheim, Norway, pp 487–492
Khan RA, Khan SU, Khan HU, Ilyas M (2021) Systematic mapping study on security approaches in secure software engineering. IEEE Access 9:19139–19160
Khan RA, Khan SU, Alzahrani M, Ilyas M (2022a) Security assurance model of software development for global software development vendors. IEEE Access 10:58458–58487
Khan RA, Khan SU, Ilyas M (2022b) Exploring security procedures in secure software engineering: a systematic mapping study. In: The international conference on evaluation and assessment in software engineering, Gothenburg, Sweden, pp 433–439
Khan RA, Khan SU, Khan HU, Ilyas M (2022c) Systematic literature review on security risks and its practices in secure software development. IEEE Access 10:5456–5481
Larumbe F, Sanso B (2013) A tabu search algorithm for the location of data centers and software components in green cloud computing networks. IEEE Trans Cloud Comput 1(1):22–35
Lethbridge TC, Sim SE, Singer J (2005) Studying software engineers: data collection techniques for software field studies. Empir Softw Eng 10(3):311–341
Li J, Li B, Wo T, Hu C, Huai J, Liu L, Lam K (2012) CyberGuarder: a virtualization security assurance architecture for green cloud computing. Futur Gener Comput Syst 28(2):379–390
Lis A, Sudolska A, Pietryka I, Kozakiewicz A (2020) Cloud computing and energy efficiency: mapping the thematic structure of research. Energies 13(16):4117
Panwar S, Rathi K (2015) A survey on green cloud computing. Int J Comput Appl 975:8887
Pragya MMG (2015) Analysis of energy efficient scheduling algorithms in green cloud computing. Int J Adv Res Comput Eng Technol (IJARCET) 4(5):1–180
Rahman M, Gao J, Tsai WT (2013) Energy saving in mobile cloud computing. In: Proceedings of the 2013 IEEE international conference on cloud engineering (IC2E). IEEE, pp.285–291
Rawas S, Itani W, Zaart A, Zekri A (2015) Towards greener services in cloud computing: research and future directives. In: Proceedings of the 2015 international conference on applied research in computer science and engineering (ICAR). IEEE, pp 1–8
Rawat S, Kumar P, Sagar S, Singh I, Garg K (2017) An analytical evaluation of challenges in Green cloud computing. In: Proceedings of the 2017 International conference on infocom technologies and unmanned systems (trends and future directions) (ICTUS). IEEE, pp 351–355
Rubyga G, SathiaBhama PR (2016) A survey of computing strategies for green cloud. In: Proceedings of the 2016 second international conference on science technology engineering and management (ICONSTEM). IEEE, pp 141–145
Runeson P, Höst M (2009) Guidelines for conducting and reporting case study research in software engineering. Empir Softw Eng 14(2):131–164
Shinde V, Kadu D, Painjane S (2015) Study on green cloud computing and environmental feasibility. Int J Sci Res Dev 3(9):865–867
Shuja J, Gani A, Shamshirband S, Ahmad RW, Bilal K (2016) Sustainable cloud data centers: a survey of enabling techniques and technologies. Renew Sustain Energy Rev 62:195–214
Skourletopoulos G, Mavromoustakis CX, Mastorakis G, Batalla JM, Song H, Sahalos JN, Pallis E (2018) Elasticity debt analytics exploitation for green mobile cloud computing: an equilibrium model. IEEE Trans Green Commun Netw 3(1):122–131
Šmite D, Wohlin C, Aurum A, Jabangwe R, Numminen E (2013) Offshore insourcing in software development: structuring the decision-making process. J Syst Softw 86(4):1054–1067
Sriram G (2022) Green cloud computing: an approach towards sustainability. Int Res J Modernization Eng Technol Sci 4(1):1263–1268
Wajid U, Pernici B, Francis G (2013) Energy efficient and CO 2 aware cloud computing: requirements and case study. In: Proceedings of the 2013 IEEE international conference on systems, man, and cybernetics. IEEE, pp 121–126
Xu Y, Abnoosian K (2022) A new metaheuristic-based method for solving the virtual machines migration problem in the green cloud computing. Concurr Comput Pract Exp 34(3):e6579
Yin RK (2009) Case study research: design and methods. Sage, Thousand Oaks
Download references
Acknowledgements
This work was supported in part by the National Research Foundation of Korea (NRF) grant 2022R1G1A1003531, 2022R1A4A3018824, RS-2023-00230593 and Institute of Information and Communications Technology Planning and Evaluation (IITP) grant ITP-2023-2020-0-01741, RS-2022-00155885 funded by the Korea government (MSIT).
Author information
Authors and affiliations.
Software-Engineering-Research-Group (SERG-UOM), Department of Computer Science and IT, University of Malakand, Chakdara, Pakistan
Ashfaq Ahmad, Rafiq Ahmad Khan & Siffat Ullah Khan
School of Software, Northwestern Polytechnical University, Chang’an, Xian, 710129, Shaanxi, People’s Republic of China
Rafiq Ahmad Khan
College of Computer and Information Sciences, Jouf University, Sakaka, Saudi Arabia
Hathal Salamah Alwageed
Department of Computer Science, Applied College, University of Tabuk, 47512, Tabuk, Saudi Arabia
Abdullah A. Al-Atawi
Department of Robotics, Hanyang University, Ansan, 15588, Korea
Youngmoon Lee
You can also search for this author in PubMed Google Scholar
Contributions
AA conducted SLR and the RAK and SUK reviewed all its steps. HSA and AAA randomly review all the extracted data from the SLR process. In the second step, AA conducted an empirical study. The RAK and YL conduct the pilot study. AAA and YL synthesis and validate the data accordingly.
Corresponding authors
Correspondence to Rafiq Ahmad Khan or Youngmoon Lee .
Ethics declarations
Conflict of interest.
The authors declare no competing interests.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix 1: Empirical investigation of green cloud computing challenges faced by client organization

Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Reprints and permissions
About this article
Ahmad, A., Khan, R.A., Khan, S.U. et al. Green cloud computing adoption challenges and practices: a client’s perspective-based empirical investigation. Cogn Tech Work 25 , 427–446 (2023). https://doi.org/10.1007/s10111-023-00734-6
Download citation
Received : 08 April 2023
Accepted : 20 July 2023
Published : 11 August 2023
Issue Date : November 2023
DOI : https://doi.org/10.1007/s10111-023-00734-6
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Green cloud computing
- Empirical study
Advertisement
- Find a journal
- Publish with us
- Track your research
Cloud computing service models: A comparative study
Ieee account.
- Change Username/Password
- Update Address
Purchase Details
- Payment Options
- Order History
- View Purchased Documents
Profile Information
- Communications Preferences
- Profession and Education
- Technical Interests
- US & Canada: +1 800 678 4333
- Worldwide: +1 732 981 0060
- Contact & Support
- About IEEE Xplore
- Accessibility
- Terms of Use
- Nondiscrimination Policy
- Privacy & Opting Out of Cookies
A not-for-profit organization, IEEE is the world's largest technical professional organization dedicated to advancing technology for the benefit of humanity. © Copyright 2024 IEEE - All rights reserved. Use of this web site signifies your agreement to the terms and conditions.
Moving past gen AI’s honeymoon phase: Seven hard truths for CIOs to get from pilot to scale
The honeymoon phase of generative AI (gen AI) is over. As most organizations are learning, it is relatively easy to build gee-whiz gen AI pilots, but turning them into at-scale capabilities is another story. The difficulty in making that leap goes a long way to explaining why just 11 percent of companies have adopted gen AI at scale, according to our latest tech trends research. 1 “McKinsey Technology Trends Outlook 2024,” forthcoming on McKinsey.com.
About the authors
This article is a collaborative effort by Aamer Baig , Douglas Merrill , and Megha Sinha, with Danesha Mead and Stephen Xu, representing views from McKinsey Technology and QuantumBlack, AI by McKinsey.
This maturing phase is a welcome development because it gives CIOs an opportunity to turn gen AI’s promise into business value. Yet while most CIOs know that pilots don’t reflect real-world scenarios—that’s not really the point of a pilot, after all—they often underestimate the amount of work that needs to be done to get gen AI production ready. Ultimately, getting the full value from gen AI requires companies to rewire how they work , and putting in place a scalable technology foundation is a key part of that process.
Three approaches to using gen AI
There are three primary approaches to take in using gen AI:
- In “Taker” use cases, companies use off-the-shelf, gen AI–powered software from third-party vendors such as GitHub Copilot or Salesforce Einstein to achieve the goals of the use case.
- In “Shaper” use cases, companies integrate bespoke gen AI capabilities by engineering prompts, data sets, and connections to internal systems to achieve the goals of the use case.
- In “Maker” use cases, companies create their own LLMs by building large data sets to pre-train models from scratch. Examples include OpenAI, Anthropic, Cohere, and Mistral AI.
Most companies will turn to some combination of Taker, to quickly access a commodity service, and Shaper, to build a proprietary capability on top of foundation models. The highest-value gen AI initiatives, however, generally rely on the Shaper approach. 1 For more on the three approaches, see “ Technology’s generational moment with generative AI: A CIO and CTO guide ,” McKinsey, July 11, 2023.
We explored many of the key initial technology issues in a previous article . 2 “ Technology’s generational moment with generative AI: A CIO and CTO guide ,” McKinsey, July 11, 2023. In this article, we want to explore seven truths about scaling gen AI for the “Shaper” approach, in which companies develop a competitive advantage by connecting large language models (LLMs) to internal applications and data sources (see sidebar “Three approaches to using gen AI” for more). Here are seven things that Shapers need to know and do:
- Eliminate the noise, and focus on the signal. Be honest about what pilots have worked. Cut down on experiments. Direct your efforts toward solving important business problems.
- It’s about how the pieces fit together, not the pieces themselves. Too much time is spent assessing individual components of a gen AI engine. Much more consequential is figuring out how they work together securely.
- Get a handle on costs before they sink you. Models account for only about 15 percent of the overall cost of gen AI applications. Understand where the costs lurk, and apply the right tools and capabilities to rein them in.
- Tame the proliferation of tools and tech. The proliferation of infrastructures, LLMs, and tools has made scaled rollouts unfeasible. Narrow down to those capabilities that best serve the business, and take advantage of available cloud services (while preserving your flexibility).
- Create teams that can build value, not just models. Getting to scale requires a team with a broad cross-section of skills to not only build models but also make sure they generate the value they’re supposed to, safely and securely.
- Go for the right data, not the perfect data. Targeting which data matters most and investing in its management over time has a big impact on how quickly you can scale.
- Reuse it or lose it. Reusable code can increase the development speed of generative AI use cases by 30 to 50 percent.
1. Eliminate the noise, and focus on the signal
Although many business leaders acknowledge the need to move past pilots and experiments, that isn’t always reflected in what’s happening on the ground. Even as gen AI adoption increases, examples of its real bottom-line impact are few and far between. Only 15 percent of companies in our latest AI survey say they are seeing use of gen AI have meaningful impact on their companies’ EBIT. 3 That is, they attribute 5 percent or more of their organizations’ EBIT to gen AI use. McKinsey Global Survey on the state of AI in early 2024, February 22 to March 5, 2024, forthcoming on McKinsey.com.
Exacerbating this issue is that leaders are drawing misleading lessons from their experiments. They try to take what is essentially a chat interface pilot and shift it to an application—the classic “tech looking for a solution” trap. Or a pilot might have been deemed “successful,” but it was not applied to an important part of the business.
There are many reasons for failing to scale, but the overarching one is that resources and executive focus are spread too thinly across dozens of ongoing gen AI initiatives. This is not a new development. We’ve seen a similar pattern when other technologies emerged, from cloud to advanced analytics. The lessons from those innovations, however, have not stuck.
The most important decision a CIO will need to make is to eliminate nonperforming pilots and scale up those that are both technically feasible and promise to address areas of the business that matter while minimizing risk (Exhibit 1). The CIO will need to work closely with business unit leaders on setting priorities and handling the technical implications of their choices.
2. It’s about how the pieces fit together, not the pieces themselves
In many discussions, we hear technology leaders belaboring decisions around the component parts required to deliver gen AI solutions—LLMs, APIs, and so on. What we are learning, however, is that solving for these individual pieces is relatively easy and integrating them is anything but. This creates a massive roadblock to scaling gen AI.

Creating value beyond the hype
Let’s deliver on the promise of technology from strategy to scale.
The challenge lies in orchestrating the range of interactions and integrations at scale. Each use case often needs to access multiple models, vector databases, prompt libraries, and applications (Exhibit 2). Companies have to manage a variety of sources (such as applications or databases in the cloud, on-premises, with a vendor, or a combination), the degree of fidelity (including latency and resilience), and existing protocols (for example, access rights). As a new component is added to deliver a solution, it creates a ripple effect on all the other components in the system, adding exponential complexity to the overall solution.
Main components for gen AI model orchestration
Orchestration is the process of coordinating various data, transformation, and AI components to manage complex AI workflows. The API (or LLM) gateway layer serves as a secure and efficient interface between users or applications and underlying gen AI models. The orchestration engine itself is made up of the following components:
- Prompt engineering and prompt library: Prompt engineering is the process of crafting input prompts or queries that guide the behavior and output of AI models. A prompt library is a collection of predefined prompts that users can leverage as best practices/shortcuts when they invoke a gen AI model.
- Context management and caching: Context management highlights background information relevant to a specific task or interaction. Caching relates to storing previously computed results or intermediate data to accelerate future computations.
- Information retrieval (semantic search and hybrid search): Information-retrieval logic allows gen AI models to search for and retrieve relevant information from a collection of documents or data sources.
- Evaluation and guardrails: Evaluation and guardrail tools help assess the performance, reliability, and ethical considerations of AI models. They also provide input to governance and LLMOps. This encompasses tools and processes for evaluating model accuracy, robustness, fairness, and safety.
The key to effective orchestration is embedding the organization’s domain and workflow expertise into the management of the step-by-step flow and sequencing of the model, data, and system interactions of an application running on a cloud foundation . The core component of an effective orchestration engine is an API gateway, which authenticates users, ensures compliance, logs request-and-response pairs (for example, to help bill teams for their usage), and routes requests to the best models, including those offered by third parties. The gateway also enables cost tracking and provides risk and compliance teams a way to monitor usage in a scalable way. This gateway capability is crucial for scale because it allows teams to operate independently while ensuring that they follow best practices (see sidebar “Main components for gen AI model orchestration”).
The orchestration of the many interactions required to deliver gen AI capabilities, however, is impossible without effective end-to-end automation. “End-to-end” is the key phrase here. Companies will often automate elements of the workflow, but the value comes only by automating the entire solution, from data wrangling (cleaning and integration) and data pipeline construction to model monitoring and risk review through “policy as code.” Our latest research has shown that gen AI high performers are more than three times as likely as their peers to have testing and validation embedded in the release process for each model. 4 We define gen AI high performers as those who attribute more than 10 percent of their organizations’ EBIT to their use of gen AI. McKinsey Global Survey on the state of AI in early 2024, February 22 to March 5, 2024, forthcoming on McKinsey.com. A modern MLOps platform is critical in helping to manage this automated flow and, according to McKinsey analysis, can accelerate production by ten times as well as enable more efficient use of cloud resources.
Gen AI models can produce inconsistent results, due to their probabilistic nature or the frequent changes to underlying models. Model versions can be updated as often as every week, which means companies can’t afford to set up their orchestration capability and let it run in the background. They need to develop hyperattentive observing and triaging capabilities to implement gen AI with speed and safety . Observability tools monitor the gen AI application’s interactions with users in real time, tracking metrics such as response time, accuracy, and user satisfaction scores. If an application begins to generate inaccurate or inappropriate responses, the tool alerts the development team to investigate and make any necessary adjustments to the model parameters, prompt templates, or orchestration flow.
3. Get a handle on costs before they sink you
The sheer scale of gen AI data usage and model interactions means costs can quickly spiral out of control. Managing these costs will have a huge impact on whether CIOs can manage gen AI programs at scale. But understanding what drives costs is crucial to gen AI programs. The models themselves, for example, account for only about 15 percent of a typical project effort . 5 “ Generative AI in the pharmaceutical industry: Moving from hype to reality ,” McKinsey, January 9, 2024. LLM costs have dropped significantly over time and continue to decline.
CIOs should focus their energies on four realities:
Change management is the biggest cost. Our experience has shown that a good rule of thumb for managing gen AI costs is that for every $1 spent on developing a model, you need to spend about $3 for change management. (By way of comparison, for digital solutions, the ratio has tended to be closer to $1 for development to $1 for change management . 6 Eric Lamarre, Kate Smaje, and Rodney Zemmel, “ Rewired to outcompete ,” McKinsey, June 20, 2023. ) Discipline in managing the range of change actions, from training your people to role modeling to active performance tracking, is crucial for gen AI. Our analysis has shown that high performers are nearly three times more likely than others to have a strong performance-management infrastructure, such as key performance indicators (KPIs), to measure and track value of gen AI. They are also twice as likely to have trained nontechnical people well enough to understand the potential value and risks associated with using gen AI at work. 7 McKinsey Global Survey on the state of AI in early 2024, February 22 to March 5, 2024, forthcoming on McKinsey.com.
Companies have been particularly successful in handling the costs of change management by focusing on two areas: first, involving end users in solution development from day one (too often, companies default to simply creating a chat interface for a gen AI application), and second, involving their best employees in training models to ensure the models learn correctly and quickly.
- Run costs are greater than build costs for gen AI applications. Our analysis shows that it’s much more expensive to run models than to build them. Foundation model usage and labor are the biggest drivers of that cost. Most of the labor costs are for model and data pipeline maintenance. In Europe, we are finding that significant costs are also incurred by risk and compliance management.
- Driving down model costs is an ongoing process. Decisions related to how to engineer the architecture for gen AI, for example, can lead to cost variances of 10 to 20 times, and sometimes more than that. An array of cost-reduction tools and capabilities are available, such as preloading embeddings. This is not a one-off exercise. The process of cost optimization takes time and requires multiple tools, but done well, it can reduce costs from a dollar a query to less than a penny (Exhibit 3).
- Investments should be tied to ROI. Not all gen AI interactions need to be treated the same, and they therefore shouldn’t all cost the same. A gen AI tool that responds to live questions from customers, for example, is critical to customer experience and requires low-latency rates, which are more expensive. But code documentation tools don’t have to be so responsive, so they can be run more cheaply. Cloud plays a crucial rule in driving ROI because its prime source of value lies in supporting business growth, especially supporting scaled analytics solutions. The goal here is to develop a modeling discipline that instills an ROI focus on every gen AI use case without getting lost in endless rounds of analysis.

A generative AI reset: Rewiring to turn potential into value in 2024
4. tame the proliferation of tools and tech.
Many teams are still pushing their own use cases and have often set up their own environments, resulting in companies having to support multiple infrastructures, LLMs, tools, and approaches to scaling. In a recent McKinsey survey, in fact, respondents cited “too many platforms” as the top technology obstacle to implementing gen AI at scale. 8 McKinsey survey on generative AI in operations, November 2023. The more infrastructures and tools, the higher the complexity and cost of operations, which in turn makes scaled rollouts unfeasible. This state of affairs is similar to the early days of cloud and software as a service (SaaS), when accessing the tech was so easy—often requiring no more than a credit card—that a “wild west” of proliferating tools created confusion and risk.
To get to scale, companies need a manageable set of tools and infrastructures. Fair enough—but how do you know which providers, hosts, tools, and models to choose? The key is to not waste time on endless rounds of analysis on decisions that don’t matter much (for example, the choice of LLMs is less critical as they increasingly become a commodity) or where there isn’t much of a choice in the first place—for example, if you have a primary cloud service provider (CSP) that has most of your data and your talent knows how to work with the CSP, you should probably choose that CSP’s gen AI offering. Major CSPs, in fact, are rolling out new gen AI services that can help companies improve the economics of some use cases and open access to new ones. How well companies take advantage of these services depends on many variables, including their own cloud maturity and the strength of their cloud foundations.
What does require detailed thinking is how to build your infrastructure and applications in a way that gives you the flexibility to switch providers or models relatively easily. Consider adopting standards widely used by providers (such as KFServing, a serverless solution for deploying gen AI models), Terraform for infrastructure as code, and open-source LLMs.
It’s worth emphasizing that overengineering for flexibility eventually leads to diminishing returns. A plethora of solutions becomes expensive to maintain, making it difficult to take full advantage of the services providers offer.
5. Create teams that can build value, not just models
One of the biggest issues companies are facing is that they’re still treating gen AI as a technology program rather than as a broad business priority. Past technology efforts demonstrate, however, that creating value is never a matter of “just tech.” For gen AI to have real impact, companies have to build teams that can take it beyond the IT function and embed it into the business. Past lessons are applicable here, too. Agile practices sped up technical development, for example. But greater impact came only when other parts of the organization—such as risk and business experts—were integrated into the teams along with product management and leadership.
There are multiple archetypes for ensuring this broader organizational integration. Some companies have built a center of excellence to act as a clearinghouse to prioritize use cases, allocate resources, and monitor performance. Other companies split strategic and tactical duties among teams. Which archetype makes sense for any given business will depend on its available talent and local realities. But what’s crucial is that this centralized function enables close collaboration between technology, business, and risk leads, and is disciplined in following proven protocols for driving successful programs. Those might include, for example, quarterly business reviews to track initiatives against specific objectives and key results (OKRs), and interventions to resolve issues, reallocate resources, or shut down poor-performing initiatives.
A critical role for this governing structure is to ensure that effective risk protocols are implemented and followed. Build teams, for example, need to map the potential risks associated with each use case; technical and “human-in-the-loop” protocols need to be implemented throughout the use-case life cycle. This oversight body also needs a mandate to manage gen AI risk by assessing exposures and implementing mitigating strategies.
One issue to guard against is simply managing the flow of tactical use cases, especially where the volume is large. This central organization needs a mandate to cluster related use cases to ensure large-scale impact and drive large ideas. This team needs to act as the guardians for value, not just managers of work.
One financial services company put in place clearly defined governance protocols for senior management. A steering group, sponsored by the CIO and chief strategy officer, focused on enterprise governance, strategy, and communication, driving use-case identification and approvals. An enablement group, sponsored by the CTO, focused on decisions around data architecture, data science, data engineering, and building core enabling capabilities. The CTO also mandated that at least one experienced architect join a use-case team early in their process to ensure the team used the established standards and tool sets. This oversight and governance clarity was crucial in helping the business go from managing just five to more than 50 use cases in its pipeline.
6. Go for the right data, not the perfect data
About quantumblack, ai by mckinsey.
QuantumBlack, McKinsey’s AI arm, helps companies transform using the power of technology, technical expertise, and industry experts. With thousands of practitioners at QuantumBlack (data engineers, data scientists, product managers, designers, and software engineers) and McKinsey (industry and domain experts), we are working to solve the world’s most important AI challenges. QuantumBlack Labs is our center of technology development and client innovation, which has been driving cutting-edge advancements and developments in AI through locations across the globe.
Misconceptions that gen AI can simply sweep up the necessary data and make sense of it are still widely held. But high-performing gen AI solutions are simply not possible without clean and accurate data, which requires real work and focus. The companies that invest in the data foundations to generate good data aim their efforts carefully.
Take the process of labeling, which often oscillates between seeking perfection for all data and complete neglect. We have found that investing in targeted labeling—particularly for the data used for retrieval-augmented generation (RAG)—can have a significant impact on the quality of answers to gen AI queries. Similarly, it’s critical to invest the time to grade the importance of content sources (“authority weighting”), which helps the model understand the relative value of different sources. Getting this right requires significant human oversight from people with relevant expertise.
Because gen AI models are so unstable, companies need to maintain their platforms as new data is added, which happens often and can affect how models perform. This is made vastly more difficult at most companies because related data lives in so many different places. Companies that have invested in creating data products are ahead of the game because they have a well-organized data source to use in training models over time.
At a materials science product company, for example, various teams accessed product information, but each one had a different version. R&D had materials safety sheets, application engineering teams (tech sales/support teams) developed their own version to find solutions for unique client calls, commercialization teams had product descriptions, and customer support teams had a set of specific product details to answer queries. As each team updated its version of the product information, conflicts emerged, making it difficult for gen AI models to use the data. To address this issue, the company is putting all relevant product information in one place.
7. Reuse it or lose it
Reusable code can increase the development speed of generative AI use cases by 30 to 50 percent . 9 Eric Lamarre, Alex Singla, Alexander Sukharevsky, and Rodney Zemmel, “ A generative AI reset: Rewiring to turn potential into value in 2024 ,” McKinsey, March 4, 2024. But in their haste to make meaningful breakthroughs, teams often focus on individual use cases, which sinks any hope for scale. CIOs need to shift the business’s energies to building transversal solutions that can serve many use cases. In fact, we have found that gen AI high performers are almost three times as likely as their peers to have gen AI foundations built strategically to enable reuse across solutions. 10 McKinsey Global Survey on the state of AI in early 2024, February 22 to March 5, 2024, forthcoming on McKinsey.com.
In committing to reusability, however, it is easy to get caught in building abstract gen AI capabilities that don’t get used, even though, technically, it would be easy to do so. A more effective way to build up reusable assets is to do a disciplined review of a set of use cases, typically three to five, to ascertain their common needs or functions. Teams can then build these common elements as assets or modules that can be easily reused or strung together to create a new capability. Data preprocessing and ingestion, for example, could include a data-chunking mechanism, a structured data-and-metadata loader, and a data transformer as distinct modules. One European bank reviewed which of its capabilities could be used in a wide array of cases and invested in developing a synthesizer module, a translator module, and a sentiment analysis module.
CIOs can’t expect this to happen organically. They need to assign a role, such as the platform owner, and a cross-functional team with a mandate to develop reusable assets for product teams (Exhibit 4), which can include approved tools, code, and frameworks.
The value gen AI could generate is transformational. But capturing the full extent of that value will come only when companies harness gen AI at scale. That requires CIOs to not just acknowledge hard truths but be ready to act on them to lead their business forward.
Aamer Baig is a senior partner in McKinsey’s Chicago office, Douglas Merrill is a partner in the Southern California office, Megha Sinha is a partner in the Bay Area office, Danesha Mead is a consultant in the Denver office, and Stephen Xu is director of product management in the Toronto office.
The authors wish to thank Mani Gopalakrishnan, Mark Gu, Ankur Jain, Rahil Jogani, and Asin Tavakoli for their contributions to this article.
This article was edited by Barr Seitz, an editorial director in the New York office.
Explore a career with us
Related articles.

Driving innovation with generative AI

Implementing generative AI with speed and safety

Technology’s generational moment with generative AI: A CIO and CTO guide
- Skip to main content
- Skip to search
- Skip to footer
Products and Services
Contact cisco.
To get global contact information, please make your selections in the drop-down menus.
Country/region and language
Get in touch
Please reach out to sales for general inquiries or to chat with a live agent.
Sales inquiries
1 800 553 6387 , press 1
Order and billing
1 800 553 6387 , press 2-1
Monday to Friday 8 a.m. to 5 p.m. Eastern Time Chat is available to you 24/7.
Find technical support for products and licensing, access to support case manager, and chat with support assistant. Technical support is available 24/7.
Enterprise and service providers
1 800 553 2447 (U.S. and Canada)
Small business
1 866 606 1866 (U.S. and Canada)
Training and certifications
1 800 553 6387 , press 4
Explore support
Explore certification support
Cisco partners
Become a partner, locate a partner, get updates, and partner support.
Explore Cisco partners
Get partner support
Find a Cisco office
Find offices around the world.
Locate offices
Corporate headquarters
300 East Tasman Drive San Jose, CA 95134
Legal mailing address
Cisco Systems, Inc. 170 West Tasman Drive San Jose, California 95134

Complete the form below or log in and the form will autofill. One of our sales specialists will call you within 15 minutes or on a date or time you request. Specialists are available Monday through Friday, 8 a.m. to 5 p.m. Eastern Time. We are currently experiencing delays in response times. If you require an immediate sales response – please call us 1 800-553-6387. Otherwise, a sales advisor will call you as soon as possible. * Required
Want to use a different email? Sign out * Required
IMAGES
VIDEO
COMMENTS
The expansion in demand and commercial availability of cloud services brings new challenges to cloud services selection. Several research studies have been conducted to develop enhanced methodologies to assist service consumers in selecting appropriate services. In this paper, 105 primary studies published during January, 2011 to May, 2022 has ...
This paper presents a meta-analysis of cloud computing research in information systems with the aim of taking stock of literature and their associated research frameworks, research methodology, geographical distribution, level of analysis as well as trends of these studies over the period of 7 years. ... The cloud service models are deployed to ...
Previous studies focused strongly on cloud service selection or SLA negotiation rather than functionally desired SaaS adoption from the perspective of the hybrid cloud provider as integrator. This research paper identifies economic and technical issues in hybrid cloud arising from SaaS adoption and discusses challenges and existing solutions.
review is thought to inspire enterprises and managers that would like to use cloud computing in. terms of the scope, solution methods, factors, dimensions, and the results achieved in a holistic ...
This paper provides a review study on the cloud computing as well. identifying 25-key factors to fulfil better practice in cl oud computing and wa y of making the. environment of the cloud ...
Due to growing network data dissemination in cloud, the elasticity, pay as you go options, globally accessible facilities, and security of networks have become increasingly important in today's world. Cloud se... R. Julian Menezes, P. Jesu Jayarin and A. Chandra Sekar. Journal of Cloud Computing 2024 13 :101.
Resources and services offered on the cloud have rapidly changed in the last decade. These changes were underpinned by industry and academia led efforts towards realising computing as a utility [1].This vision has been achieved, but there are continuing changes in the cloud computing landscape which this paper aims to present.
The journal publishes research that addresses the entire Cloud stack, and as relates Clouds to wider paradigms and topics. ... 1.711 - SNIP (Source Normalized Impact per Paper) 0.976 - SJR (SCImago Journal Rank) ... ISSN: 2192-113X (electronic) Benefit from our free funding service. We offer a free open access support service to make it easier ...
The traditional use of cloud services, focused on the consumption of one provider, is not valid anymore due to different shortcomings being the risk of vendor lock-in a critical. ... Figure 10 shows the distribution of publications per types of research, namely solution proposal, validation research, opinion paper, experience paper or ...
Metrics. Since 2012, the Journal of Cloud Computing has been promoting research and technology development related to Cloud Computing, as an elastic framework for provisioning complex infrastructure services on-demand, including service models such as Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Software as a Service ...
The paper further compares and reviews different layout model for the discovery of services, selection of services and composition of services in Cloud computing. Recent research trends in service composition are identified and then research about microservices are evaluated and shown in the form of table and graphs. Download Full-text.
It has been in high growth after Tencent Cloud as a separate project in 2012. Tencent Cloud has always been slower than AliYun in terms of development due to the lack of business experience. Tencent has a wide range of cloud computing services, including Cloud Virtual Machine, GPU Cloud Computing, CVM Dedicated Host, Auto Scaling, and Batch ...
from 2006, cloud computing became famous and interested to. marketing terms to represent a lot of various ideas [4]. This. study deeply explain the three type of service models in cloud. computing ...
combination of telecommunication and cloud computing.[2] This paper's comparative results show that the features of each cloud storage system play a significant role in the decision-making process when switching to cloud services.[3] From an economic standpoint, this paper compares several cloud service providers.
Reliability and high availability have always been a major concern in distributed systems. Providing highly available and reliable services in cloud computing is essential for maintaining customer confidence and satisfaction and preventing revenue losses. Although various solutions have been proposed for cloud availability and reliability, but there are no comprehensive studies that completely ...
Recent years have seen the massive migration of enterprise applications to the cloud. One of the challenges posed by cloud applications is Quality-of-Service (QoS) management, which is the problem of allocating resources to the application to guarantee a service level along dimensions such as performance, availability and reliability. This paper aims at supporting research in this area by ...
This paper presents the results of an exploratory study on the performance and availability of two prominent Infrastructure as Code (IaC) tools - Google Cloud Deployment Manager and Terraform.
Cloud computing has recently emerged as a new paradigm for hosting and delivering services over the Internet. Cloud computing is attractive to business owners as it eliminates the requirement for users to plan ahead for provisioning, and allows enterprises to start from the small and increase resources only when there is a rise in service demand. However, despite the fact that cloud computing ...
The expansion in demand and commercial availability of cloud services brings new challenges to cloud services selection. Several research studies have been conducted to develop enhanced methodologies to assist service consumers in selecting appropriate services. In this paper, 105 primary studies published during January, 2011 to May, 2022 has ...
The authors in have conducted a systematic exploration of serverless computing-related research papers. As they mentioned, their work is not a survey, but it is a supporting source for future research papers. They proposed an open dataset for serverless computing papers. The dataset includes 60 papers for the period (2016-July 2018).
The rest of this paper is arranged as follows: ... Rawas S, Itani W, Zaart A, Zekri A (2015) Towards greener services in cloud computing: research and future directives. In: Proceedings of the 2015 international conference on applied research in computer science and engineering (ICAR). IEEE, pp 1-8
Cloud computing still suffer of many security issues that required the researchers to focus on it to make the users fully trust on it. In this paper we explain the security issues which attached to each service models Software as a service (SaaS), Platform as a service (PaaS) and Infrastructure as a service (IaaS). Furthermore, a comparative study has been presented for the three service ...
The main aim and objective of t he paper entitled 'Cloud Service Providers: An Analysis of Current and. Emerging Organizations and I ndustries' is including but not lim ited to the following ...
This paper explores Quality of Service (QoS) prediction... 1. Cloud processing offers a flexible platform that permits applications to access required resources before running on Virtual Machines [1]. ... He has published more than 8 research papers in peer-reviewed journals. His area of research includes cloud computing. K. Devaki.
We explored many of the key initial technology issues in a previous article. 2 "Technology's generational moment with generative AI: A CIO and CTO guide," McKinsey, July 11, 2023. In this article, we want to explore seven truths about scaling gen AI for the "Shaper" approach, in which companies develop a competitive advantage by connecting large language models (LLMs) to internal ...
A Feature Paper should be a substantial original Article that involves several techniques or approaches, provides an outlook for future research directions and describes possible research applications. Feature papers are submitted upon individual invitation or recommendation by the scientific editors and must receive positive feedback from the ...
7.1. Challenges. Via analysis and contrast, we observe that cloud computing security protection work has achieved satisfactory research results. However, many problems remain, which prompt the consideration of a variety of security factors and continuous improvements in defense technology and security strategies. 1.
Complete the form below, and one of our sales specialists will call you within 15 minutes or on a date and time you request. Specialists are available Monday through Friday, 8 a.m. to 5 p.m. Eastern Time.We are currently experiencing delays in response times. If you require an immediate sales response - please call us 1 800-553-6387.
group estimated that, by 2020, U.S. organizations that move to the cloud could save $ 12.3 billion in energy costs and the. equivalent of 200 million barrels of oil. In 2009, revenue for cloud ...
Student. , M.Sc. I.T., I.C.S. College, Khed, Ratnagri. Abstract: Cloud Computing has come of age later Amazons introduce the first of its kind of cloud services in2006. It is. particularly ...