- Nom de domaine
- Vérifier un nom de domaine
- Transfert de domaine
- Nom de domaine gratuit
- Certificats SSL
- Créer un site Internet
- Nous créons votre site Internet
- Créer une boutique en ligne
- Hébergement Web
- Hébergement WordPress
- Adresse email professionnelle
- Stockage en ligne HiDrive
- Microsoft 365 / Office 365
- Serveurs Cloud
- Serveurs virtuels (VPS)
- Dedicated Server
- IONOS Cloud
- Générateur de nom d’entreprise
- Générateur de logo
- Favicon Generator
- Vérificateur Whois
- Analyse de Site Web
- Vérificateur d'adresse IP
- Développement web


Qu’est-ce qu’un navigateur Web ?
Que ce soit sur un ordinateur, une tablette ou un smartphone : la voie d’accès à Internet passe généralement par un navigateur Web ou Browser en anglais. Nous utilisons systématiquement Chrome, Mozilla Firefox ou Safari pour consulter des sites Web ou faire des achats en ligne. Mais qu’est-ce qu’un navigateur Web ? Nous expliquons le fonctionnement de ce logiciel et apportons une définition du navigateur Web qui est la véritable passerelle vers Internet.
Définition de navigateur Web
L’élément central du navigateur web : le moteur de rendu, autres modules du navigateur, différences d’affichage dans le navigateur, quels sont les éléments du navigateur , les fonctions supplémentaires utiles dans le navigateur web, quels sont les navigateurs web disponibles et quel est le meilleur.
Un navigateur est un logiciel principalement gratuit qui permet de consulter les pages Internet. À l’aide d’un navigateur Web, des textes, des images, des vidéos, mais aussi des liens et d’autres fonctions d’un site Internet sont affichés . Le terme anglais Browser est dérivé du verbe « to browse » et signifie regarder, feuilleter ou naviguer. Avec l’introduction de l’hypertexte, des références à la navigation ont été ajoutées, appelées hyperliens . Entre-temps, l’éventail des fonctionnalités des navigateurs s’est considérablement élargi : outre les images et les vidéos, des graphiques interactifs, des fichiers audio, des PDF et d’autres ressources peuvent être désormais intégrés et dotés de fonctions.
Comment fonctionne un navigateur Web ?
Avant de répondre précisément à la question « qu’est-ce qu’un navigateur Web ? », il est utile de comprendre le fonctionnement de ce logiciel. Lorsque vous entrez une URL dans votre navigateur, celui-ci demande alors la page au serveur cible. Le serveur répond en renvoyant le contenu sous forme de code HTML, d’images et d’autres ressources. Chaque ressource est identifiée de manière unique par un URI (Uniform Resource Identifier) . À l’aide de certaines spécifications contenues dans les fichiers HTML et CSS , le navigateur interprète tout le contenu et veille à ce que nous puissions visualiser et utiliser le site Web comme d’habitude sur notre écran.

Mais que signifie cette interprétation et comment un navigateur Web fonctionne-t-il sur le plan technique ? Pour pouvoir afficher correctement toutes les ressources, les différents composants effectuent des tâches différentes : derrière ce que nous apercevons, l’interface utilisateur du navigateur, se trouve tout d’abord le moteur du navigateur, qui sert de lien entre l’interface utilisateur et le moteur de rendu .
Ce module est le composant central de la présentation des contenus : par défaut, le moteur peut afficher des fichiers et des images HTML et XML. Toutefois, des ressources supplémentaires sont également possibles avec des plugins appropriés. Par exemple, après qu’un fichier HTML a été demandé, le moteur de rendu l’analyse. Cela signifie que le moteur analyse les données HTML et les convertit en un format que le navigateur peut traiter ultérieurement. D’une part, le moteur de rendu crée la structure DOM, c’est-à-dire la structure du contenu des balises, et d’autre part la structure de rendu , les couleurs et autres critères de mise en page.
Les deux structures sont réunies dans les étapes suivantes : la structure arborescente DOM ou les nœuds individuels sont d’abord positionnés selon des coordonnées exactes. Enfin, la structure de rendu est traitée à l’aide du backend de l’interface utilisateur et permet de visualiser le site Web - cette étape est également appelée « Painting ». « UI » signifie « User Interface », également appelé frontend, c’est-à-dire ce que l’utilisateur voit au final sur l’écran.
En plus du backend de l’interface utilisateur mentionné ci-dessus, qui est responsable de l’affichage des widgets de base tels que les fenêtres, un autre module gère les appels réseau via les protocoles communs tels que HTTP . Un interpréteur JavaScript analyse et exécute le code JavaScript. Une mémoire de données est également fournie en tant que composant persistant, qui stocke, par exemple, les cookies, l’historique du navigateur et le cache local sur l’ordinateur. Cette mémoire est traitée en HTML5 sous la forme d’une mince base de données Web dans le navigateur.
Comme il existe différentes versions de HTML - HTML, XHTML ou HTML5 - et que les différents navigateurs ne les interprètent pas exactement de la même manière, un site Web dans Chrome a parfois un aspect légèrement différent de celui de Firefox. Toutefois, les fonctions de base sont toujours les mêmes, de sorte que vous verrez toujours tous les textes, images et liens - sauf qu’ils peuvent être disposés et affichés légèrement différemment. Ces différences peuvent également se produire si votre navigateur n’est pas à jour. Il est ainsi recommandé de procéder à des mises à jour régulières.
Après avoir répondu à la question « Qu'est-ce qu’un navigateur Web ? », nous examinons les éléments et les fonctions les plus importants. Tous les navigateurs sont dotés d’un équipement de base comprenant les éléments suivants :
- Barre d’adresse pour la saisie de l’URL
- Boutons pour naviguer en avant et en arrière, pour rafraîchir ou recharger et arrêter un processus de chargement
- Bouton d’accès à la page d’accueil du navigateur Web
- Fonction de création de signets
Les autres fonctions varient d’un navigateur à l’autre ou peuvent être ajoutées selon les besoins.
Par ailleurs, des navigateurs comme Firefox ou Safari vous permettent d’organiser vos signets, d’enregistrer des mots de passe ou encore d’utiliser le mode incognito , souvent appelé « navigation privée ». Vous ne laissez ainsi aucune trace visible sur votre propre appareil. Par exemple, votre historique de navigation n’est pas enregistré et les données saisies dans un formulaire ne peuvent pas être reconstituées. En ce qui concerne la sécurité et la protection des données, vous trouverez également une protection contre l’hameçonnage et les logiciels malveillants, ainsi que des bloqueurs de publicité qui sont désormais des fonctionnalités standard de tous les navigateurs courants. Toutefois, ces fonctions ne remplacent pas la protection complète contre les virus , que tout appareil doit au final posséder.
Si certaines fonctions sont manquantes, telles que la possibilité de créer une capture d’écran dans le navigateur ou d’afficher certains contenus, la gamme de fonctions de votre navigateur peut être étendue via des extensions Web et des plugins .
Étant donné que tous les navigateurs fonctionnent fondamentalement de la même manière, il n’est pas vraiment possible de dire quel navigateur est le meilleur. Cela dépend beaucoup plus de vos propres exigences et des habitudes des utilisateurs. Parmi les navigateurs les plus répandus en France, on trouve :
- Mozilla Firefox : l’un des navigateurs Web les plus populaires en Europe.
- Microsoft Internet Explorer & Edge : fait partie intégrante des systèmes d’exploitation Microsoft depuis Windows 95.
- Google Chrome : sur le marché depuis 2008. C’est la référence en matière de synchronisation entre les appareils.
- Safari : le pendant d’Apple pour Internet Explorer et Edge de Microsoft
- Opera : aussi et surtout populaire pour les appareils mobiles.
Nous fournissons des informations plus détaillées sur les différents navigateurs dans l’article « Quel est le meilleur navigateur Web ? » .
Générez votre site en un temps record et obtenez un contenu unique, optimisé par IA.

Qu’est ce qu’un navigateur Web ?
Qu’est ce qu’un navigateur Web ? Quels sont les principaux navigateurs Web ? Présentation de Firefox, Edge, Google Chrome, Safari.
1- Un navigateur web c’est quoi ?
Un navigateur est un outil permettant de naviguer et de consulter les pages web disponibles sur le Word Wide Web . En pratique, le navigateur nous traduit en texte et image les pages d’information qui sont codées en HTML .
En pratique, le navigateur c’est l’équivalent de votre voiture pour vous déplacer sur le réseau routier Internet !

Pour visiter le site www.coursinfo.fr ou www.bnf.fr , vous utilisez un navigateur qui vous permet de vous déplacer sur le réseau routier Internet afin d’y aller.
2- L’interface graphique d’un navigateur web ?
Un navigateu r est une application possédant une interface graphique composée :
- de flèches de navigation, pour naviguer dans l’historique des différents liens visités
- d’une barre d’adresse pour saisir l’adresse d’un site web à consulter
- d’une barre personnelle pour abriter les favoris (raccourci vers des sites web préférés)
- d’une zone d’affichage des pages Web gérée sous forme d’ onglets
- et d’une barre d’état (en bas de fenêtre) pour visualiser l’adresse des hyperliens …

3. Les principaux navigateurs Web
Il existe de nombreux navigateurs Web, mais les plus populaires sont : Firefox de Mozzila, Edge de Microsoft (le remplaçant d’Internet Explorer), Google Chrome et Safari d’Apple. Ils sont tous gratuits .
3.1 Le navigateur Firefox
Firefox , le navigateur de la fondation Mozzila est le plus apprécié des Internautes. C’est aussi le navigateur le plus avancé en terme de fonctionnalités et de sécurité. C’est celui que nous recommendons pour tous.

Cliquez pour télécharger Firefox .
3.2 Le navigateur Edge
Livré avec Windows 10, le navigateur Edge remplace le très célèbre Internet Explorer de Microsoft.

3.3 le navigateur Google Chrome
Google Chrome est certainement le navigateur le plus simple d’utilisation et le plus rapide dans la recherche d’information (c’est fait par Google bien sûr).

3.4 Le navigateur Safari
Safari, le célèbre navigateur web d’ Apple est désormais disponible sur Windows 10. Safari est reconnu pour ses performances exceptionnelles surtout au niveau des développeurs. La vitesse de chargement des pages Web est très rapide.


Qu’est-ce qu’un navigateur Web ? Définition
Dans notre monde connecté, les navigateurs Web sont devenus une partie intégrante de notre vie quotidienne . Mais qu’est-ce exactement qu’un navigateur Web, et comment fonctionne-t-il ? Jetons un œil plus en détail sur le sujet.
Une définition pur commencer
Le worldwideweb (1990) : la genèse du web, mosaic (1993) : l’aube d’une nouvelle ère, netscape navigator (1994) : l’innovateur, internet explorer (1995) : l’empire microsoft, vers de nouvelles frontières : l’évolution continue, mozilla firefox : la liberté et la vie privée, apple safari : l’optimisation pour les utilisateurs d’apple, microsoft edge : une expérience moderne, opera : l’innovation et la personnalisation, brave : la protection de la vie privée au premier plan, vivaldi : pour les utilisateurs avancés, le fonctionnement des navigateurs internet, pour conclure le sujet.
Un navigateur Web , dans son essence, est un outil logiciel qui sert d’interface entre l’utilisateur et l’immense toile d’Internet. Il n’est pas simplement un programme, mais plutôt une fenêtre à travers laquelle nous pouvons explorer , découvrir, et interagir avec une multitude de contenus en ligne.
Qu’il s’agisse de lire les dernières actualités, de regarder des vidéos passionnantes, d’écouter de la musique, de participer à des réseaux sociaux, de faire des achats en ligne, ou même d’accéder à des applications Web complexes comme des suites bureautiques, le navigateur Web est au cœur de ces interactions . Il prend le code souvent complexe qui est envoyé par les serveurs web et le transforme en une présentation visuelle et interactive que nous pouvons comprendre et utiliser.
Une histoire riche et fascinante : Petit voyage au cœur des navigateurs Web
L’histoire des navigateurs Web est un voyage fascinant à travers le temps, marqué par l’innovation, la compétition et la transformation constante sur les bases d’Internet . Voici quelques-uns des moments clés qui ont défini cette histoire :
Développé par Sir Tim Berners-Lee au CERN, WorldWideWeb (également connu sous le nom de Nexus) n’était pas seulement le premier navigateur, mais aussi un éditeur Web. Il marquait la naissance d’un nouveau moyen de partager et d’accéder à l’information, jetant les bases de ce qui deviendrait le World Wide Web.
Mosaic a changé la donne en devenant le premier navigateur grand public. Avec une interface utilisateur graphique et la capacité d’afficher des images, il a transformé le Web d’un outil académique en une plateforme accessible à des millions. Ce fut un tremplin pour l’adoption généralisée d’Internet.
Netscape Navigator a pris le relais et a rapidement dominé le marché. Il a introduit des fonctionnalités comme les cookies et le JavaScript, jetant les bases d’un Web plus interactif et personnalisé. Netscape n’était pas seulement un produit , c’était une icône de la révolution Internet des années 90.
Avec l’arrivée d’Internet Explorer, Microsoft est entré dans la bataille des navigateurs. Intégré à Windows , il est rapidement devenu le navigateur dominant, influençant de nombreuses normes du Web. Sa domination a cependant été critiquée pour avoir freiné l’innovation pendant un certain temps.

L’histoire ne s’arrête pas là. Avec l’introduction de nouvelles technologies et standards, comme HTML5 et CSS3, ainsi que l’émergence de nouveaux acteurs comme Google Chrome et Mozilla Firefox, le paysage des navigateurs continue de se transformer. La compétition stimule l’innovation, et les navigateurs modernes sont plus rapides, plus sûrs, et plus adaptés aux besoins des utilisateurs que jamais.
L’histoire des navigateurs Web est un reflet de la technologie elle-même : dynamique, en constante évolution, et toujours en quête de progrès. C’est un voyage qui continue de pousser le Web vers de nouvelles frontières, façonnant notre façon de vivre, de travailler et de jouer en ligne.
Des exemples actuels de navigateurs Web avec de nombreuses options
Le monde des navigateurs Web a considérablement évolué depuis ses débuts. À l’heure actuelle, les utilisateurs disposent d’une variété de choix, chacun offrant des avantages et des spécialisations uniques. Voici un aperçu de quelques-uns des principaux acteurs du marché :
Google Chrome : La vitesse et la versatilité
Lancé en 2008, Google Chrome est rapidement devenu le navigateur le plus populaire au monde . Réputé pour sa vitesse et sa polyvalence, Chrome offre une multitude de fonctionnalités et d’extensions, permettant une expérience utilisateur hautement personnalisable. Son moteur de rendu, Chromium, est également la base de nombreux autres navigateurs.
Né de la communauté open-source, Mozilla Firefox a toujours mis l’accent sur la liberté et la vie privée. Avec une philosophie transparente et centrée sur l’utilisateur, Firefox propose des fonctionnalités robustes pour protéger les données des utilisateurs et leur offrir un contrôle total sur leur expérience de navigation.
Safari, le navigateur natif d’Apple , est optimisé pour les utilisateurs de Mac, iPhone et iPad. Il offre une intégration transparente avec l’écosystème Apple et met l’accent sur l’efficacité énergétique et la performance. Les utilisateurs d’Apple apprécient souvent sa simplicité et son élégance.
Microsoft Edge , lancé en 2015, marque un tournant pour Microsoft dans la bataille des navigateurs. Basé sur le moteur Chromium, Edge propose une expérience de navigation moderne, avec des fonctionnalités comme le mode lecture et l’intégration de Cortana, l’assistant virtuel de Microsoft. Edge s’intègre également étroitement avec l’écosystème Windows, offrant des fonctionnalités comme la synchronisation des favoris et des mots de passe entre les appareils. De plus, la sécurité et l’accessibilité sont des points forts, avec de nombreuses options de contrôle parental et d’accessibilité pour divers besoins des utilisateurs.
Opera, bien que moins connu que ses concurrents, est un navigateur qui se démarque par son innovation et sa capacité à personnaliser. Depuis son lancement en 1995, Opera a introduit de nombreuses fonctionnalités avant-gardistes , comme la navigation par onglets et la compression de données pour les connexions lentes. Il propose également un VPN gratuit et intégré, permettant une navigation plus sécurisée et privée.
Brave est un navigateur relativement nouveau qui met l’accent sur la protection de la vie privée et la sécurité. Il bloque par défaut les traceurs et les publicités intrusives et offre une expérience de navigation fluide et rapide. En utilisant le système de récompense BAT (Basic Attention Token), Brave cherche à créer un nouveau modèle économique pour soutenir les créateurs de contenu sans sacrifier la confidentialité des utilisateurs .
Vivaldi est conçu pour les utilisateurs avancés qui veulent un contrôle total sur leur expérience de navigation. Avec une interface hautement personnalisable et de nombreuses fonctionnalités avancées, comme les panneaux latéraux et la gestion de sessions, Vivaldi offre une expérience unique pour ceux qui veulent sortir des sentiers battus.

Mais comment ces navigateurs transforment-ils le code en pages Web visuelles ? Voici un aperçu détaillé de chaque étape et de la manière dont elles interagissent dans différents navigateurs :
- Le navigateur décompose l’URL en différents éléments, tels que le protocole (HTTP/HTTPS), le nom d’hôte, le chemin du fichier, etc.
- Il utilise ensuite le protocole DNS ( Domain Name System ) pour convertir le nom d’hôte en adresse IP .
- Le navigateur établit une connexion avec le serveur à cette adresse IP via HTTP ou HTTPS et demande les fichiers.
- Le serveur traite la demande et renvoie les fichiers nécessaires, tels que les fichiers HTML, CSS, JavaScript, images, etc.
- Le serveur peut également renvoyer des informations sur le cache, la nécessité d’une authentification, etc.
- Le navigateur commence à lire le fichier HTML et à construire le DOM ( Document Object Model ), qui représente la structure de la page.
- Le CSS est analysé pour créer le CSSOM (CSS Object Model), qui gère la mise en forme et la présentation.
- Le DOM et le CSSOM sont combinés pour créer le modèle de rendu, qui décrit l’apparence complète de la page.
- Les navigateurs utilisent différents moteurs de rendu pour effectuer ces tâches, par exemple, Blink pour Chrome et Edge, Gecko pour Firefox, et WebKit pour Safari.
- Le navigateur exécute les scripts JavaScript associés à la page, ce qui permet d’ajouter des fonctionnalités interactives, telles que des animations, des réponses aux clics, etc.
- Le JavaScript peut également modifier le DOM et le CSSOM en temps réel, ce qui permet des changements dynamiques de la page sans avoir à recharger.
- Des considérations supplémentaires entrent également en jeu, telles que l’optimisation de la performance, le respect des standards Web, l’accessibilité, etc.
- Les navigateurs peuvent également avoir des fonctionnalités uniques comme la navigation privée, la gestion des extensions, les outils de développement, etc.
Les navigateurs Web sont plus que de simples outils pour afficher des sites Web ; ils sont les complices silencieux de notre exploration quotidienne du Web. Leur histoire fascinante, la diversité des options disponibles aujourd’hui, et la technologie complexe mais élégante qui les alimente, font des navigateurs une merveille moderne.
Que vous soyez un utilisateur quotidien ou un développeur Web en herbe, comprendre ce qu’est un navigateur et comment il fonctionne peut enrichir votre expérience en ligne. Alors la prochaine fois que vous ouvrez un onglet, prenez un moment pour apprécier la puissance et la simplicité de votre navigateur Web.
- Résumé de la politique de confidentialité
- Cookies strictement nécessaires
Ce site utilise des cookies afin que nous puissions vous fournir la meilleure expérience utilisateur possible. Les informations sur les cookies sont stockées dans votre navigateur et remplissent des fonctions telles que vous reconnaître lorsque vous revenez sur notre site Web et aider notre équipe à comprendre les sections du site que vous trouvez les plus intéressantes et utiles.
Cette option doit être activée à tout moment afin que nous puissions enregistrer vos préférences pour les réglages de cookie.
Si vous désactivez ce cookie, nous ne pourrons pas enregistrer vos préférences. Cela signifie que chaque fois que vous visitez ce site, vous devrez activer ou désactiver à nouveau les cookies.
Comment fonctionnent les navigateurs
Dans les coulisses des navigateurs web modernes.
Cet abécédaire complet sur le fonctionnement interne de WebKit et Gecko est le résultat de beaucoup de recherches effectuées par Tali Garsiel, une développeuse israélienne. En quelques années, elle a examiné toutes les données publiées sur les fonctionnements internes du navigateur (voir Ressources ) et a passé beaucoup de temps à lire le code source du navigateur Web. Elle a écrit :
« Dans les années de la domination IE à 90 %, il n'y avait pas grand-chose d'autre à faire que de considérer le navigateur comme une « boite noire ». Mais maintenant, avec des navigateurs open source ayant plus de la moitié de part de marché , c'est le bon moment pour jeter un coup d'œil sous le capot du moteur et voir ce qu'il y a dans un navigateur Web. Eh bien, ce qu'il y a à l'intérieur, ce sont des millions de lignes de C++… »
Tali a publié ses recherches sur son site , mais nous savions qu'elles méritaient un public plus large, donc nous avons tout nettoyé et republié ici.
En tant que développeur Web, apprendre le fonctionnement interne d'un navigateur vous aide à prendre de meilleures décisions et à comprendre les justifications derrière les bonnes pratiques de développement . Bien que ce document soit assez long, nous vous recommandons de passer un peu de temps à creuser dedans, nous vous garantissons que vous en serez heureux (Paul Irish, Chrome Developer Relations).
Cet article a été traduit en coréen par la communauté. HTML5 Rocks héberge les versions en allemand, espagnol, japonais, portugais, russe et chinois simplifié.
Vous pouvez aussi regarder la conférence de Tali Garsiel à ce sujet sur Vimeo.
Article lu fois.
Les sept auteurs et traducteurs
Tali Garsiel
Les 2 auteurs
Les 5 traducteurs

Publié le 5 août 2011 - Mis à jour le 6 février 2013
Version hors-ligne
ePub , Azw et Mobi
1. Introduction ▲
Les navigateurs Web sont probablement les logiciels les plus utilisés. Dans cet abécédaire, je vais vous expliquer comment ils fonctionnent en arrière-plan. Nous allons voir ce qui se passe à partir du moment où vous tapez « google.com » dans la barre d'adresse jusqu'à ce que vous puissiez voir la page de Google dans votre navigateur.
1-1. Les navigateurs dont nous allons parler ▲
De nos jours, il y a cinq navigateurs principaux utilisés - Internet Explorer, Firefox, Safari, Chrome et Opera. Je vais donner des exemples à partir des navigateurs open source - Firefox, Chrome et Safari (qui est partiellement open source). Selon les statistiques de StatCounter browser statistics , actuellement (août 2011), la part d'utilisation de Firefox, Safari et Chrome ensemble est de près de 60 % (NdT pour janvier 2013, cette proportion passe à plus de 66 %). Ainsi, de nos jours, les navigateurs open source sont les plus utilisés.
1-2. La fonctionnalité principale du navigateur ▲
Le but principal d'un navigateur est de présenter la ressource Web que vous choisissez, en faisant la demande à partir du serveur et de l'afficher sur la fenêtre du navigateur. La ressource est généralement un document HTML, mais peut aussi être un PDF, une image ou un autre type. L'emplacement de la ressource est spécifié par l'utilisateur à l'aide d'une URI (Uniform Resource Identifier).
La façon dont le navigateur interprète et affiche les fichiers HTML est précisée dans les spécifications HTML et CSS. Ces spécifications sont maintenues par le l'organisation W3C (World Wide Web Consortium), organisation des normes du Web.
Pendant des années, les navigateurs ne respectaient qu'une partie de ces spécifications et développaient leurs propres extensions. Cela a causé de graves problèmes de compatibilité pour les concepteurs Web. Aujourd'hui, la plupart des navigateurs sont plus ou moins conformes à ces spécifications.
Les interfaces des navigateurs ont beaucoup d'éléments en commun. On y trouve :
- une barre d'adresse pour insérer l'URL ;
- des boutons « Précédent » et « Suivant » ;
- des options de marque-pages ;
- des boutons d'actualisation et d'arrêt pour se rafraîchir et arrêter le chargement des documents courants ;
- un bouton « Accueil » qui vous ramène à votre page d'accueil.
Curieusement, l'interface du navigateur n'est pas spécifiée dans une spécification formelle, il s'agit simplement de bonnes pratiques façonnées au fil des années d'expérience et par l'imitation des autres navigateurs. La spécification HTML5 ne définit pas les éléments d'interface que doit avoir un navigateur, mais énumère certains éléments communs. Parmi celles-ci, la barre d'adresse, la barre d'état et la barre d'outils. Il y a bien sûr les caractéristiques propres à un navigateur spécifique comme le gestionnaire de téléchargements de Firefox.
1-3. La structure haut niveau d'un navigateur ▲
Les principaux composants (voir ) d'un navigateur sont :
- L'interface utilisateur - ce qui inclut la barre d'adresse, les boutons avant et arrière, le menu de marque-page, etc. En fait, chacune des parties affichées par le navigateur excepté la fenêtre principale dans laquelle vous voyez la page demandée ;
- Le moteur du navigateur - contrôle les actions entre l'interface et le moteur de rendu ;
- Le moteur de rendu - responsable de l'affichage du contenu demandé. Par exemple, si le contenu demandé est au format HTML, il est chargé d'analyser le code HTML et CSS et d'afficher le contenu analysé à l'écran ;
- Le réseau - utilisé pour les appels réseau, comme les requêtes HTTP. Il possède une interface indépendante de la plateforme et en dessous des implémentations pour chaque plateforme ;
- L'interface utilisateur - utilisée pour dessiner des widgets de base comme des listes déroulantes et des fenêtres. Le navigateur expose une interface générique qui n'est pas spécifique à la plateforme. En dessous, il utilise l'interface utilisateur du système d'exploitation ;
- L'interpréteur JavaScript - utilisé pour analyser et exécuter le code JavaScript ;
- Le stockage de données - il s'agit d'une couche de persistance. Le navigateur doit enregistrer toutes sortes de données sur le disque dur, par exemple, des cookies. La nouvelle spécification HTML (HTML5) définit le terme « base de données Web », qui est un système complet (bien que léger) de base de données dans le navigateur.

Il est important de noter que Chrome, contrairement à la plupart des navigateurs, crée plusieurs instances du moteur de rendu - une pour chaque onglet. Chaque onglet est un processus distinct.
2. Le moteur de rendu ▲
La responsabilité du moteur de rendu est importante… Le rendu, c'est l'affichage des contenus demandés sur l'écran du navigateur.
Par défaut, le moteur de rendu peut afficher des documents HTML, XML et des images. Il peut afficher d'autres types avec un plug-in (ou extension de navigateur), par exemple, PDF s'affiche en utilisant un plug-in de visualisation de PDF. Cependant, dans ce chapitre, nous nous concentrerons sur le cas d'utilisation principal : affichage de HTML et d'images qui sont formatés à l'aide de CSS.
2-1. Les moteurs de rendu ▲
Nos navigateurs de références Firefox, Chrome et Safari sont construits sur deux moteurs de rendu. Firefox utilise Gecko un moteur « fait maison » de Mozilla. Safari et Chrome utilisent Webkit.
WebKit est un moteur de rendu Open Source qui a commencé comme un moteur de plateforme Linux et a été modifié par Apple pour soutenir Mac et Windows. Voir webkit.org pour plus de détails.
2-2. Le flux principal ▲
Le moteur de rendu commencera à obtenir le contenu du document demandé mis en réseau. Ce sera généralement effectué en morceaux de 8 K.
Après c'est le flux de base du moteur de rendu :

Le moteur de rendu commencera à faire l'analyse du document HTML et activera les mots-clés aux nœuds de dans un arbre appelé « arbre de contenu ». Il analysera les données de style, à la fois dans les fichiers CSS externes et les éléments de style. L'information de style ainsi que des instructions visuelles dans le code HTML seront utilisées pour créer un autre arbre : « ».
L'arbre de rendu contient des rectangles avec des attributs visuels comme les couleurs et les dimensions. Les rectangles sont dans le bon ordre pour être affichés sur l'écran.
Après la construction de l'arbre de rendu, il passe par un processus de « ». Ceci signifie de donner les coordonnées exactes où il devrait apparaître sur l'écran. L'étape suivante : l'arbre de rendu sera traversé et chaque nœud sera dessiné en utilisant la couche d'arrière-plan de l'interface utilisateur.
Il est important de comprendre que c'est un processus graduel. Pour une meilleure expérience utilisateur, le moteur de rendu essayera d'afficher le contenu sur l'écran dès que possible. Il n'attendra pas que tout le code HTML soit analysé avant de commencer à présenter l'arbre de rendu. Les parties du contenu seront analysées et affichées, tandis que le processus se poursuit avec le reste de la page qui continue à arriver du réseau.
2-3. Exemples des flux principaux ▲

À partir des figures 3 et 4, vous pouvez voir que, bien que Webkit et Gecko utilisent une terminologie légèrement différente, le flux est essentiellement le même.
Gecko appelle l'arbre des éléments formatés visuellement un « Frame tree » (arbre de vue). Chaque élément est un cadre. Webkit utilise le terme « arbre de rendu » et il se compose de « Render Objects » (objets de rendu). Webkit utilise le terme « layout » (présentation) pour le placement des éléments, pendant que le Gecko l'appelle « Reflow » (ré-écoulement ). « Attachment » (attachement) est le terme de Webkit pour relier les nœuds de DOM et les informations visuelles afin de créer l'arbre de rendu. Une différence non sémantique mineure est que Gecko a une couche supplémentaire entre le HTML et l'arbre DOM. Il est appelé « content sink » (lavabo de contenu) et est une usine pour faire des éléments DOM. Nous parlerons de chaque partie du flux.
3. Analyse et construction de l'arbre DOM ▲
3-1. l'analyse - généralités ▲.
Comme l'analyse est un processus très important dans le moteur de rendu, nous irons un peu plus dans les détails. Commençons par une petite introduction sur l'analyse.
Analyser un document signifie le traduire en une structure qui fait sens - quelque chose que le code peut comprendre et utiliser. Le résultat de l'analyse est en général un arbre de nœuds qui représente la structure du document. Il est appelé un arbre d'analyse ou un arbre syntaxique.
Exemple - l'analyse de l'expression 2 + 3 - 1 pourrait retourner cet arbre :

3-1-1. Les grammaires ▲
L'analyse est basée sur les règles de syntaxe auxquelles le document obéit - la langue ou le format dans lequel il a été écrit. Chaque format que vous analysez doit avoir une grammaire déterministe constituée d'un vocabulaire et de règles de syntaxe. C'est ce que l'on appelle une grammaire sans contexte . Les langues humaines n'en sont pas et ne peuvent donc pas être analysées avec des techniques d'analyse classiques.
3-1-2. La combinaison Parser - Lexer ▲
L'analyse peut être séparée en deux processus - l'analyse lexicale et l'analyse syntaxique.
L'analyse lexicale est le processus de séparation de l'entrée en mots-clés. Les mots-clés sont le vocabulaire de la langue - la collection de blocs de construction valides. Pour un langage humain, il se compose de tous les mots qui apparaissent dans le dictionnaire de cette langue.
L'analyse syntaxique est l'application des règles de la syntaxe du langage.
Les analyseurs, généralement, divisent le travail entre les deux éléments - l'analyseur lexical (appelé lexer ou tokenizer en langue anglaise) qui est responsable de l'extraction des mots-clés depuis l'entrée et l'analyseur syntaxique qui est responsable de la construction de l'arbre syntaxique par l'analyse de la structure du document selon les règles de syntaxe du langage. L'analyseur lexical sait comment supprimer des caractères non pertinents tels que les espaces et des sauts de ligne.

Le processus d'analyse est itératif. L'analyseur syntaxique demande généralement à l'analyseur lexical le prochain mot-clé et essaye de faire correspondre ce mot-clé avec l'une des règles de syntaxe. Si une règle est trouvée, un nœud correspondant au mot-clé sera ajouté à l'arbre d'analyse et l'analyseur syntaxique demandera un autre mot-clé.
Si aucune règle ne correspond, l'analyseur va stocker le mot-clé en interne et continuer à demander des mots-clés jusqu'à ce qu'une règle de correspondance avec les mots-clés stockés en interne soit trouvée. Si aucune règle n'est trouvée, alors l'analyseur déclenche une exception. Cela signifie que le document n'est pas valide et qu'il contient des erreurs de syntaxe.
3-1-3. La traduction ▲
Souvent, l'arbre d'analyse syntaxique n'est pas le produit final. L'analyse est souvent employée en traduction - la transformation du document d'entrée en un autre format. Un exemple est la compilation. Le compilateur qui compile un code source en code machine analyse d'abord le code avec un arbre d'analyse et traduit ensuite cet arbre dans un document code machine.

3-1-4. Exemple d'analyse ▲
Dans la figure 5, nous avons construit un arbre d'analyse à partir d'une expression mathématique. Essayons de définir un langage mathématique simple et de voir le processus d'analyse.
Vocabulaire : notre langage peut inclure des nombres entiers ainsi que les signes plus et moins.
- Les blocs de construction sont des expressions, des termes et des opérations ;
- Notre langage peut comporter un nombre quelconque d'expressions ;
- Une expression est définie comme un « terme » suivi d'une « opération » suivie par un autre terme ;
- Une opération est un signe plus ou un signe moins ;
- Un terme est un entier ou une expression.
Analysons l'entrée 2 + 3 - 1.
La première chaîne qui correspond à une règle est 2 et conformément à la règle N° 5, c'est un terme. La deuxième correspondance est 2 + 3 cela correspond à la troisième règle - un terme suivi d'une opération suivie par un autre terme. La prochaine correspondance ne sera atteinte qu'à la fin de l'entrée. 2 + 3 - 1 est une expression parce que nous savons déjà que 2 +3 est un terme et que nous avons un terme suivi par une opération suivie par un autre terme. 2 + + ne correspond à aucune règle et n'est donc pas une entrée valide.
3-1-5. Définitions formelles du vocabulaire et de la syntaxe ▲
Le vocabulaire est en général exprimé par des expressions régulières .
Par exemple, notre langage sera défini comme :
Comme vous le voyez, les nombres sont définis par une expression régulière.
La syntaxe est généralement définie dans un format nommé BNF . Notre langage sera défini comme cela :
Nous avons dit qu'un langage peut être analysé par un analyseur normal si sa grammaire est une grammaire sans contexte. La définition intuitive d'une grammaire sans contexte est une grammaire qui peut entièrement être exprimée en format BNF. Pour une définition plus formelle voir l'article Wikipédia sur les grammaires sans contexte .
3-1-6. Les types d'analyseurs ▲
Il y a deux types d'analyseurs - les analyseurs de haut en bas (top down) et les analyseurs de bas en haut (bottom up). Une explication intuitive est que les analyseurs de haut en bas voient la structure de la syntaxe de haut niveau et tentent de faire correspondre l'entrée à l'une des règles. Les analyseurs de bas en haut commencent avec l'entrée et la transforment peu à peu en règles de syntaxe, à partir des règles de bas niveau jusqu'à ce que les règles de haut niveau soient remplies.
Voyons comment ces deux types d'analyseurs vont analyser notre exemple.
Un analyseur de haut en bas commencera à partir de la règle de niveau supérieur - il identifiera 2 + 3 comme une expression. Il identifiera alors 2 + 3 - 1 comme une expression (le processus d'identification de l'expression change pour correspondre avec les autres règles, mais le point de départ est la règle de plus haut niveau).
Un analyseur de bas en haut va lire l'entrée jusqu'à ce qu'une règle corresponde et il remplacera alors l'entrée correspondant à la règle. Et ainsi de suite jusqu'à la fin de l'entrée. L'expression partiellement identifiée est placée sur la pile analyseurs.
| 2 + 3 - 1 | |
| terme | + 3 - 1 |
| terme opération | 3 - 1 |
| expression | - 1 |
| expression opération | 1 |
| expression |
Ce type d'analyseur de bas en haut est appelé analyseur à décalage-réduction, parce que l'entrée est décalée vers la droite (imaginez un pointeur pointant d'abord sur le début de l'entrée puis se déplaçant vers la droite) et est progressivement réduite à des règles de syntaxe.
3-1-7. Générer des analyseurs automatiquement ▲
Il existe des outils qui permettent de générer un analyseur syntaxique pour vous. Ils sont appelés générateurs d'analyseurs. Vous leur fournissez la grammaire de la langue, son vocabulaire et la syntaxe de ses règles, et ils génèrent un analyseur. La création d'un analyseur nécessite une connaissance approfondie de l'analyse et comme il n'est pas facile de créer à la main un analyseur optimisé, ces générateurs d'analyseurs sont donc très utiles.
Webkit utilise deux générateurs d'analyseur bien connus - Flex pour créer l'analyseur lexical et Bison pour la création de l'analyseur syntaxique (vous pourrez aussi les rencontrer avec les termes Lex et Yacc). L'entrée de Flex est un fichier contenant la définition des expressions régulières des mots-clés. L'entrée de Bison est constituée par les règles de syntaxe du langage au format BNF.
3-2. L'analyseur HTML ▲
Le rôle de l'analyseur HTML est d'analyser les balises HTML et de créer un arbre d'analyse.
3-2-1. La définition de la grammaire HTML ▲
Le vocabulaire et la syntaxe du langage HTML sont définis dans des spécifications créées par l'organisation W3C. La version actuelle est HTML4 et le travail sur le HTML5 est en cours.
3-2-2. Ce n'est pas une grammaire sans contexte ▲
Comme nous l'avons vu dans l'introduction sur l'analyse, la syntaxe grammaticale peut être définie de manière formelle en utilisant des formats tels que la BNF.
Malheureusement, la notion d'analyseur conventionnel ne s'applique pas au format HTML (je n'en ai pas parlé juste pour le plaisir, ils seront utilisés lors de l'analyse CSS et JavaScript). HTML ne peut pas être défini facilement avec la grammaire sans contexte dont ont besoin les analyseurs.
Il existe un document officiel pour définir HTML, une DTD (Document Type Definition), mais ce n'est pas une grammaire sans contexte.
Cela semble étrange à première vue ; HTML étant assez proche de XML. Il existe beaucoup d'analyseurs XML disponibles. Il y a une différence entre XML et HTML - XHTML, alors quelle est cette différence ?
La différence est que l'approche HTML est plus « clémente », elle vous permet d'omettre certaines balises qui sont ajoutées implicitement, ou encore le début ou la fin de la balise, etc. Dans l'ensemble c'est une syntaxe « souple », par opposition à la syntaxe « stricte » et « exigeante » de XML.
Apparemment, cette petite différence fait un monde de différence. D'une part, c'est la raison principale pour laquelle HTML est si populaire, il pardonne vos erreurs et facilite la vie aux auteurs Web. D'autre part, il est difficile d'écrire une grammaire formelle. Donc, pour résumer, HTML ne peut pas être analysé facilement, en tout cas pas par des analyseurs conventionnels, puisque sa grammaire n'est pas une grammaire sans contexte, ni par des analyseurs XML.
3-2-3. La DTD HTML ▲
La définition HTML est dans un format DTD. Ce format est utilisé pour définir les langues de la famille SGML. Le format contient les définitions de tous les éléments autorisés, leurs attributs et leur hiérarchie. Comme nous l'avons vu précédemment, la DTD HTML ne constitue pas une grammaire sans contexte.
Il existe quelques variantes de DTD. Le mode strict se conforme uniquement à la norme, mais d'autres modes supportent les formes utilisées par les navigateurs dans le passé. Le but est la rétrocompatibilité avec les anciens contenus. La DTD stricte actuelle se trouve ici : www.w3.org/TR/html4/strict.dtd .
3-2-4. Le DOM ▲
L'arbre de sortie, « l'arbre syntaxique », est constitué de nœuds éléments et attributs DOM. DOM est l'acronyme de « Document Object Model ». Il s'agit de la représentation « objet » du document HTML ainsi que l'interface des éléments HTML avec le monde extérieur comme JavaScript.
La racine de l'arbre est l'objet « document ».
Le DOM possède une relation quasiment un-à-un avec le balisage. Par exemple, ce code :
Se traduirait par l'arbre DOM suivant :

Comme pour HTML, DOM est spécifié par l'organisation W3C , voir www.w3.org/DOM/DOMTR . C'est une spécification générique pour la manipulation de documents. Un document spécifique décrit les éléments propres à HTML. La définition HTML peut être trouvée ici : www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html .
Quand je dis que l'arbre contient des nœuds DOM, je veux dire que l'arbre est constitué d'éléments qui mettent en œuvre l'une des interfaces DOM. Les navigateurs utilisent des implémentations concrètes qui ont d'autres attributs utilisés par le navigateur en interne.
3-2-5. L'algorithme d'analyse ▲
Comme nous l'avons vu auparavant, le langage HTML ne peut pas être analysé en utilisant des analyseurs de bas en haut ou de haut en bas.
Les raisons sont :
- La nature indulgente du langage ;
- Le fait que les navigateurs ont une tolérance traditionnelle aux erreurs pour supporter les cas bien connus de HTML non valide ;
- Le processus d'analyse est réentrant. Habituellement, la source ne change pas pendant l'analyse, mais en HTML, des balises de script contenant document.write peuvent ajouter des entrées supplémentaires, de sorte que le processus d'analyse modifie en fait l'entrée.
Incapables d'utiliser les techniques traditionnelles d'analyse, les navigateurs doivent utiliser des analyseurs personnalisés pour lire le HTML.
L'algorithme d'analyse est décrit en détail par la spécification HTML5 . L'algorithme se compose de deux étapes - la séparation des mots-clés et la construction de l'arbre.
La séparation est l'analyse lexicale, transformer l'entrée en mots-clés. Parmi les mots-clés HTML, on trouve les balises de début, de fin, les noms d'attributs et les valeurs d'attributs.
L'analyse lexicale reconnaît le mot-clé, le donne au constructeur de l'arbre et consomme le caractère suivant pour reconnaître le mot-clé suivant. Et ainsi de suite jusqu'à la fin de l'entrée.

3-2-6. L'algorithme de séparation ▲
La sortie de l'algorithme est un mot-clé HTML. L'algorithme est exprimé comme une machine à états. Chaque état consomme un ou plusieurs caractères du flux d'entrée et met à jour l'état suivant en fonction de ces caractères. La décision est influencée par l'état courant et par l'état de la construction de l'arbre. Cela signifie que le même caractère consommé donnera des états de sortie différents en fonction de l'état courant. L'algorithme est trop complexe pour être décrit entièrement, alors voyons un exemple simple qui nous aidera à comprendre le principe.
Exemple simple, lire le code HTML suivant :
L'état initial est « données ». Lorsque le caractère < est lu, l'état est changé en « ouvert ». Consommer un caractère provoque la création d'un « début de nom », l'état est changé en « nom ». L'état ne change pas jusqu'à ce que le caractère > soit lu, chaque caractère étant ajouté au nom. Dans notre cas, le mot-clé créé est html .
Lorsque le caractère > est atteint, le mot-clé courant est émis et l'état redevient « données ». La balise <body> sera traitée par le même processus. Pour l'instant, les balises html et body ont été émises. Nous sommes maintenant de retour à l'état « données ». Consommer le caractère H de Hello world va provoquer la création et l'émission d'un mot-clé caractère, cela continue jusqu'à ce que le < de </body> soit atteint. Il y aura émission d'un mot-clé caractère pour chaque caractère de Hello world .
Nous sommes maintenant de retour à l'état « ouvert ». Consommer le caractère suivant / provoquera la création d'un mot-clé balise de fin et le passage à l'état « nom ». Encore une fois nous restons dans cet état jusqu'à ce que nous atteignons > . Ensuite le mot-clé est émis et nous revenons à l'état « données ». L'entrée </html> sera traitée comme précédemment.

3-2-7. L'algorithme de construction de l'arbre ▲
Lorsque l'analyseur est créé, l'objet Document est créé. Pendant la phase de construction de l'arbre, l'arbre DOM avec le Document dans sa racine est modifié et les éléments sont ajoutés. Chaque nœud émis par l'analyseur lexical est traité par le constructeur d'arbre. Pour chacun des mots-clés définis par la spécification DOM, un élément DOM sera créé. Sauf s'il est ajouté à l'arbre DOM, il est ajouté à une pile d'éléments ouverts. Cette pile est utilisée pour corriger les déséquilibres d'imbrication et les balises non fermées. L'algorithme est aussi décrit comme une machine à états. Les états sont appelés « modes d'insertion ».
Voyons le processus de construction de l'arbre pour cet exemple :
L'entrée à l'étape de la construction de l'arbre est une séquence de mots-clés issus de l'analyse lexicale. Le premier état est l'état « initial ». La réception du mot-clé html provoquera le passage à l'état « avant html » et un nouveau traitement de ce mot-clé pour ce mode. Cela entraînera la création de l'élément HTMLHtmlElement qui sera ajouté à la racine de l'objet Document.
L'état sera alors changé en « avant head ». Nous recevons ensuite le mot-clé body . Un HTMLHeadElement est créé implicitement, bien que nous n'avons pas de mot-clé head et il est ajouté à l'arbre.
Nous passons maintenant de l'état « dans entête » à « après entête ». Le mot-clé body est traité à nouveau, un HTMLBodyElement est créé et inséré et l'état est ensuite modifié en « dans corps ».
Les mots-clés caractère de la chaîne « Hello world » sont maintenant reçus. Le premier va causer la création et l'insertion d'un nœud text et les autres caractères seront ajoutés à ce nœud.
La réception du mot-clé fin de corps va provoquer le changement d'état « après corps ». Nous allons maintenant recevoir la balise de fin html qui va changer l'état en « après après corps ». La réception du mot-clé fin de fichier termine l'analyse.

3-2-8. Les actions en fin d'analyse ▲
À ce stade, le navigateur va marquer le document comme interactif et lancer l'analyse des scripts marqués comme « différés » - ceux qui doivent être exécutés après que le document a été analysé. L'état document sera alors réglé sur « terminé » et un événement « chargement » est déclenché.
Vous pouvez voir les algorithmes complets pour l'analyse et la construction des arbres dans la spécification HTML5 .
3-2-9. La tolérance aux erreurs des navigateurs ▲
Vous n'aurez jamais une erreur « syntaxe invalide » avec une page HTML. Les navigateurs corrigent les contenus invalides et continuent.
Prenez ce code HTML par exemple :
Je dois avoir violé environ un million de règles ( mytag n'est pas une balise standard, mauvaise imbrication des balises p et div et plus encore), mais le navigateur le montre quand même correctement et ne se plaint pas. Ainsi, beaucoup de code de l'analyseur sert à corriger les erreurs des codeurs HTML.
La gestion des erreurs est tout à fait compatible avec les navigateurs, mais étonnamment, elle ne fait pas partie de la spécification HTML actuelle. Comme les boutons « Favoris », « Précédent » et « Suivant », c'est juste quelque chose qui s'est développé dans les navigateurs au fil des années. On connaît des constructions HTML invalides qui se répètent sur de nombreux sites et les navigateurs essayent de les résoudre d'une manière conforme avec les autres navigateurs.
La spécification HTML5 définit certaines de ces exigences. Webkit résume cela très bien dans les commentaires du début de la classe de l'analyseur HTML.
L'analyseur analyse l'entrée sous forme de mot-clé dans le document, en construisant l'arbre du document. Si le document est bien formé, son analyse est simple.
Malheureusement, nous avons à gérer de nombreux documents HTML qui ne sont pas bien formés de sorte que l'analyseur doit être tolérant avec les erreurs.
Nous devons faire attention au moins aux conditions d'erreur suivantes :
- L'élément ajouté est explicitement interdit à l'intérieur de certaines balises extérieures. Dans ce cas, nous devrions fermer toutes les balises jusqu'à celle qui interdit l'élément et l'ajouter à la suite ;
- Nous ne sommes pas autorisés à ajouter l'élément directement. Il se pourrait que la personne qui écrit le document ait oublié quelques balises entre les deux (ou que la balise entre les deux est en option). Ce pourrait être le cas avec les balises HTML suivantes : HEAD BODY TBODY TR TD LI (en ai-je oublié une ?) ;
- Nous voulons ajouter un élément de bloc à l'intérieur d'un élément en ligne. Fermer tous les éléments en ligne jusqu'au bloc supérieur suivant ;
- Si cela ne fonctionne pas, fermer les éléments jusqu'à être autorisé à ajouter l'élément ou ignorer la balise.
Voyons quelques exemples de tolérance aux erreurs de Webkit.
3-2-9-1. </br> à la place de <br> ▲
Certains sites utilisent </br> au lieu de <br> . De manière à être compatible avec IE et Firefox, Webkit traite cela comme un <br> .
Notez que la gestion d'erreur est interne, elle ne sera pas présentée à l'utilisateur.
3-2-9-2. Une table parasite ▲
Une table parasite est une table à l'intérieur d'une autre, mais pas à l'intérieur d'une cellule.
Comme dans cet exemple :
Webkit va changer la hiérarchie pour deux tables sœurs :
Webkit utilise une pile pour le contenu des éléments courants, il va dépiler la table interne de la table externe, ces tables seront désormais sœurs.
3-2-9-3. Imbrication de formulaires ▲
Dans le cas où un utilisateur met un formulaire à l'intérieur d'un autre, le deuxième est ignoré.
3-2-9-4. Une hiérarchie trop profonde ▲
Ce commentaire parle de lui-même.
www.liceo.edu.mx est l'exemple d'un site qui permet d'atteindre un niveau d'imbrication d'environ 1500 balises <b> . Nous n'autoriserons pas plus de 20 balises imbriquées du même type avant de toutes les ignorer.
3-2-9-5. Balises HTML ou body fermantes mal placées ▲
Encore une fois, le commentaire parle de lui-même.
La prise en charge de HTML vraiment mal formé. Nous ne fermons jamais la balise body , car certaines pages Web stupides la ferment avant la fin réelle du document. Nous nous basons uniquement sur le end() pour tout fermer.
Ainsi, codeurs Web, méfiez-vous, à moins que vous ne souhaitiez apparaître comme un exemple dans un morceau de code de la tolérance aux erreurs de Webkit, écrivez un code HTML bien formé.
3-3. L'analyse CSS ▲
Vous rappelez-vous les concepts de l'analyse dans l'introduction ? Eh bien, contrairement à HTML, CSS est une grammaire sans contexte, elle peut être analysée à l'aide des types d'analyseurs décrits dans l'introduction. En fait, la spécification CSS définit sa grammaire lexicale et syntaxique .
Voyons quelques exemples.
La grammaire lexicale (le vocabulaire) est définie par les expressions régulières pour chaque mot-clé :
La syntaxe de la grammaire est décrite en BNF :
Explication, un jeu de règles possède la structure suivante :
div.error et a.error sont des sélecteurs. La partie à l'intérieur des accolades contient les règles qui sont appliquées par cet ensemble de règles. Cette structure est définie formellement dans cette définition :
Cela signifie qu'un ensemble de règles est un sélecteur ou éventuellement un ensemble de sélecteurs séparés par une virgule et des espaces (S représente un espace). Un jeu de règles contient des accolades et à l'intérieur, une déclaration ou éventuellement un certain nombre de déclarations séparées par un point-virgule. « déclaration » et « sélecteur» seront définis dans les définitions BNF suivantes.
3-3-1. L'analyseur CSS de Webkit ▲
Webkit utilise les générateurs d'analyseur Flex et Bison pour créer des analyseurs de grammaire CSS. Si vous vous souvenez de l'introduction aux analyseurs, Bison créé un analyseur de bas en haut décalage-réduction. Firefox utilise un analyseur de haut en bas écrit manuellement. Dans les deux cas, chaque fichier CSS est analysé dans une feuille de style, chaque objet contient des règles CSS. Les objets de la règle CSS contiennent des objets de sélection et de déclaration ainsi que d'autres objets de la grammaire CSS.

3-4. L'ordre d'analyse des scripts et des feuilles de style ▲
3-4-1. les scripts ▲.
Le modèle du Web est synchrone. Les auteurs s'attendent à ce que les scripts soient analysés et exécutés immédiatement lorsque l'analyseur atteint une balise <script> . L'analyse du document s'arrête jusqu'à ce que le script ait été exécuté. Si le script est externe, alors la ressource doit être d'abord récupérée sur le réseau, ceci est fait aussi de manière synchrone, l'analyse s'arrête jusqu'à ce que la ressource soit récupérée. C'était le modèle durant de nombreuses années et c'est également spécifié dans le HTML 4 et 5. Les auteurs pouvaient marquer le script comme « reporté » et donc il n'interrompait pas l'analyse du document, mais était exécuté après avoir été analysé. HTML5 ajoute une option pour marquer le script comme asynchrone de sorte qu'il soit analysé et exécuté par un thread différent.
3-4-2. L'analyse spéculative ▲
Aussi bien Webkit que Firefox font cette optimisation. Pendant l'exécution de scripts, un autre thread analyse le reste du document et découvre les autres ressources qui doivent être chargées depuis le réseau et les charge. De cette façon, les ressources peuvent être chargées sur des connexions parallèles et la vitesse globale est meilleure. Remarquez que l'analyse spéculative ne modifie pas l'arborescence DOM, ceci est laissé à la charge de l'analyseur principal, elle ne fait qu'analyser les références à des ressources externes, comme les scripts externes, les feuilles de style et les images.
3-4-3. Les feuilles de style ▲
D'autre part, les feuilles de style ont un modèle différent. Sur le plan conceptuel, il semble que puisque les feuilles de style ne changent pas l'arborescence DOM, il n'y a aucune raison d'attendre leur chargement et d'arrêter l'analyse syntaxique du document. Il y a tout de même un problème, pour les scripts demandant des informations de style durant l'analyse du document. Si le style n'est pas encore chargé et analysé, le script va obtenir des réponses fausses et apparemment, cela a causé beaucoup de problèmes. Cela semble être un cas limite, mais c'est tout à fait commun. Firefox bloque tous les scripts tant qu'une feuille de style est en cours de chargement et d'analyse. Webkit bloque les scripts seulement quand ils tentent d'accéder à certaines propriétés de style qui peuvent être affectées par des feuilles de style non encore chargées.
4. La construction de l'arbre de rendu ▲
Pendant que l'arbre DOM est en cours de construction, le navigateur construit aussi un autre arbre, l'arbre de rendu. Cet arbre est constitué des éléments visuels dans l'ordre dans lequel ils apparaissent. Il est la représentation visuelle du document. Le but de cet arbre est de permettre le dessin du contenu dans l'ordre correct.
Firefox appelle ces éléments dans l'arbre de rendu « images ». Webkit utilise le terme de rendu ou objet de rendu.
Un rendu sait faire sa mise en page et se peindre, lui et ses enfants.
La classe Webkits RenderObject, la classe de base des rendus, a la définition suivante :
Chaque rendu représente une zone rectangulaire correspondant le plus souvent à la boite du nœud CSS, tel que décrit par la spécification CSS2. Il contient des informations géométriques comme sa largeur, sa hauteur et sa position.
Le type de la boite est affecté par l'attribut de style display qui est pertinent pour le nœud (voir la section de ). Voici le code Webkit pour décider quel type de rendu devrait être créé pour un nœud DOM, selon l'attribut display .
Le type de l'élément est également considéré, par exemple les champs de formulaires et les tables ont des cadres spéciaux.
Avec Webkit, si un élément veut créer un rendu spécial il remplace la méthode createRenderer . Le rendu pointe vers les objets de style qui contiennent les informations non géométriques.
4-1. La relation entre l'arbre DOM et l'arbre de rendu ▲
Les rendus correspondent aux éléments DOM, mais la relation n'est pas une relation un-à-un. Les éléments DOM non visuels ne sont pas insérés dans l'arbre de rendu. Par exemple, l'élément head . Les éléments dont l'attribut display est positionné à none n'apparaîtront pas dans l'arbre de rendu (en revanche, les éléments avec l'attribut display hidden seront présents dans l'arbre).
Il y a des éléments DOM qui correspondent à plusieurs objets visuels. Ce sont généralement des éléments de structure complexe qui ne peuvent être décrits par un simple rectangle. Par exemple, l'élément select possède trois rendus, un pour la zone d'affichage, un pour la zone de liste déroulante et un pour le bouton. De même, lorsque le texte est scindé en plusieurs lignes, car la largeur n'est pas suffisante pour tenir sur une seule, les nouvelles lignes seront ajoutées comme des rendus supplémentaires.
Un autre exemple de rendus multiples concerne le HTML mal formé. Selon les spécifications CSS, un élément inline doit contenir soit des blocs d'éléments ou alors seulement des éléments inline . En cas de contenu mixte, des rendus anonymes seront créés pour envelopper les éléments inline .
Certains objets rendus correspondent à un nœud DOM, mais pas au même endroit dans l'arbre. Les éléments flottants et ceux avec un positionnement absolu sont hors du flux, ils sont placés dans un endroit différent de l'arbre et appliqués au cadre réel. Leur emplacement réservé est là où ils auraient dû être.

4-2. La construction de l'arbre ▲
Avec Firefox, la présentation s'enregistre comme un écouteur pour les mises à jour du DOM. La présentation délègue la création des cadres à FrameConstructor et le constructeur décide du style (voir ) et crée le cadre.
Avec Webkit le processus de résolution du style et la création du rendu sont appelés « attachement ». Chaque nœud DOM possède une méthode attach . L'attachement est synchrone, l'insertion d'un nœud dans l'arbre DOM appelle la méthode attach du nouveau nœud.
Le traitement des balises html et body aboutit à la construction de la racine de l'arbre de rendu. L'objet de rendu racine correspond à ce que la spécification CSS appelle le bloc conteneur, le bloc le plus haut qui contient tous les autres blocs. Ses dimensions sont celles de la fenêtre d'affichage du navigateur. Firefox l'appelle ViewPortFrame et Webkit l'appelle RenderView . C'est l'objet de rendu pointé par le document. Le reste de l'arbre est construit au fur et à mesure de l'insertion des nœuds DOM. Voir la spécification CSS2 sur le modèle de traitement .
4-3. Calcul du style ▲
Construire l'arbre de rendu nécessite le calcul des propriétés visuelles de chaque objet de rendu. Ceci est fait en calculant les propriétés de style de chaque élément.
Le style inclut des feuilles de style d'origines diverses, les éléments de style inline et les propriétés visuelles dans le code HTML (comme la propriété bgcolor ). Celui-ci est traduit en correspondance des propriétés de style CSS.
Les origines des feuilles de style sont les feuilles de style par défaut du navigateur ; les feuilles de style fournies par l'auteur de la page et les feuilles de style de l'utilisateur (qui sont des feuilles de style fournies par l'utilisateur : les navigateurs vous permettent de définir votre style préféré. Avec Firefox, par exemple, cela est fait en plaçant une feuille de style dans le répertoire « Firefox profile »").
Le calcul du style fait apparaître quelques difficultés :
- Les données d'un style peuvent être très importantes du fait de nombreuses propriétés de style, cela peut causer des problèmes de mémoire ;
Par exemple, ce sélecteur composé :
Les règles du code suivant s'appliquent à un <div> qui est le descendant de trois <div> . Supposons que vous voulez vérifier si la règle s'applique pour un élément <div> donné. Vous choisissez un certain chemin dans l'arbre pour vérification. Vous pouvez avoir besoin de parcourir toute l'arborescence de nœuds juste pour voir qu'il y a seulement deux <div> et que la règle ne s'applique donc pas. Vous devez alors essayer d'autres chemins dans l'arbre.
- L'application des règles implique des règles de cascade assez complexes qui définissent leur hiérarchie.
Voyons comment les navigateurs font face à ces problèmes.
4-3-1. Le partage des données de style ▲
Les nœuds de Webkit référencent des objets style ( RenderStyle ) Ces objets peuvent être partagés par les nœuds sous certaines conditions. Les nœuds sont frères ou cousins et :
- Les éléments doivent être dans le même état en ce qui concerne la souris (par exemple, on ne peut être en mode :hover si l'autre ne l'est pas) ;
- Aucun élément ne doit avoir un identifiant ;
- Les noms de balises doivent correspondre ;
- Les attributs de classe doivent correspondre ;
- L'ensemble des attributs associés doivent être identiques ;
- L'état du lien doit correspondre ;
- L'état du focus doit correspondre ;
- Aucun élément ne doit être affecté par un sélecteur d'attribut ; affecté est défini comme ayant une correspondance avec un sélecteur contenant un sélecteur d'attribut quelle que soit sa position dans le sélecteur global ;
- Il ne doit pas y avoir d'attribut de style sur les éléments ;
- Il ne doit y avoir aucun sélecteur d'enfants. WebCore utilise simplement un commutateur global lorsqu'un sélecteur d'enfant est rencontré et désactive le partage de style pour le document entier quand ils sont présents. Cela comprend le sélecteur + et les sélecteurs comme :first-child et :last-child .
4-3-2. L'arbre des règles de Firefox ▲
Firefox dispose de deux arbres supplémentaires pour un calcul plus facile du style, l'arbre des règles et l'arbre de contexte de style. Webkit a aussi des objets de style, mais ils ne sont pas stockés dans un arbre, comme l'arbre de contexte de style, seul le nœud DOM pointe sur son style.

Les contextes de style contiennent des valeurs finales. Les valeurs sont calculées en appliquant toutes les règles d'appariement dans le bon ordre et en effectuant les manipulations qui les transforment de valeurs logiques à valeurs concrètes. Par exemple, si la valeur logique est le pourcentage par rapport à l'écran, il sera calculé et transformé en unités absolues. L'idée derrière l'arbre des règles est très intelligente. Elle permet de partager ces valeurs entre les nœuds pour éviter de les calculer à nouveau. Cela économise aussi de l'espace.
L'ensemble des règles adaptées sont stockées dans un arbre. Les nœuds du bas d'un chemin sont prioritaires. L'arbre contient tous les chemins pour la correspondance de règles qui ont été trouvées. Le stockage des règles se fait paresseusement. L'arbre n'est pas calculé au début de chaque nœud, mais à chaque fois qu'un style de nœud doit être calculé, le chemin calculé est ajouté à l'arbre.
L'idée est de voir l'arbre des chemins comme des mots dans un dictionnaire. Disons que nous avons déjà calculé cet arbre règle :

Supposons que nous devions faire correspondre des règles pour un autre élément dans l'arborescence de contenu et que nous trouvons que les règles appariées (dans le bon ordre) sont B - E - I. Nous avons déjà ce chemin dans l'arbre, car nous avons déjà calculé le trajet A - B - E - I - L. Nous avons maintenant moins de travail à faire.
Voyons comment cet arbre nous permet d'économiser du travail.
4-3-2-1. La division par structure ▲
Les contextes de style sont divisés en structures. Ces structures contiennent des informations de style pour une certaine catégorie comme la bordure ou la couleur. Toutes les propriétés dans une structure sont héritées ou non héritées. Les propriétés héritées sont des propriétés qui ne sont pas définies par l'élément, elles sont héritées du parent. Les propriétés non héritées (appelées propriétés « remise à zéro ») utilisent des valeurs par défaut si elles ne sont pas définies.
L'arbre nous aide en mettant en cache les structures (contenant les valeurs finales calculées) dans l'arborescence. L'idée est que si le nœud du bas n'a pas fourni une définition pour une structure alors une structure mise en cache pour un nœud supérieur peut être utilisée.
4-3-2-2. Calculer les contextes de style en utilisant l'arbre des règles ▲
Lors du calcul du contexte de style pour un élément donné, on calcule d'abord un chemin dans l'arbre des règles ou on en utilise un existant. Nous commençons alors par appliquer les règles dans le chemin pour combler les structures dans notre nouveau contexte style. Nous commençons à la partie basse du chemin, celui avec la plus haute priorité (généralement le sélecteur le plus spécifique) et parcourir l'arborescence jusqu'à ce que notre structure soit pleine. S'il n'y a pas de spécification pour la structure dans ce nœud règle, alors nous pouvons grandement optimiser, on remonte l'arborescence jusqu'à ce qu'on trouve un nœud qui satisfait pleinement et nous pointons tout simplement dessus, c'est la meilleure optimisation, la structure entière est partagée. Cela permet d'économiser le calcul des valeurs finales et la mémoire.
Si nous trouvons des définitions partielles, nous remontons l'arbre jusqu'à ce que la structure soit complète.
Si nous n'avons pas trouvé de définitions de notre structure, alors, dans le cas où la structure est de type « hérité », nous pointons vers la structure du parent dans l'arborescence des contextes , dans ce cas, nous avons également réussi à partager la structure. Si c'est une structure « remise à zéro », alors les valeurs par défaut sont utilisées.
Si le nœud le plus spécifique ajoute des valeurs, alors nous devons faire quelques calculs supplémentaires pour la transformer en valeurs réelles. Ensuite nous mettons en cache le résultat dans le nœud de l'arbre de sorte qu'il puisse être utilisé par des enfants.
Dans le cas où un élément a un frère qui pointe vers le nœud de l'arbre, alors le contexte de style complet peut être partagé entre eux.
Voyons un exemple, supposons que nous ayons ce HTML :
Et les règles suivantes :
Pour simplifier les choses, disons que nous devons remplir seulement deux structures, la structure couleur et la structure marge. La structure couleur contient un seul membre, la couleur. La structure marge contient les quatre côtés.
L'arbre de règles résultant ressemblera à ceci (les nœuds sont identifiés par le nom du nœud et le numéro de la règle sur laquelle ils pointent) :

L'arbre des contextes ressemblera à ceci (le nom de nœud est le nom de règle générale vers laquelle il pointe) :

Supposons que nous analysions le code HTML et que nous arrivions à la deuxième balise <div> . Nous devons créer un cadre de style pour ce nœud et remplir ses structures style.
Nous allons faire correspondre les règles et découvrir que les règles correspondantes pour le <div> sont 1, 2 et 6. Cela signifie qu'il y a déjà un chemin d'accès existant dans l'arborescence que notre élément peut utiliser, nous avons juste besoin d'ajouter un autre nœud pour la règle 6 (le nœud F dans l'arbre de règles).
Nous allons créer un contexte de style et le mettre dans l'arbre des contextes. Le nouveau contexte de style va pointer vers le nœud F dans l'arbre de règles.
Nous avons maintenant besoin de remplir les structures du style. Nous allons commencer par remplir la structure de marge. Puisque la règle du nœud F ne modifie pas la structure de marge, nous pouvons remonter dans l'arbre jusqu'à ce qu'on trouve une structure en cache calculée dans un nœud d'insertion précédent et l'utiliser. Nous allons la trouver avec le nœud B, qui est le nœud le plus élevé avec les règles de marge spécifiées.
Nous avons une définition de la structure couleur, donc on ne peut pas utiliser une structure en cache. Puisque la couleur n'a qu'un attribut, nous n'avons pas besoin d'aller dans l'arbre pour en remplir d'autres. Nous allons calculer la valeur finale (convertir la chaîne en RVB, etc.) et mettre en cache la structure calculée sur ce nœud.
Le travail sur le deuxième élément <span> est encore plus facile. Nous faisons correspondre les règles et arrivons à la conclusion qu'il pointe sur la règle G, comme le <span> précédent. Puisque ce sont des frères qui pointent vers le même nœud, nous pouvons partager le contexte de style tout simplement en pointant dans le contexte du <span> précédent.
Pour les structures qui contiennent des règles qui sont héritées du parent, la mise en cache se fait sur l'arbre de contexte (la propriété de couleur est en fait héritée, mais Firefox la traite comme « remise à zéro » et la met en cache sur l'arbre de règles).
Par exemple, si nous ajoutons des règles de polices dans un paragraphe :
Alors, l'élément de paragraphe, qui est un enfant de <div> dans l'arbre de contexte, aurait pu partager la structure de police de son parent. Cela serait le cas si aucune règle de police n'avait été spécifiée pour le paragraphe.
Avec Webkit, qui ne dispose pas d'un arbre de règles, les déclarations correspondantes sont traversées quatre fois. En premier, les propriétés non importantes (propriétés qui doivent être appliquées d'abord parce que d'autres dépendent d'elles, comme l'affichage) sont appliquées, ensuite, les propriétés importantes, puis les propriétés normales et enfin les propriétés normales pour les règles importantes. Cela signifie que les propriétés qui apparaissent plusieurs fois seront résolues selon l'ordre de cascade correct. C'est le dernier qui l'emporte.
Donc, pour résumer, le partage des objets style (tout ou partie des structures à l'intérieur) résout les problèmes 1 et 3 . L'arbre de règles Firefox contribue également à l'application des propriétés dans le bon ordre.
4-3-3. Manipuler les règles pour une recherche plus facile ▲
Il existe plusieurs sources pour les règles de style :
- les règles CSS, soit dans des feuilles de style externes, soit dans des balises style : Sélectionnez 1. p { color : blue }
- des attributs de style en ligne comme : Sélectionnez 1. <p style = "color:blue" />
- des attributs HTML visuels (qui sont mappés aux règles de style correspondantes) :
Les deux derniers sont facilement adaptés à l'élément, car ils possèdent les attributs de style et attributs HTML qui peuvent être indexés en utilisant l'élément comme clé.
Comme indiqué précédemment dans le problème 2 , la recherche de la règle CSS peut être plus compliquée. Pour résoudre cette difficulté, les règles sont manipulées pour en faciliter l'accès.
Après l'analyse de la feuille de style, les règles sont ajoutées à une des tables de hachage, en fonction de la sélection. Il y a des tables dont l'index est l'identifiant, le nom de classe, le nom de balise et une table générale pour tout ce qui ne rentre pas dans ces catégories. Si le sélecteur est un identifiant, la règle sera ajoutée à la table des identifiants, s'il s'agit d'une classe, elle sera ajoutée à la table des classes, etc.
Cette manipulation rend beaucoup plus facile la recherche des règles. Il n'est pas nécessaire de regarder dans chaque déclaration, nous pouvons extraire les règles applicables à un élément à partir des tables. Cette optimisation élimine 95 % et plus des règles, de sorte qu'elles ne devraient même pas être prises en compte lors du processus d'appariement ().
Voyons par exemple les règles de style suivantes :
La première règle est insérée dans la table des classes. La seconde dans la table des identifiants et la troisième dans la table des balises.
Pour le morceau HTML suivant :
Nous allons d'abord essayer de trouver des règles pour l'élément p . La table des classes contiendra une clé error en vertu de laquelle la règle de p.error est trouvée. La balise div aura une règle qui correspond dans la table des identifiants (la clé est l'identifiant) et la table des balises. Ainsi, le travail qui reste à faire est de savoir quelles sont les règles qui ont été extraites par les index qui correspondent vraiment.
Par exemple, si la règle de la div est :
elle sera toujours extraite de la table des balises, parce que la clé est le sélecteur de droite, mais elle ne correspondrait pas à notre élément div , qui n'a pas de parent de type table .
À la fois Webkit et Firefox font cette manipulation.
4-3-4. Appliquer les règles dans l'ordre correct ▲
L'objet style a des propriétés correspondant à chaque attribut visuel (tous les attributs CSS, mais plus génériques). Si la propriété n'est définie par aucune des règles adaptées, alors certaines propriétés peuvent être héritées du style de l'élément parent. D'autres propriétés ont des valeurs par défaut.
Le problème commence lorsqu'il y a plus d'une définition, voici l'ordre pour résoudre ce problème.
4-3-4-1. L'ordre des feuilles de style ▲
La déclaration d'une propriété de style peut apparaître dans plusieurs feuilles de style et plusieurs fois à l'intérieur d'une même feuille de style. Cela signifie que l'ordre d'application des règles est très important. C'est ce qu'on appelle la "cascade" des commandes. Selon la spécification CSS2, l'ordre en cascade est (de bas en haut) :
- Les déclarations du navigateur ;
- Les déclarations normales de l'utilisateur ;
- Les déclarations normales de l'auteur ;
- Les déclarations importantes de l'auteur ;
- Les déclarations importantes de l'utilisateur ;
Les déclarations du navigateur sont les moins importantes et celles de l'utilisateur supplantent celles de l'auteur uniquement si ces déclarations sont importantes. Les déclarations de même importance sont triées par et par ordre dans lequel elles apparaissent. Les attributs HTML visuels sont convertis en déclarations CSS. Ils sont traités comme des règles d'auteur de faible priorité.
4-3-4-2. La spécificité ▲
Le sélecteur de spécificité est défini par les spécifications CSS2 comme cela :
- compter 1 si la déclaration est issue d'un attribut style plutôt qu'une règle d'un sélecteur, 0 sinon (= a) ;
- compter le nombre d'attributs identifiant dans le sélecteur (= b) ;
- compter le nombre d'autres attributs et de pseudoclasse dans le sélecteur (= c) ;
- compter le nombre de noms d'éléments et de pseudoéléments dans le sélecteur (= d) ;
La concaténation des quatre nombres a-b-c-d (dans un système de numération à base large) donne la spécificité.
La base que vous devez utiliser est définie par le nombre le plus élevé que vous avez dans l'une des catégories.
Par exemple, si a = 14, vous pouvez utiliser la base hexadécimale. Dans le cas peu probable où vous aurez a = 17, vous aurez besoin d'une base 17. La situation peut se produire avec un sélecteur comme ceci : html body div div p ... (17 balises dans votre sélection, peu probable).
Quelques exemples :
4-3-4-3. Trier les règles ▲
Une fois que les règles sont trouvées, elles sont triées d'après les règles de cascade. Webkit utilise un tri à bulles pour les petites listes et un tri par fusion pour les grandes. Webkit met en œuvre le tri en remplaçant l'opérateur « > » pour les règles :
4-4. Processus graduel ▲
Webkit utilise un indicateur qui marque les feuilles de style haut niveau (y compris les règles @imports ) chargées. Si le style n'est pas complètement chargé lors de l'attachement, des jokers sont utilisés et le document est marqué. Ils seront recalculés une fois les feuilles de style chargées.
5. La mise en page ▲
Quand le rendu est créé et ajouté à l'arbre, il n'a ni position ni taille. Calculer ces valeurs est appelé « mise en page » ou « refusion ».
HTML utilise un modèle de mise en page basé sur une fusion, ce qui signifie que, la plupart du temps, il est possible d'en calculer la géométrie en une seule passe. Les éléments qui sont ajoutés « dans le flux » n'affectent généralement pas la géométrie des éléments qui y étaient déjà, de telle sorte que la mise en page se fait de gauche à droite et de haut en bas pour tout le document. On compte quelques exceptions - par exemple, le rendu des tableaux HTML peut prendre plusieurs passes (3.5).
Le système de coordonnées est relatif au cadre principal. Les coordonnées sont initialisées en haut à gauche.
La mise en page est un processus récursif. Il commence à la racine du moteur de rendu, ce qui correspond à l'élément <html> du document HTML. Elle continue de manière récursive dans une partie ou toute la hiérarchie des cadres, en calculant les informations géométriques pour chaque moteur de rendu qui le requiert.
La position du moteur de rendu racine est (0, 0) et ses dimensions correspondent à la zone d'affichage - la part visible de la fenêtre du navigateur.
Tous les moteurs de rendu ont une méthode de « mise en page » ou de « refusion », chacun invoque la méthode de mise en page de ses enfants quand il en a besoin.
5-1. Le système du bit sale ▲
Pour ne pas effectuer à nouveau une mise en page complète à chaque petit changement, les navigateurs utilisent un système de « bit sale ». Un moteur de rendu qui est changé ou ajouté se marque ainsi que ses enfants comme « sales » (ils doivent être remis en page).
Généralement, les navigateurs distinguent deux drapeaux : « sale » et « enfants sales ». Ce dernier signifie que, bien que le moteur de rendu lui-même corresponde toujours au contenu HTML, il y a au moins un enfant qui doit être remis en page.
5-2. Mise en page globale et incrémentale ▲
La mise en page peut s'effectuer sur tout l'arbre de rendu - on l'appelle « mise en page globale ». Cela peut arriver suite à :
- Un changement dans le style global, qui affecte tout le contenu, comme un changement de la taille de police ;
- Un redimensionnement de la fenêtre.
La mise en page peut également être incrémentale, auquel cas seuls les éléments sales seront remis en page (ce qui peut causer quelques dommages, qui causeront des remises en page supplémentaires).
Cette mise en page incrémentale est déclenchée (de manière asynchrone) quand les moteurs de rendu sont sales, par exemple quand de nouveaux objets sont ajoutés à la fin de l'arbre de rendu après que du contenu supplémentaire est arrivé du réseau et est ajouté à l'arbre DOM.

5-3. Mise en page synchrone ou non ▲
La mise en page incrémentale est effectuée de manière asynchrone. Firefox met en file d'attente les « commandes de refusion » pour des mises en page incrémentales et un planificateur lance l'exécution par lots de ces commandes. WebKit dispose aussi d'un minuteur qui effectue une mise en page incrémentale - l'arbre est traversé et les moteurs de rendu sales sont remis en page.
Les scripts qui demandent des informations sur le style, comme offsetHeight , peuvent déclencher une mise en page incrémentale synchrone.
La mise en page globale est généralement effectuée de manière synchrone.
De temps en temps, la mise en page est demandée par une fonction de rappel après une mise en page initiale parce que certains attributs, comme la position du défilement, ont changé.
5-4. Optimisations ▲
Quand une mise en page est déclenchée par un redimensionnement ou un changement dans la position d'un élément (non dans sa taille), les dimensions des éléments affectés ne sont pas recalculées, elles sont reprises d'un cache.
Dans certains cas, seul un sous-arbre est modifié, la mise en page ne repart pas de la racine. Ceci peut arriver dans des cas où le changement est local et n'affecte pas son environnement, comme de l'insertion de texte dans des champs (sinon, chaque appui sur une touche du clavier aurait relancé une mise en page depuis la racine).
5-5. Le processus de mise en page ▲
La mise en page suit généralement cette procédure :
- L'élément parent détermine sa propre largeur ;
- Place l'élément enfant (il définit ses positions en x et y),
- Appelle la mise en page de l'enfant au besoin (s'ils sont sales, si la mise en page est globale ou pour toute autre raison) ;
- Le parent utilise les hauteurs cumulées de ses enfants et les hauteurs des marges internes et externes pour définir sa propre hauteur (cette information sera utilisée par le moteur de rendu de son parent) ;
- Le bit sale est mis à une valeur fausse.
Firefox utilise un objet d'état ( nsHTMLReflowState ) comme paramètre à la mise en page (appelée reflow). Entre autres, l'état inclut la largeur du parent.
La sortie de la mise en page de Firefox est un objet de métrique ( nsHTMLReflowMetrics ) qui contient la hauteur calculée du moteur de rendu.
5-6. Calcul de la largeur ▲
La largeur d'un élément est calculée en utilisant la largeur du bloc conteneur, la propriété width du style du moteur, les marges et bordures.
Par exemple, la largeur de l'élément suivant :
serait calculée par WebKit comme ceci (méthode calcWidth de la classe RenderBox ) :
- la largeur du contenu est le maximum de la propriété availableWidth du conteneur et de zéro. availableWidth , dans ce cas, est la valeur calculée comme :
- clientWidth et clientHeight représentent l'intérieur d'un objet, en dehors de sa bordure et de sa barre de défilement ;
- la largeur des éléments est donnée par l'attribut width du style. Elle est calculée comme une valeur absolue avec le pourcentage de la largeur du conteneur ;
- les bordures horizontales et les marges sont alors ajoutées.
Jusqu'ici, WebKit calculait la « largeur préférée ». Il faut à présent calculer les maximum et minimum.
Si la largeur préférée est supérieure à la largeur maximale, le maximum sera utilisé. Si elle est plus petite que la largeur minimale (la plus petite unité incassable), le minimum sera utilisé.
Les valeurs sont mises en cache, au cas où une mise en page serait requise sans que la largeur change.
5-7. Passage à la ligne ▲
Quand un élément, au beau milieu de sa mise en page, décide qu'il doit passer à la ligne, il s'arrête et dit à son parent qu'il a besoin de passer à la ligne. Le parent crée alors des rendus supplémentaires et leur demande d'effectuer une mise en page.
6. Le dessin ▲
Dans l'étape de dessin, l'arbre de rendu est parcouru et la méthode « dessiner » des rendus est appelée pour afficher le contenu à l'écran. Le dessin utilise l'infrastructure de l'interface utilisateur.
6-1. Global et incrémental ▲
Comme l'affichage, le dessin peut également être global, l'arbre entier est dessiné, ou incrémental. Dans le dessin incrémental, certains rendus changent d'une façon qui n'affecte pas l'arbre entier. Le rendu changé invalide son rectangle sur l'écran. L'OS le voit alors comme une « région sale » et génère un événement de « dessin ». L'OS le fait intelligemment et fusionne plusieurs régions en une seule. Sous Chrome c'est un peu plus compliqué, car le rendu est dans un processus différent du processus principal. Chrome simule le comportement de l'OS dans une certaine mesure. La couche présentation écoute ces événements et délègue le message à la racine du rendu. L'arbre est parcouru jusqu'à ce qu'un rendu pertinent soit atteint. Il se redessinera de lui-même (et généralement ses enfants avec).
6-2. L'ordre de dessin ▲
CSS2 définit l'ordre du processus de dessin . C'est en fait l'ordre dans lequel les éléments sont empilés dans la pile des contextes . Cet ordre affecte le dessin puisque les piles sont dessinées de l'arrière vers l'avant. L'ordre d'empilement d'un bloc de rendu est :
- Couleur d'arrière-plan ;
- Image d'arrière-plan ;
6-3. Liste d'affichage de Firefox ▲
Firefox va au-delà de l'arbre de rendu et construit une liste d'affichage pour les rectangles dessinés. Elle contient les rendus pertinents pour ces rectangles dans le bon ordre de dessin (couleur d'arrière-plan, puis bordures, etc.). De cette façon l'arbre n'a besoin d'être traversé qu'une seule fois pour être redessiné au lieu de plusieurs, dessiner tous les arrières-plans, puis toutes les images, puis toutes les bordures, etc.
Firefox optimise le processus en n'ajoutant pas les éléments qui seront cachés, comme les éléments placés derrière un élément opaque.
6-4. Stockage des rectangles sous Webkit ▲
Avant de redessiner, Webkit stocke les anciens rectangles en bitmap. Il redessine ensuite uniquement les différences entre les rectangles stockés et les nouveaux.
7. Les changements dynamiques ▲
Les navigateurs essayent de faire le moins d'actions possible en réponse à un changement. Ainsi, le changement de couleur d'un élément aura pour effet de seulement repeindre cet élément. La modification de la position de l'élément aura pour effet de repeindre cet élément, ses enfants et peut-être aussi ses frères et sœurs. L'ajout d'un nœud DOM provoquera le dessin de ce nœud. Des changements majeurs, comme la taille de police de l'élément html , entraîneront l'invalidation des caches et demanderont le réarrangement et de redessin de l'arbre complet.
8. Les threads du moteur de rendu ▲
Le moteur de rendu est mono thread. Presque tout, sauf l'exploitation du réseau, se passe dans un seul thread. Dans Firefox et Safari c'est le thread principal du navigateur. Dans Chrome c'est le thread de processus onglet principal.
L'exploitation du réseau peut être effectuée par plusieurs threads en parallèle. Le nombre de connexions en parallèle est limité (généralement deux à six connexions. Firefox 3, par exemple, en utilise six).
8-1. La boucle de messages ▲
Le thread principal du navigateur est une boucle d'événements. C'est cette boucle infinie qui rend le processus plus vivant. Il attend des événements (comme une mise en page ou les événements de dessin) et les traite. Voici le code de Firefox pour la boucle principale :
9. Le modèle visuel CSS2 ▲
9-1. la toile (canevas) ▲.
Selon la spécification CSS2 , le terme toile désigne « l'espace où la structure de format est rendue », où le navigateur dessine le contenu. Les dimensions de cette toile sont infinies, mais les navigateurs choisissent une largeur initiale basée sur les dimensions de la fenêtre.
Selon www.w3.org/TR/CSS2/zindex.html , cette toile, si elle est contenue dans une autre, est transparente sinon, elle possède une couleur définie par le navigateur.
9-2. Le modèle des boite s CSS ▲
Le modèle des boites CSS décrit des boites rectangulaires qui sont générées pour les éléments de l'arborescence du document et présentées selon le modèle de formatage visuel.
Chaque boite contient une zone de contenu (par exemple, du texte, une image, etc.) et en option une zone de marge interne ( padding ), de bordure et de marge externe ( margin ).

Chaque nœud génère entre 0 et n de ces boites.
Tous les éléments ont une propriété display qui détermine le type de boite qui sera généré. Exemples :
La valeur par défaut est inline , mais la feuille de style navigateur peut en configurer d'autres. Par exemple, l'affichage par défaut pour l'élément div est le bloc.
Vous pouvez trouver un exemple de feuille de style par défaut ici : www.w3.org/TR/CSS2/sample.html .
9-3. Le schéma de positionnement ▲
Il y a trois cas :
- Normal : l'objet est positionné en fonction de son emplacement dans le document, ce qui signifie que sa place dans l'arbre de rendu est comme spécifié dans l'arbre DOM en fonction de son type de boite et de ses dimensions ;
- Flottant : l'objet est d'abord placé comme pour un objet normal, puis déplacé aussi loin vers la gauche ou la droite que possible ;
- Absolu : l'objet est placé dans l'arborescence de rendu différemment de sa place dans l'arbre DOM.
Le schéma de positionnement est défini par la propriété position et l'attribut float .
- static et relative provoquent un positionnement normal ;
- absolute et fixed provoquent un positionnement absolu.
Avec un positionnement static , aucune position n'est définie et le positionnement par défaut est utilisé. Pour les autres cas, l'auteur précise la position, haut, bas, gauche, droite.
La façon dont une boite est dessinée est déterminée par :
- le type de boite ;
- les dimensions de la boite ;
- le schéma de positionnement ;
- des informations externes comme la taille des images et la taille de l'écran.
9-4. Les types de boites ▲
Boite block : forme un bloc, elle a son propre rectangle sur la fenêtre du navigateur.

Boite inline : elle ne dispose pas de son propre bloc, mais l'intérieur est un bloc conteneur.

Les boites block sont mises en forme verticalement l'une après l'autre. Les boites inline sont mises en forme à l'horizontale.

Les boites inline sont mises en ligne horizontalement, ou en «boites en ligne». Les lignes sont au moins aussi grandes que la plus grande boite, mais peut-être plus grandes, lorsque les boites sont alignées baseline , ce qui signifie que la partie inférieure d'un élément est alignée avec un point d'un autre bloc puis en bas. Dans le cas où la largeur du conteneur n'est pas suffisante, les boites inline seront mises sur plusieurs lignes. C'est généralement ce qui se passe dans un paragraphe.

9-5. Le positionnement ▲
9-5-1. relatif ▲.
Le positionnement relatif : il est positionné comme d'habitude puis déplacé de la valeur requise.

9-5-2. Flottant ▲
Une boite flottante est déplacée vers la gauche ou vers la droite d'une ligne. La caractéristique à noter est que les autres boites vont s'agencer autour d'elle. Le code HTML :
Ressemblerait à :

9-5-3. Absolu et fixe ▲
La mise en page est définie exactement, quel que soit le flux normal. L'élément ne participe pas au flux normal. Les dimensions sont par rapport au conteneur. Avec fixe, le conteneur est la vue du navigateur.

Notez, une boite fixe ne bougera pas, même quand on fait défiler le document !
9-6. La représentation en couche ▲
Elle est spécifiée par la propriété CSS z-index . Elle représente la troisième dimension de la boite le long de « l'axe z ».
Les boites sont divisées en piles (appelé contexte d'empilement). Dans chaque pile, les éléments arrière seront dessinés en premier et les éléments du premier plan, plus près de l'utilisateur, ensuite. En cas de chevauchement l'élément de premier plan permet de masquer l'élément en arrière-plan.
Les piles sont classées en fonction de la propriété z-index . Les boites avec une propriété z-index forment une pile locale. La fenêtre d'affichage présente la pile externe.
Le résultat sera cela :

Bien que la balise div en rouge précède la balise en vert, et aurait donc été peinte avant dans le flux régulier, sa propriété z-index est élevée, elle est donc plus en avant que la pile détenue de la boite de racine.
10. Ressources ▲
- Grosskurth, Alan. A Reference Architecture for Web Browsers (pdf) ;
- Gupta, Vineet. How Browsers Work - Part 1 - Architecture .
- Aho, Sethi, Ullman, Compilers: Principles, Techniques, and Tools (aka the "Dragon book"), Addison-Wesley, 1986 ;
- Rick Jelliffe. The Bold and the Beautiful: two new drafts for HTML 5.
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developers ;
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developers (Google tech talk video) ;
- L. David Baron, Mozilla's Layout Engine ;
- L. David Baron, Mozilla Style System Documentation ;
- Chris Waterson, Notes on HTML Reflow ;
- Chris Waterson, Gecko Overview ;
- Alexander Larsson, The life of an HTML HTTP request .
- David Hyatt, Implementing CSS(part 1) ;
- David Hyatt, An Overview of WebCore ;
- David Hyatt, WebCore Rendering ;
- David Hyatt, The FOUC Problem .
- HTML 4.01 Specification ;
- W3C HTML5 Specification ;
- Cascading Style Sheets Level 2 Revision 1 (CSS 2.1) Specification .
- Firefox. https://developer.mozilla.org/en/Build_Documentation ;
- Webkit. http://webkit.org/building/build.html .
| est développeuse en Israël. Elle a commencé comme développeuse Web en 2000 et est devenue experte avec le modèle en couche du « diable » Netscape. Tout comme Richard Feynmann, elle est fascinée pour comprendre comment les choses marchent et ainsi, elle a commencé à creuser dans le fonctionnement interne des navigateurs et à documenter ce qu'elle a trouvé. Tali a aussi publié un . |
10-1. Traductions ▲
Cet article a été traduit en japonais, deux fois !
- How Browsers Work - Behind the Scenes of Modern Web Browsers (ja) par @_kosei ;
- ブラウザってどうやって動いてるの?(モダンWEBブラウザシーンの裏側 par @ikeike443 et @kiyoto01 .
Merci à tout le monde !
10-2. Remerciements Developpez ▲
L'équipe de la Rédaction Developpez.com remercie toutes les personnes qui ont participé à cette traduction et à sa correction orthographique, avec par ordre alphabétique : Bovino , ClaudeLELOUP , djibril , dourouc05 , FirePrawn , ram-0000 et zoom61 .

Les meilleurs navigateurs web en 2024
Les meilleurs navigateurs en terme de vitesse, de confidentialité et de personnalisation.
- Produits en bref
Le meilleur
Le plus rapide
Le plus fluide
Le plus polyvalent
Le plus personnalisable

1. Les produits en bref
2. Le meilleur
3. Le plus rapide
4. Le plus fluide
5. Le plus polyvalent
6. Le plus personnalisable
Lorsqu’il s’agit de trouver le meilleur navigateur web pour votre appareil, la confidentialité et la vitesse constituent deux éléments primordiaux. Tandis que certains navigateurs vous demanderont davantage de ressources système, d'autres restent relativement légers.
Quelques navigateurs anonymes offrent des suites complètes d'outils de sécurité pour protéger votre identité en ligne et vous protéger contre les logiciels malveillants, tandis que la plupart trient aujourd'hui les cookies et les publicités de fonctionner sans entrave.
Les navigateurs cités ci-dessous sont loin d'être les seules options qui existent, et il y a de nombreuses raisons de regarder au-delà des grands noms, et de vous diriger plutôt vers des navigateurs plus spécialisés. Lisez notre guide complet et découvrez le navigateur qui vous conviendra le mieux.
Emmanuelle a rejoint l'équipe de TechRadar France en 2022, elle travaille sur la partie guides d'achat. Si vous ne savez plus où donner de la tête, elle saura vous orienter vers le meilleur smartphone ou le meilleur téléviseur en fonction de vos besoin.
Les produits en bref
Voici les 5 meilleurs navigateurs web selon nos tests. Pour en lire davantage sur un navigateur web précis, cliquez simplement sur En savoir plus.

Mozilla Firefox répond aux besoins de la majorité des utilisateurs. Il est polyvalent, permet une synchronisation multiplateforme et intègre une protection de la vie privée.
En savoir plus

Microsoft Edge est un navigateur web ultra-rapide. Il intègre également des outils de confidentialité clairs et permet d'enregistrer des sites en tant qu'applications.

Opera est un navigateur web qui dispose d'excellentes fonctions de sécurité et qui propose une interface très agréable à utiliser. Il a également l'avantage d'intégrer un Proxy.

Google Chrome est un navigateur web très extensible, qui dispose d'une interface multiplateformes et qui offre des performances très rapides.

Vivaldi permet de créer son propre navigateur web, avec des fonctions d'ancrage uniques et des fonctions d'empilement d'onglets. Il prend également en charge les extensions Chrome.

1.ExpressVPN - Le meilleur VPN pour votre navigateur Nous avons examiné plus d'une centaine de fournisseurs de VPN, gratuits et payants, et notre meilleure recommandation à l'heure actuelle est ExpressVPN. Compte tenu des risques liés à l'utilisation de VPN gratuits, nous pensons que le prix de 6,32 euros par mois vaut largement le coup. De plus il est accompagné d'une garantie de remboursement de 30 jours.

2. Surfshark VPN - La meilleure option de VPN bon marché Si ExpressVPN est trop cher, ne cherchez pas plus loin que le VPN n°2 de TechRadar : Surfshark. À partir de seulement 2,11 euros par mois, vous aurez accès à un VPN fantastique, incroyablement simple à utiliser et qui est devenue l'un des favoris de TechRadar. Il offre la plupart des mêmes fonctionnalités que les autres services, mais pour beaucoup moins cher.

3. NordVPN - le plus grand nom du VPN Il y a de fortes chances que, même si vous ne connaissez pas grand-chose aux VPN, vous ayez tout de même entendu parler de NordVPN. Ils font de la publicité à la télévision, ils sponsorisent des équipes sportives et ils sont leaders sur le marché des VPN depuis plus de 10 ans. Si NordVPN n’est plus le meilleur sur le marché, il reste pour autant un service fantastique à partir de seulement 3,49 euros par mois.
Quel est le meilleur navigateur web pour vous ?
Pourquoi pouvez-vous faire confiance à TechRadar ? Nos examinateurs experts passent des heures à tester et à comparer les produits et services afin que vous puissiez choisir le meilleur pour vous. En savoir plus sur la façon dont nous testons .
Le meilleur navigateur web

1. Mozilla Firefox
Caractéristiques techniques, pourquoi l’acheter, pourquoi attendre.
Firefox est depuis longtemps le couteau suisse de l'internet et le meilleur navigateur selon nous. La version 97 est particulièrement bonne puisqu'elle peut vous alerter si votre adresse électronique est incluse dans une violation de données connue. Elle bloque également les fenêtres pop-up de notification, ainsi que le suivi du navigateur par "empreinte digitale".
Le navigateur Mozilla Firefox se veut incroyablement personnalisable, tant au niveau de son apparence qu'au niveau de ses extensions et ses plug-ins. Ayant subi une refonte l'année dernière, les performances du navigateur, qui commençaient à être à la traîne par rapport à Chrome, ont été considérablement améliorées. Il se montre fluide et solide même sur des configurations assez modestes.
Si Mozilla Firefox est toujours notre favori, nous sommes inquiets pour son avenir. Ces dernières années n'ont pas composé un grand cru pour Mozilla, avec une crise majeure des modules complémentaires qui, selon Peter Saint-Andre et Matthew Miller, "était le résultat de l'imbrication d'un ensemble de systèmes complexes qui n'étaient pas bien compris par les équipes concernées".
Le manque d'équipes internes d'assurance qualité a également été souligné (une grande partie de l'assurance qualité de Mozilla est externalisée) et au début de cette décennie, les responsables auraient subi une série de licenciements massifs. Mozilla a du mal à trouver des financements permanents, alors si vous appréciez Firefox, vous pouvez vous rendre sur donate.mozilla.org pour aider à lui assurer un avenir glorieux.
- Aller en haut de l'article
Le navigateur web le plus rapide

2. Microsoft Edge
Les lecteurs plus âgés se souviendront de Microsoft comme de l'éditeur avide de pouvoir qui a finalement conduit à l'émergence de Firefox et de Chrome. Mais Microsoft est désormais du bon côté de la barrière, et son navigateur Edge a évolué avec Chromium comme base principale. Il s'agit du navigateur par défaut de Windows et il existe également des versions pour iOS, Android et Mac.
La nouvelle version alimentée par Chromium est considérablement plus rapide que la précédente et comprend quelques fonctionnalités utiles, notamment la lecture à haute voix, la possibilité de diffuser des médias en ligne sur des appareils Chromecast, une page de démarrage de style Opéra et une bonne sélection de modules complémentaires (gestionnaires de mots de passe, bloqueurs de publicité, etc).
Vous pouvez également télécharger des pages Web sous forme d'applications qui s'exécutent ensuite de manière autonome sans avoir à lancer le navigateur dans son intégralité. C'est utile pour des applications comme Google Docs ou Twitter.
Il existe de nombreuses options de personnalisation et nous avons particulièrement apprécié la page Confidentialité et services , qui clarifie les paramètres potentiellement déroutants, ainsi que la page Autorisations du site , qui permet de contrôler dans les moindres détails ce que des sites spécifiques peuvent faire (les fenêtres pop-up, le blocage des publicités, l'accès aux périphériques MIDI et la lecture automatique des médias).
Edge ressemble et fonctionne comme Chrome, mais nous le préférons. Pourquoi ? Tout d'abord parce qu'il est nettement plus rapide sur Mac, mais aussi parce que les options de personnalisation sont superbes.
Le navigateur web le plus fluide

Opera propose un écran d'accueil agréable, qui permet d'activer son bloqueur de publicité intégré, d'utiliser son VPN intégré, de surveiller son Crypto Wallet si vous minez des cryptomonnaies, de consulter votre messagerie dans le navigateur à partir de la barre latérale, ou encore de passer du mode clair au mode sombre.
Il s'agit d'une excellente alternative aux navigateurs les plus célèbres. Opera est basé sur Chromium, les performances sont donc rapides et vous pouvez utiliser les add-ons de la bibliothèque Chrome. Il propose également quelques idées intéressantes, comme Flow, conçu pour les personnes qui repèrent souvent des éléments sur lesquels elles souhaitent revenir plus tard : si vous envoyez constamment des e-mails ou des messages contenant des liens intéressants, Flow vous permet de le faire de manière plus élégante, en facilitant le partage du contenu d'Opera sur votre téléphone ou sur votre ordinateur.
Avec sa mise à jour R5, qui apporte un design raffiné et des applications intégrées telles que WhatsApp et Facebook Messenger, Opera veut s'assurer de vous délivrer une solution tout-en-un facile à utiliser au quotidien.
Opera a récemment été intégré aux Chromebooks de Google, offrant ainsi un plus grand choix aux étudiants et aux seniors, principales cibles de ce type d'ordinateurs portables. Si vous êtes un gamer avéré, nous recommandons davantage le navigateur Opera GX , une version conçue spécifiquement pour les joueurs et qui propose l'intégration de Twitch et la prise en charge de Razer Chroma.
Ces dernières années, Opéra s’est énormément amélioré, notamment grâce à sa volonté de répondre aux besoins de nombreux utilisateurs, des joueurs aux étudiants, en passant par les mineurs de cryptomonnaies. C'est définitivement un navigateur à surveiller en 2024.
Le navigateur web le plus polyvalent

4. Google Chrome
Google Chrome est un navigateur brillant, doté d'une superbe bibliothèque de modules, d'une prise en charge et d'une synchronisation multiplateformes, d'excellentes fonctions de remplissage automatique et de quelques outils formidables pour les développeurs Web.
Il peut vous avertir si votre messagerie électronique a été compromise, il dispose d'une fonction de recherche DNS sécurisée pour les fournisseurs compatibles (le DNS public de Google en fait partie) et il bloque de nombreux contenus mixtes dangereux, tels que les scripts et les images, sur des connexions par ailleurs sécurisées. Il permet également d'utiliser l'API WebXR pour la réalité augmentée et la réalité virtuelle. Et n'oubliez pas le mode sombre de Chrome, qui rend la navigation plus facile pour vos yeux lorsque vous consultez vos sites de nuit.
On lui reproche simplement le fait d'être très gourmand en ressources, ce qui limite les configurations compatibles. Une configuration de base, avec une RAM limitée, pourra difficilement supporter Google Chrome. La nouvelle fonction de gel des onglets vise à y remédier, en mettant automatiquement les onglets en arrière-plan lorsqu'ils ne sont pas visionnés par l'utilisateur, mais Chrome reste malgré tout assez gourmand en ressources matérielles.
Le navigateur web le plus personnalisable

Si vous aimez personnaliser votre interface, Vivaldi est un outil fantastique. Ce navigateur est dédié aux utilisateurs expérimentés, qui savent exactement ce qu'ils veulent et comment utiliser leur navigateur.
Vivaldi est l'œuvre d'anciens développeurs d'Opera et, comme Opera, il fait les choses différemment des grands navigateurs. Dans ce cas, très différemment. Vivaldi est axé sur la personnalisation, et vous pouvez modifier à peu près tout, des fonctionnalités du navigateur, à l'apparence de l'interface utilisateur.
Avec Chromium intégré, vous pouvez utiliser la plupart des extensions Chrome, mais le navigateur s'avère très différent des autres basés sur Chromium. Vous pouvez épingler des sites dans la barre latérale, placer des barres d'outils où bon vous semble, ajuster les polices et les couleurs des pages, personnaliser le fonctionnement de vos recherches, donner des surnoms aux moteurs de recherche ou encore modifier le fonctionnement et le regroupement des onglets.
Il est même possible d'afficher votre historique sous forme de graphiques pour voir le temps que vous avez passé sur certains sites. Nous apprécions particulièrement les piles d'onglets, une aubaine pour toutes les personnes qui ont tendance à en ouvrir une vingtaine par jour.
Etes-vous un expert ? Abonnez-vous à notre newsletter
Inscrivez-vous à la newsletter TechRadar Pro pour recevoir toutes les actualités, les opinions, les analyses et les astuces dont votre entreprise a besoin pour réussir !
J'ai rejoint l'équipe de TechRadar France en 2022, et suis chargée de la rédaction des guides d'achat. Je suis passionnée d’écriture, un peu geek sur les bords et fan de nouvelles technologies. Toujours aux quatre coins du monde, vous ne saurez jamais trop où me trouver. En revanche, je saurai toujours trouver les bons mots pour vous aider à dénicher le meilleur smartphone, le meilleur appareil photo ou encore les jeux vidéo les plus funs du moment.
- Carrie Marshall
- Daryl Baxter Software & Downloads Writer
Meilleures alternatives à Skype : les applications les plus pratiques pour passer vos appels vidéo en 2024
Les meilleurs logiciels de retouche photo de 2024
Samsung Galaxy Z Fold 6 : toutes les caractéristiques attendues
Les plus populaires
Trouver un article
Thèmes populaires
Navigateur web : structure, rôle et fonctionnement.
Comment est constitué un navigateur web ? Éléments de réponse avec Anthony Le Goas, directeur de l’agence Zenika Brest, dans le cadre du Web2day 2023.

À l’occasion du Web2day, Anthony Le Goas , directeur du cabinet de conseil en informatique Zenika à Brest, a tenu la conférence intitulée : « Sous le capot des navigateurs web ». Pour introduire son sujet, l’intervenant a pris soin de rappeler la définition d’un navigateur web, selon Wikipédia : “C’est un logiciel conçu pour consulter et afficher le World Wild Web.”
Je note deux choses intéressantes ici : l’action de consulter et d’afficher. Cela nous donne une idée du rôle du navigateur. Avec cette première action, il va aller chercher des ressources web (HTML, CSS, une image, un fichier PDF…), pour ensuite afficher le contenu afin de proposer un rendu à l’utilisateur.
Au niveau des principaux acteurs, Chrome, le navigateur web de Google, reste le plus utilisé dans le monde avec 66,22 % de parts de marché en avril 2023 (59,98 % en France), selon les données de StatCounter . Il devance Safari (11,89 %), le navigateur web d’Apple, et Edge (10,95 %), celui de Microsoft. En France, c’est Firefox qui prend la 2e place (14,13 %) devant Edge (12,33 %).
La structure des navigateurs web
Selon le directeur de l’agence Zenika Brest, un navigateur web est composé de différentes briques, dont certaines sont reliées entre elles au sein de sa structure globale (voir l’image de Une) :
- L’UI Browser : c’est l’interface du navigateur, qui est affichée à l’écran avant d’accéder à la ressource web (barre de recherche, boutons précédent/suivant, etc.).
- Le moteur browser : il est considéré comme “la tête pensante du navigateur” , qui va piloter et synchroniser les différents éléments associés. “Lorsqu’on va cliquer par exemple sur le bouton précédent, c’est le moteur browser qui va interpréter cette action pour répondre à la requête.”
- Le moteur de rendu : il représente “le cœur du navigateur” , qui va chercher la ressource web pour afficher le rendu au niveau du navigateur. Au sein du moteur de rendu figurent 3 autres composants, à savoir le réseau, le moteur JavaScript qui permet d’animer les pages web, et l’UI Backend.
- L’UI Backend : il est à la fois lié au moteur de rendu et à l’UI Browser. Sur ce point, Anthony Le Goas précise que “c’est là où l’on va piocher tous les éléments natifs qui vont être utilisés par le navigateur pour faire des composants basiques, pour dessiner une fenêtre à l’écran par exemple, ou encore pour trouver les menus ou les boutons à afficher” .
- La persistance des données : cette couche est pilotée par le moteur du navigateur et permet de stocker des ressources pour faire fonctionner les applications web ou encore pour gérer les cookies.
Focus sur le moteur de rendu : son rôle et son fonctionnement en 3 étapes
Il existe 3 principaux moteurs de rendu pour les navigateurs web phares du marché : Gecko (Firefox), Blink (Google Chrome, Chromium, Brave, Opera, Microsoft Edge) et WebKit (Safari). Son rôle est essentiel car il va permettre d’afficher le code HTML et les feuilles de style en vue de “dessiner” , c’est-à-dire “afficher visuellement” la ressource demandée aux utilisateurs.
Un moteur de rendu HTML est le composant logiciel de tous les navigateurs permettant d’afficher une page web : il transforme un document HTML, ainsi que toutes les autres ressources associées, en une représentation visuelle interactive pour l’utilisateur. Il est de ce fait le cœur d’un navigateur web (source : Wikipédia).

Concrètement, plusieurs opérations sont nécessaires pour assurer le fonctionnement d’un moteur de rendu. La première opération est celle du parsing, qui consiste à “traduire les éléments à afficher en une structure que le code peut comprendre et utiliser” . Il se base sur des règles de syntaxe ainsi qu’un vocabulaire, qui vont constituer ce que l’on appelle la grammaire du langage. Anthony Le Goas rappelle que 2 types de grammaire sont possibles, contextuelle ou non contextuelle, en fonction de la complexité du parsing.
Une grammaire contextuelle, c’est quoi ? Quand on va chercher à interpréter un mot clé qu’on a identifié dans la chaîne de caractères que l’on souhaite parser, l’interprétation de ce mot clé peut différer en fonction du contexte dans lequel il est utilisé, selon ce qui se trouve avant et après. À l’inverse, une grammaire dite non contextuelle consiste à prendre un mot clé et, peu importe ce qu’il y a avant ou après, son interprétation restera toujours la même.
Une action de parsing se décompose de la manière suivante :
- l’analyse lexicale : c’est-à-dire le processus de séparation de l’entrée en mots clés,
- l’analyse syntaxique : c’est-à-dire le processus d’application des règles de syntaxe.
Du côté du HTML et du CSS, le parsing va se baser sur les spécifications du W3C, qui contiennent l’ensemble des balises HTML et l’ensemble des mots clés CSS qui peuvent être utilisés. Le CSS requiert une grammaire sans contexte, relativement simple à parser, contrairement au HTML qui fonctionne avec une grammaire avec contexte.
À l’issue de ces opérations de parsing, des arbres de syntaxe vont être obtenus : la plus connue étant le DOM (Document Object Model) en HTML, et son équivalent CSS est le CSSOM (CSS Object Model).

Le render tree
Une fois les actions de parsing réalisées sur le HTML et le CSS, les mots clés identifiés, les règles de syntaxe appliquées, vient ensuite l’étape du render tree. Il s’agit de la représentation visuelle du document. Le render tree doit permettre de dessiner le contenu dans l’ordre correct tout en contenant l’ensemble des éléments visibles.
Il faut faire ici attention avec l’utilisation de « display: none », qui ne place pas l’élément concerné dans le render tree. En utilisant cette propriété, cela va entraîner un recalcul du render tree, qui va être trop gourmand pour le navigateur, avec le risque que cela puisse dégrader les performances de votre application. À la place, il convient d’utiliser la propriété “visibility” du CSS, qui va cacher l’élément et le laisser dans le render tree.
Sur le render tree, l’intervenant précise également que sa construction va nécessiter le calcul des propriétés visuelles de chaque objet. Ce calcul représente une opération complexe, et peut être “sujet à de potentielles problématiques de performances” .
Évitez les sélecteurs CSS trop complexes, qui vont impacter trop de balises HTML et complexifier le calcul du render tree. Les bonnes pratiques les plus courantes consistent à appliquer du CSS avec un identifiant mis sur un élément HTML ou par des class CSS, plutôt qu’en passant par des sélecteurs.
La partie “dessin”
Lorsque le render tree contient l’ensemble des éléments qui doivent être affichés, et que les propriétés CSS ont été calculées pour pouvoir être appliquées, place à la partie “dessin” ! Selon le directeur de l’agence Zenika Brest, elle se compose des 3 éléments suivants :
- Le layout : c’est le processus de définition de la position et de la taille des éléments, avec un style global ou incrémental (basé sur le principe de “dirty bit”).
- Le paint : c’est le processus de parcours du render tree pour dessiner chacun des éléments, avec également un style global ou incrémental (basé lui aussi sur le principe de “dirty bit”). À noter que l’ordre du processus de painting est : background color , background image , border , children et outline .
- Le composite : c’est le processus qui va permettre de gérer l’empilement des calques, l’opacité et les transformations.
C’est lors de cette étape du composite que l’on va intervenir pour optimiser des animations CSS, et éviter les lenteurs au niveau de vos performances.
- La newsletter “has been” ? Bien au contraire…
- Micro-interactions en UX design : petits détails, grand impact !
- L’inclusion, une responsabilité pour les concepteurs d’expériences numériques
- Impact environnemental des sites web : dans les coulisses des outils de mesure
- Influenceurs et réseaux sociaux : quelle relation à l’heure de la creator economy ?
- Startups : 5 conseils d’entrepreneur pour tirer profit de l’intelligence humaine
- IA génératives : comment des outils comme ChatGPT et Midjourney vont-ils impacter notre avenir ?
Explorer les métiers du développement informatique
- Développement
Votre adresse email ne sera pas publiée.
Les meilleurs logiciels pour les développeurs
Surfshark VPN
Dexem Call Tracking
Recevez par email toute l’actualité du digital.
En cliquant sur "S'inscrire", vous acceptez les CGU ainsi que notre politique de confidentialité décrivant la finalité des traitements de vos données personnelles.
Sur le même thème
Développeurs : 7 bonnes pratiques seo pour votre site web, les 20 langages informatiques les plus populaires en juin 2024, quels sont les langages les plus aimés et détestés par les développeurs en 2023 , 5 compétences indispensables pour devenir développeur web, tout savoir sur chatgpt : accès, cas d’usages, limites, paramètres, seo, détection, alternatives…, chatgpt : notre guide pour créer les meilleurs prompts.
Qu’est-ce qu’un navigateur ? Simplement expliqué

La définition d’un navigateur est facile à expliquer : Il s’agit d’un logiciel qui facilite la navigation sur Internet. Il existe différents navigateurs que vous pouvez utiliser en fonction de votre appareil et de votre système d’exploitation.
Qu’est-ce qu’un navigateur?
Les navigateurs web sont votre porte d’entrée sur le World Wide Web. Mais comment cela fonctionne-t-il ?
- Un navigateur – en anglais, cela signifie « fureteur » – est un programme qui permet d’afficher correctement les sites web.
- Lorsque vous visitez un site Internet, vous ne vous contentez pas d’ouvrir le produit fini. Au lieu de cela, votre navigateur reçoit des instructions qu’il assemble ensuite pour former le site Web.
- Comme tous les navigateurs ne parlent pas toutes les langues et tous les dialectes, c’est-à-dire ne comprennent pas les différentes versions de HTML, il peut arriver que Firefox, par exemple, affiche un site web un peu différemment de Google Chrome.
- De même, il se peut qu’une ancienne version ne comprenne pas autant de langues qu’une nouvelle. C’est pourquoi il est important de maintenir le navigateur de votre choix à jour
- Les fonctions de base sont toutefois les mêmes partout, de sorte que la plupart des sites web devraient fonctionner de la même manière dans tous les navigateurs. Dans tous les cas, vous verrez toujours le texte, les images et les liens comme prévu
- Sur les smartphones, les navigateurs ont certes un aspect légèrement différent et plus compact, mais ils fonctionnent de la même manière que sur votre ordinateur.
- La plupart des navigateurs ont des fonctions supplémentaires. Il existe par exemple des variantes de Firefox qui ont des fonctions intégrées de médias sociaux ou d’anonymat et qui répondent ainsi à vos besoins personnels.

Déménagement : de quoi a-t-on besoin pour que tout se passe bien ?
Stray : trophées – comment débloquer tous les succès, related articles, créer des images avec chatgpt : ce que..., utiliser un dumbphone avec whatsapp : ce que..., fiona fuchs : fiche signalétique de l’actrice porno, que signifie vérifier – explication simple, que veut dire dito l’abréviation expliquée simplement, qu’est-ce que x (anciennement twitter) une explication..., bouche à baiser : la signification de l’emoji..., meme : définition et origine du terme internet, qu’est-ce que gmx explication simple, qu’est-ce qu’une campagne explication et exemples, leave a comment cancel reply.
Save my name, email, and website in this browser for the next time I comment.
- Parcours de formation
Accueil | Je découvre | Internet | Qu’est ce qu’un navigateur Web ?
Qu’est ce qu’un navigateur Web ? Quels sont les principaux navigateurs Web ? Présentation de Firefox, Edge, Google Chrome, Safari.
1- Un navigateur web c’est quoi ?
Un navigateur est un outil permettant de naviguer et de consulter les pages web disponibles sur le Word Wide Web. En pratique, le navigateur nous traduit en texte et image les pages d’information qui sont codées en HTML.
En pratique, le navigateur c’est l’équivalent de votre voiture pour vous déplacer sur le réseau routier Internet.
Pour visiter le site coursinfo.fondation-os.fr ou www.bnf.fr , vous utilisez un navigateur qui vous permet de vous déplacer sur le réseau routier Internet afin d’y aller.
2- L’interface graphique d’un navigateur web
Un navigateu r est une application possédant une interface graphique composée :
- de flèches de navigation, pour naviguer dans l’historique des différents liens visités
- d’une barre d’adresse pour saisir l’adresse d’un site web à consulter
- d’une barre personnelle pour abriter les favoris (raccourci vers des sites web préférés)
- d’une zone d’affichage des pages Web gérée sous forme d’onglets
- et d’une barre d’état (en bas de fenêtre) pour visualiser l’adresse des hyperliens …

3. Les principaux navigateurs Web
Il existe de nombreux navigateurs Web, mais les plus populaires sont : Firefox de Mozzila, Edge de Microsoft (le remplaçant d’Internet Explorer), Google Chrome et Safari d’Apple. Ils sont tous gratuits.
3.1 Le navigateur Firefox
Firefox, le navigateur de la fondation Mozzila est le plus apprécié des internautes. C’est aussi le navigateur le plus avancé en terme de fonctionnalités et de sécurité. C’est celui que nous recommandons pour tous.

Cliquez pour télécharger Firefox .
3.2 Le navigateur Edge
Livré avec Windows 10, le navigateur Edge remplace le très célèbre Internet Explorer de Microsoft.

3.3 Le navigateur Google Chrome
Google Chrome est le navigateur le plus utilisé dans la recherche d’information (c’est fait par Google bien sûr).

3.4 Le navigateur Safari
Safari, le célèbre navigateur web d’Apple est désormais disponible sur Windows 10. Safari est reconnu pour ses performances surtout au niveau des développeurs. La vitesse de chargement des pages Web est très rapide.

Chapitre suivant : comment paramétrer Firefox ?
- Skip to main content
- Skip to search
- Skip to select language
- Sign up for free
- English (US)
Cette page a été traduite à partir de l'anglais par la communauté. Vous pouvez également contribuer en rejoignant la communauté francophone sur MDN Web Docs.
Remplir la page: comment fonctionnent les navigateurs
Les utilisateurs veulent des expériences Web avec un contenu rapide à charger et une interaction fluide. Par conséquent, un développeur doit s'efforcer d'atteindre ces deux objectifs.
Pour comprendre comment améliorer les performances et les performances perçues, il est utile de comprendre le fonctionnement du navigateur.
Vue générale
Les sites rapides offrent une meilleure expérience utilisateur. Les utilisateurs veulent et s'attendent à des expériences Web avec un contenu rapide à charger et à interagir avec fluidité.
La compréhension des problèmes liés 1) à la latence et 2) les problèmes liés au fait que, dans la plupart des cas, les navigateurs fonctionné à un seul thread. Cela sont deux problèmes majeurs dans les performances Web.
La latence est notre principale menace à surmonter pour assurer une charge rapide. Pour être rapides à charger, les objectifs des développeurs incluent l'envoi des informations demandées aussi rapidement que possible, ou du moins, cela semble super rapide. La latence du réseau est le temps nécessaire pour transmettre des octets par liaison radio aux ordinateurs. La performance Web est ce que nous devons faire pour que le chargement de la page se fasse le plus rapidement possible.
Pour la plupart, les navigateurs sont considérés comme un seul thread. Pour que les interactions se déroulent sans heurt, l'objectif du développeur est d'assurer des interactions de site performantes, du défilement en douceur à la réactivité au touchers Le temps de rendu est essentiel, car il permet de s'assurer que le fil principal peut effectuer tout le travail que nous lui faisons, tout en restant disponible pour gérer les interactions de l'utilisateur.
Les performances Web peuvent être améliorées en comprenant le caractère mono-thread du navigateur et en minimisant les responsabilités du thread principal, lorsque cela est possible et approprié, pour assurer un rendu fluide et des réponses aux interactions immédiates.
La navigation est la première étape du chargement d'une page Web. Cela se produit chaque fois qu'un utilisateur demande une page en saisissant une URL dans la barre d'adresse, en cliquant sur un lien, en soumettant un formulaire, ainsi que d'autres actions.
L'un des objectifs de la performance Web est de minimiser le temps de navigation. Dans des conditions idéales, cela ne prend généralement pas trop de temps, mais la latence et la bande passante sont des ennemis qui peuvent causer des retards.
Recherche DNS
La première étape de la navigation vers une page Web consiste à rechercher l'emplacement des actifs de cette page. Si vous accédez à https://example.com , la page HTML se trouve sur le serveur avec l'adresse IP de 93.184.216.34 . Si vous n'avez jamais visité ce site, une recherche DNS doit être effectuée.
Votre navigateur demande une recherche DNS, qui est éventuellement effectuée par un serveur de noms, qui lui-même répond avec une adresse IP. Après cette demande initiale, l'adresse IP sera probablement mise en cache pendant un certain temps, ce qui accélérera les demandes suivantes en récupérant l'adresse IP du cache au lieu de contacter à nouveau un serveur de noms.<
Les recherches DNS ne doivent généralement être effectuées qu'une fois par nom d'hôte pour le chargement d'une page. Cependant, des recherches DNS doivent être effectuées pour chaque nom d'hôte unique référencé par la page demandée.
Si vos fichier de police, images, scripts, publicites/annonces et métriques ont tous un nom d'hôte différent, une recherche DNS devra être effectuée pour chacun d'eux.
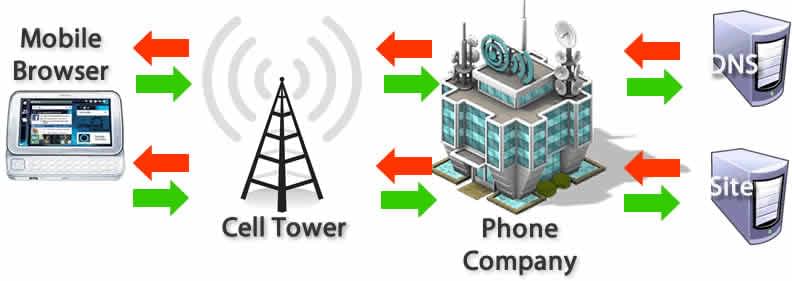
Cela peut être problématique pour les performances, en particulier sur les réseaux mobiles. Lorsqu'un utilisateur est sur un réseau mobile, chaque recherche DNS doit aller du téléphone à la tour cellulaire pour atteindre un serveur DNS faisant autorité. La distance entre un téléphone, une tour de téléphonie cellulaire et le serveur de noms peut ajouter une latence significative.
TCP Handshake
Une fois que l'adresse IP est connue, le navigateur établit une connexion avec le serveur via un négociation de liaison TCP à trois voies . TCe mécanisme est conçu pour que deux entités essayant de communiquer, dans ce cas le navigateur et le serveur Web, puissent négocier les paramètres de la connexion de socket TCP sur le réseau avant de transmettre des données, souvent sur HTTPS .
La technique de négociation à trois voies de TCP est souvent appelée "SYN-SYN-ACK", ou plus précisément SYN, SYN-ACK, ACK, car trois messages sont transmis par TCP pour négocier et démarrer une session TCP entre deux ordinateurs. Oui, cela signifie trois messages supplémentaires entre chaque serveur et la demande doit encore être faite.
Negotiation TLS
Pour les connexions sécurisées établies via HTTPS, une autre "liaison" est requise. Cette négociation, ou plutôt la négociation TLS , détermine quel chiffrement sera utilisé pour chiffrer la communication, vérifie le serveur et établit qu'une connexion sécurisée est en place avant de commencer le transfert effectif des données. Cela nécessite encore trois allers-retours vers le serveur avant que la demande de contenu ne soit réellement envoyée.
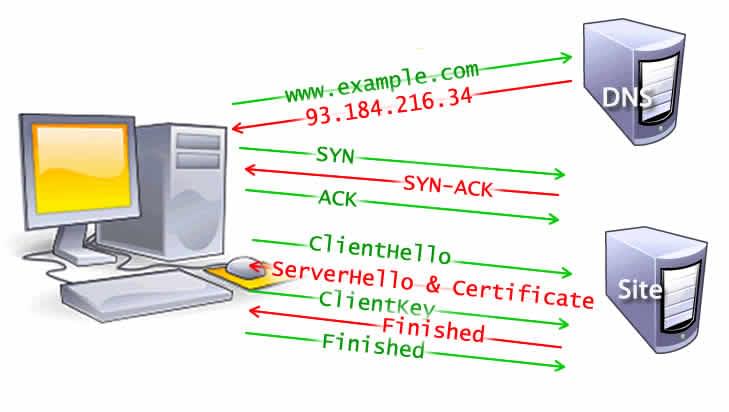
Bien que sécuriser la connexion ajoute du temps au chargement de la page, une connexion sécurisée vaut la dépense en latence, car les données transmises entre le navigateur et le serveur Web ne peuvent pas être déchiffrées par un tiers.
Après les 8 allers-retours, le navigateur est enfin en mesure de faire la demande.
Une fois la connexion établie avec un serveur Web établie, le navigateur envoie une demande HTTP GET initiale au nom de l'utilisateur, qui pour les sites Web est le plus souvent un fichier HTML. Dès que le serveur reçoit la demande, il répond avec les en-têtes de réponse pertinents et le contenu du code HTML.
La réponse pour cette demande initiale contient le premier octet de données reçu. Time to First Byte (TTFB) est le temps écoulé entre le moment où l'utilisateur a fait la demande (disons en cliquant sur un lien) et la réception du premier paquet HTML. Le premier bloc de contenu est généralement constitué de 14 Kb de données.
Dans notre exemple ci-dessus, la demande est nettement inférieure à 14 Kb, mais les ressources liées ne sont pas demandées tant que le navigateur n'a pas rencontré les liens lors de l'analyse, décrit ci-dessous.
TCP Slow Start / 14kb rule
Le premier paquet de réponse sera de 14 Kb. Cela fait partie de TCP slow start , un algorithme qui équilibre la vitesse d'une connexion réseau. Le démarrage lent augmente progressivement la quantité de données transmises jusqu'à ce que la bande passante maximale du réseau puisse être déterminée.
Avec un TCP slow start , après la réception du paquet initial, le serveur double la taille du paquet suivant, pour atteindre environ 28 Kb. La taille des paquets suivants augmente jusqu'à atteindre un seuil prédéterminé ou jusqu'à ce qu'un encombrement se produise.

Si vous avez déjà entendu parler de la règle de 14 Kb pour le chargement de page initial, c'est le démarrage lent de TCP qui explique pourquoi la réponse initiale est de 14 Ko et pourquoi l'optimisation des performances Web appelle à l'optimisation de la focalisation avec cette réponse initiale à l'esprit. Le démarrage lent TCP augmente progressivement les vitesses de transmission en fonction des capacités du réseau afin d'éviter les encombrements.
Contrôle congestion
Lorsque le serveur envoie des données sous forme de paquets TCP, le client de l'utilisateur confirme la livraison en renvoyant des accusés de réception, ou ACK. La connexion a une capacité limitée en fonction des conditions matérielles et du réseau. Si le serveur envoie trop de paquets trop rapidement, ils seront supprimés. Sens, il n'y aura pas de reconnaissance. Le serveur l'enregistre comme ACK manquant. Les algorithmes de contrôle d'encombrement utilisent ce flux de paquets envoyés et d'accusés de réception pour déterminer un débit d'envoi.
Une fois que le navigateur a reçu le premier bloc de données, il peut commencer à analyser les informations reçues. L'analyse, our parsing , est l'étape par laquelle le navigateur prend pour transformer les données qu'il reçoit sur le réseau en DOM et CSSOM , qui est utilisé par le moteur de rendu pour peindre une page à l'écran.
Le DOM est la représentation interne du balisage pour le navigateur. Le DOM est également exposé et peut être manipulé via diverses API en JavaScript.
Même si le code HTML de la page de demande est plus volumineux que le paquet initial de 14 Kb, le navigateur commencera à analyser et à tenter de restituer une expérience en fonction des données dont il dispose. C'est pourquoi il est important pour l'optimisation des performances Web d'inclure tout ce dont le navigateur a besoin pour commencer le rendu d'une page, ou du moins d'un modèle de page - les CSS et HTML nécessaires au premier rendu - dans les 14 premiers kilo-octets. Mais avant que tout ne soit rendu à l'écran, le HTML, CSS et JavaScript doivent être analysés.
Building the DOM tree
Nous décrivons cinq étapes dans le chemin de rendu critique, ou " critical rendering path ".
La première étape consiste à traiter le balisage HTML et à créer l'arborescence DOM. L'analyse HTML implique la création de jetons, tokenization, et la construction du DOM tree. Les jetons HTML incluent les balises de début et de fin, ainsi que les noms et les valeurs des attributs. Si le document est bien formé, son analyse est simple et rapide. L'analyseur analyse les entrées sous forme de jetons dans le document, créant ainsi le document tree.
Le DOM tree décrit le contenu du document. L'élément <html> est la première balise et le premier nœud racine de du document tree. L'arbre reflète les relations et les hiérarchies entre différentes balises. Les balises imbriquées dans d'autres balises sont des nœuds enfants. Plus le nombre de nœuds DOM est élevé, le plus de temps ca prends pour construire le DOM tree.
Lorsque l'analyseur trouve des ressources non bloquantes, telles qu'une image, le navigateur demande ces ressources et poursuit l'analyse. L'analyse peut continuer lorsqu'un fichier CSS est rencontré, mais les balises <script> , en particulier celles sans attribut async ou defer , bloquent le rendu et mettent en pause l'analyse du code HTML. Bien que le scanner de précharge du navigateur accélère ce processus, le nombre excessif de scripts peut toujours constituer un goulot d'étranglement important.
Preload scanner
Pendant que le navigateur construit le DOM tree, ce processus occupe le thread principal. Dans ce cas, le scanner de préchargement analysera le contenu disponible et demandera des ressources hautement prioritaires telles que CSS, JavaScript et les polices. Grâce à l'analyseur de précharge, il n'est pas nécessaire d'attendre que l'analyseur trouve une référence à une ressource externe pour la demander. Il récupérera les ressources en arrière-plan, de sorte qu'au moment où l'analyseur HTML principal atteindra les actifs demandés, il se peut qu'ils soient déjà en vol ou aient été téléchargés. Les optimisations fournies par le scanner de précharge permettent de réduire les blocages.
Dans cet exemple, alors que le fil principal analyse HTML et CSS, le scanner de préchargement trouvera les scripts et l'image, et commencera également à les télécharger. Pour vous assurer que le script ne bloque pas le processus, ajoutez l'attribut async ou defer si l'analyse et l'exécution de JavaScript ne sont pas importantes.
L'attente pour obtenir CSS ne bloque pas l'analyse ou le téléchargement HTML, mais bloque JavaScript, car JavaScript est souvent utilisé pour rechercher l'impact des propriétés CSS sur les éléments.
Construction du CSSOM
La deuxième étape du chemin de rendu critique est le traitement de CSS et la construction du CSSOM. Le modèle d'objet CSS est similaire au DOM. Les DOM et CSSOM sont deux arbres. Ce sont des structures de données indépendantes. Le navigateur convertit les règles CSS en une carte de styles qu'il peut comprendre et utiliser. Le navigateur passe en revue chaque ensemble de règles de la feuille de style CSS, créant ainsi une arbre de noeuds avec des relations parent, enfant et sœurs basées sur les sélecteurs CSS.
Comme avec HTML, le navigateur doit convertir les règles CSS reçues en quelque chose avec lequel il peut travailler. Par conséquent, il répète le processus HTML-à-object, mais pour le CSS.
L'arbre CSSOM comprend les styles du stylesheet de l'agent utilisateur. Le navigateur commence par la règle la plus générale applicable à un nœud et affine de manière récursive les styles calculés en appliquant des règles plus spécifiques. En d'autres termes, il cascade les valeurs de propriété.
La construction du CSSOM est très, très rapide et n'est pas affiché dans une couleur unique dans les outils de développement actuels. Le "Style recalculé" dans les outils de développement indique le temps total nécessaire à l'analyse CSS, à la construction du CSSOM et au calcul récursif des styles calculés. En ce qui concerne l'optimisation des performances Web, l'effet de l'effort d'optimisation de la construction CSSOM crée sont minimes, car le temps total nécessaire pour créer le CSSOM est généralement inférieur au temps requis pour une recherche DNS.
Autres Processus
Compilation javascript.
Lors de l'analyse du CSS et de la création du CSSOM, d'autres ressources, notamment des fichiers JavaScript, sont en cours de téléchargement (grâce au scanner de préchargement). JavaScript est interprété, compilé, analysé et exécuté. Les scripts sont analysés dans des arbres à syntaxe abstraite. Certains moteurs de navigateur utilisent le Arbre de syntaxe abstraite et le transmettent à un interpréteur, générant le code binaire exécuté sur le thread principal. Ceci est connu sous le nom de compilation JavaScript.
Construire l'arbre d'accessibilité
Le navigateur crée également une arbre d' accessibilité que les périphériques d'assistance utilisent pour analyser et interpréter le contenu. Le modèle d'objet d'accessibilité (AOM) est comme une version sémantique du DOM. Le navigateur met à jour l'arbre d'accessibilité lorsque le DOM est mis à jour. L'arbre d'accessibilité n'est pas modifiable par les technologies d'assistance elles-mêmes.
Jusqu'à la construction de l'AOM, le contenu n'est pas accessible aux lecteurs d'écran .
Les étapes de rendu incluent le style, la mise en page, la peinture et, dans certains cas, la composition. Les arbres CSSOM et DOM créés à l'étape d'analyse sont combinés en un arbre de rendu qui est ensuite utilisé pour calculer la mise en page de chaque élément visible, qui est ensuite peint à l'écran. Dans certains cas, le contenu peut être promu dans ses propres couches et composé, ce qui améliore les performances en peignant des parties de l'écran sur le GPU au lieu du CPU, libérant ainsi le thread principal.
La troisième étape du chemin de rendu critique consiste à combiner le DOM et CSSOM dans une arborescence de rendu. La construction de l'arbre de style calculé ou de l'arbre de rendu commence à la racine de l'arborescence DOM, en traversant chaque nœud visible.
Les balises qui ne vont pas être affichées, telles que <head> et ses enfants, ainsi que tous les nœuds avec display: none , tel que le script { display: none;} vous trouverez dans les feuilles de style de l'agent utilisateur, ne sont pas inclus dans l'arborescence de rendu car ils n'apparaîtront pas dans la sortie rendue. Les nœuds avec visibility: hidden appliqué sont inclus dans l'arborescence de rendu, car ils occupent de l'espace. Comme nous n'avons donné aucune directive pour remplacer la valeur par défaut de l'agent utilisateur, le noeud de script de notre exemple de code ci-dessus ne sera pas inclus dans l'arbre de rendu.
Les règles CSSOM sont appliquées à chaque nœud visible. L'arborescence de rendu contient tous les nœuds visibles avec le contenu et les styles calculés - en faisant correspondre tous les styles pertinents à chaque nœud visible du DOM tree et en déterminant, en fonction de la cascade CSS, les styles calculés pour chaque nœud.
Disposition
La quatrième étape du chemin de rendu critique consiste à exécuter la disposition sur l'arbre de rendu pour calculer la géométrie de chaque noeud.
La disposition est le processus par lequel la largeur, la hauteur et l'emplacement de tous les noeuds de l'arbre de rendu sont déterminés, ainsi que la détermination de la taille et de la position de chaque objet sur la page. La redistribution correspond à toute détermination ultérieure de la taille et de la position d'une partie de la page ou du document dans son ensemble.
Une fois que l'arborescence de rendu est construite, la mise en page commence. L'arbre de rendu identifiait les nœuds affichés (même s'ils étaient invisibles) avec leurs styles calculés, mais pas les dimensions ou l'emplacement de chaque nœud. Pour déterminer la taille et l'emplacement exact de chaque objet, le navigateur commence à la racine de l'arbre de rendu et le traverse.
Sur la page Web, presque tout est une boîte. Différents périphériques et différentes préférences de bureau signifient un nombre illimité de tailles de fenêtres d'affichage différentes. Au cours de cette phase, prenant en compte la taille de la fenêtre d'affichage, le navigateur détermine les dimensions de toutes les différentes boîtes à l'écran. En prenant la taille de la fenêtre comme base, la présentation commence généralement par le corps, elle présente les dimensions de tous les descendants du corps, ainsi que les propriétés du modèle de boîte de chaque élément, offrant ainsi un espace réservé aux éléments remplacés dont il ne connaît pas les dimensions: comme notre image.
La première fois que la taille et la position des nœuds sont déterminées est appelée "mise en page", ou layout . Les recalculs ultérieurs de la taille et des emplacements des noeuds sont appelés redistributions, ou reflows . Dans notre exemple, supposons que la mise en page initiale se produise avant que l'image ne soit renvoyée. Comme nous n'avons pas déclaré la taille de notre image, il y aura un reflow une fois que la taille de l'image est connue.
La dernière étape du chemin de rendu critique consiste à peindre les nœuds individuels à l'écran, la première occurrence étant appelée la première peinture significative, ou first meaningful paint .
Lors de la phase de peinture ou de rastérisation, le navigateur convertit chaque case calculée lors de la phase de mise en page en pixels réels à l'écran. La peinture implique de dessiner chaque partie visuelle d'un élément sur l'écran, y compris le texte, les couleurs, les bordures, les ombres et les éléments remplacés, comme les boutons et les images. Le navigateur doit faire cela très rapidement.
Pour assurer un défilement et une animation fluides, tout ce qui occupe le fil principal, y compris le calcul des styles, ainsi que le redistribution et la peinture, doit nécessiter moins de 16,67ms de navigateur.
À 2048 X 1536, l'iPad a plus de 3 145 000 pixels à peindre à l'écran. C'est beaucoup de pixels qui doivent être peints très rapidement. Afin de pouvoir repeindre même plus rapidement que la peinture initiale, le dessin à l'écran est généralement divisé en plusieurs couches, ou layers . Si cela se produit, la composition est nécessaire.
La peinture peut diviser les éléments de l'arborescence en couches. La promotion du contenu en couches sur le GPU (au lieu du thread principal sur le CPU) améliore la performances de la peinture originale et chaque la performances de repeinte supplémentaire.
Il existe des propriétés et des éléments spécifiques qui instancient un calque, notamment <video> et <canvas> , ainsi que tout élément possédant les propriétés CSS d' opacité , de transformation 3D , de et de plusieurs valeur de will-change , isolation et contain . Ces nœuds seront peints sur leur propre calque, avec leurs descendants, à moins qu'un descendant ne nécessite son propre calque pour une (ou plusieurs) des raisons ci-dessus.
Les couches améliorent les performances, mais sont coûteuses en termes de gestion de la mémoire et ne doivent donc pas être utilisées de manière excessive dans les stratégies d'optimisation des performances Web.
Composition
Lorsque des sections du document sont dessinées dans différentes couches se chevauchant, la composition est nécessaire pour garantir qu'elles sont dessinées à l'écran dans le bon ordre et que le contenu est restitué correctement.
Si la page continue de charger des ressources, des retraits peuvent se produire (rappelez-vous notre exemple d'image arrivé en retard). Un reflux déclenche un repeinte et un recomposition. Si nous avions défini la taille de notre image, aucune refusion n'aurait été nécessaire, et seule la couche à repeindre serait repeinte et composée si nécessaire. Mais nous n'avons pas inclus la taille de l'image! Lorsque l'image est obtenue à partir du serveur, le processus de rendu reprend les étapes de la mise en page et redémarre à partir de là.
L'interactivité
Une fois que le fil principal est terminé, on pourrait penser que nous serions "tout prêt". Ce n'est pas nécessairement le cas. Si le chargement inclut JavaScript, correctement différé et exécuté uniquement après le déclenchement de l'événement onload , le thread principal est peut-être occupé et indisponible pour les interactions de défilement, tactiles et autres.
Time to Interactive (TTI) est la mesure du temps qu'il a fallu à cette première demande pour aboutir à la recherche DNS et à la connexion SSL lorsque la page est interactive - interactif étant le point dans le temps après le First Contentful Paint lorsque la page répond aux interactions de l'utilisateur dans un délai de 50 ms. Si le thread principal est occupé à analyser, compiler et exécuter JavaScript, il n'est pas disponible et ne peut donc pas répondre aux interactions de l'utilisateur dans les meilleurs délais (moins de 50 ms).
Dans notre exemple, l'image a peut-être été chargée rapidement, mais le fichier unautrescript.js faisait 2 MB et la connexion réseau de notre utilisateur était lente. Dans ce cas, l'utilisateur verrait la page très rapidement, mais ne pourrait pas faire défiler sans jank jusqu'à ce que le script soit téléchargé, analysé et exécuté. Ce n'est pas une bonne expérience utilisateur. Évitez d'occuper le fil principal, comme illustré dans cet exemple WebPageTest :
Dans cet exemple, le processus de chargement du contenu du DOM a duré plus de 1,5 seconde et le thread principal a été entièrement occupé pendant tout ce temps, ne répondant pas pour cliquer sur des événements ou sur des taps à l'écran.
- Web Performance
Dépassez les objectifs de votre investissement Hubspot ! Rejoignez notre communauté et donnez-vous les moyens de réussir
Firefox n’est plus pris en charge sur Windows 8.1 et les versions antérieures.
Veuillez télécharger Firefox ESR (édition longue durée) pour utiliser Firefox.
Télécharger Firefox ESR 64 bits
Télécharger Firefox ESR 32 bits
Firefox n’est plus pris en charge sur macOS 10.14 et les versions antérieures.
Fonctionnalités du navigateur Firefox
Firefox est le navigateur rapide, léger et respectueux de la vie privée qui fonctionne sur tous vos appareils.

Firefox est de plus en plus rapide
Les dernières mesures de référence de la vitesse des navigateurs prouvent que Firefox est plus rapide que jamais.

Firefox est-il un navigateur qui protège ma vie privée ?
Votre droit à la vie privée est au cœur de notre mission. Vos données, votre activité sur le Web et votre vie numérique sont protégées avec Firefox.
Gestionnaire de mots de passe gratuit
Obtenez de l’aide pour créer de nouveaux mots de passe, remplir automatiquement les formulaires en ligne et vous connecter automatiquement.
En savoir plus
Synchronisation du navigateur Firefox
Accédez à vos marque-pages, mots de passe, onglets ouverts et plus encore sur Firefox depuis n’importe quel appareil.
Gestion des marque-pages
Organisez vos marque-pages avec des dossiers et des étiquettes.
Mode de navigation privée
Supprimez automatiquement les cookies et effacez votre historique de navigation chaque fois que vous fermez le navigateur.
Personnalisez votre navigateur Firefox
Choisissez l’apparence de votre navigateur avec des milliers de thèmes gratuits.
Extensions et modules Firefox
Ajoutez de nouveaux outils, de nouvelles capacités et des fonctions amusantes à votre navigateur.
Onglets épinglés
Gardez vos pages préférées ouvertes et à portée de clic. Utilisez les onglets épinglés pour garder un œil sur vos e-mails ou votre application de messagerie.
Pipette à couleurs
Identifiez une couleur exacte sur une page web et copiez son code hexadécimal.
Visualisez et éditez des fichiers PDF directement dans Firefox.
Blocage de l’empreinte numérique
Débarrassez-vous des publicités qui vous suivent partout grâce aux bloqueurs de détecteurs d’empreintes numériques intégrés au navigateur Firefox.
Blocage des traqueurs publicitaires
Firefox empêche automatiquement plus de 2 000 traqueurs de vous suivre sur Internet.
Traduisez le Web
Traduisez des sites web dans votre langue directement depuis votre navigateur Firefox, sans partager vos données.
Incrustation vidéo
Vous avez des choses à faire et de vidéos à regarder ? Vous pouvez maintenant tout faire en même temps en utilisant l’incrustation vidéo de Firefox.
- Nous suivre sur Google actualités
- Se Connecter
- Hotel France
- Campings France
- Inscrire son établissement
- Restaurants de France
- Recettes de cuisine
- Tourisme en France
- Musées de France
- Golfs de France
- Jeux en ligne
- Blague / Humour
- Calendrier lunaire
- Programme TV
- Offres d'emplois
- Associations de France
- Aéroports de france
- Parkings France
- Bornes recharge électrique
- Toilettes France
- Mairies France
- Nos Dossiers
- Par catégories
- Inscrire son site

- Internet et Webmaster
- World Wide Web et internet
- Le navigateur web : présentation et fonctionnement
Le Navigateur Web : Présentation Et Fonctionnement
Le navigateur web est le logiciel permettant aux internautes de "surfer" entre les pages des sites web qu’ils consultent. nous vous proposons de découvrir l’histoire et le fonctionnement de ces logiciels qui offrent sans cesse des fonctionnalités nouvelles..
- 30 juin 2008
- Temps de lecture moyen : 2'23
Présentation
Un navigateur web est un logiciel conçu pour surfer sur le World Wide web et en consulter les pages. Sur le plan technique, un navigateur est au minimum un client Http c’est-à-dire un logiciel conçu pour se connecter à un serveur HTTP . Ce type de logiciel comprend un moteur de rendu des standards du web, une interface utilisateur et, éventuellement, un gestionnaire d'extensions ou plugins . La grande majorité des navigateurs présentent une interface utilisateur composée d'une zone d'affichage (éventuellement gérée sous forme d'onglets), d'une barre de menus déroulants, d'une barre d'outils et d'une barre d'état.
Petite histoire des navigateurs web
Les navigateurs web sont des logiciels en constante évolution, car ils doivent offrir sans cesse de nouvelles fonctionnalités correspondant aux nouveaux standards du web et se protéger contre de nouveaux virus, spywares et autres scripts malveillants. Le premier navigateur, originellement appelé WorldWideWeb (puis rebaptisé nexus ) a été développé en 1990 . Néanmoins le premier navigateur web à avoir été largement diffusé fut NCSA Mosaic en 1993. A partir de 1995 , ce secteur a été dominé par Netscape Navigator , le logiciel développé par Marc Andreessen. Internet Explorer 1 de Microsoft a vu le jour la même année. A noter : le terme de "navigateur" web ou "navigateur" Internet a d’ailleurs été inspiré par le nom de Netscape Navigator. Au Québec on parle aussi de "fureteur", butineur, arpenteur ou fouineur. Depuis 2000, Internet Explorer est le navigateur le plus utilisé, même si Mozilla Firefox progresse. Par ailleurs, il existe d’autres navigateurs dits "alternatifs" tels que Opera et Safari qui proposent des innovations et des solutions de qualité.
Principe de fonctionnement
Le rôle d'un navigateur web est principalement de permettre la consultation des informations disponibles sur le web. Pour consulter une page ou ressource, l'utilisateur doit indiquer au navigateur web l'adresse web de cette ressource. Pour ce faire, il peut : - taper l'adresse web dans la barre d'adresse du navigateur - choisir une ressource dans sa liste de favoris - suivre un lien hypertexte pour accéder à une autre page. Le navigateur se connecte au serveur web hébergeant la ressource et la télécharge, en utilisant généralement le protocole de communication HTTP. Le moteur de rendu du navigateur traite la ressource et affiche le résultat sur l'écran de l'utilisateur. L’ interface graphique sert à afficher le résultat et présente des boutons de navigation, une barre d'adresse et une barre d'état.
Les fonctionnalités des navigateurs
Un navigateur web est capable, au minimum, d'afficher le texte d'une page web (navigateur en mode texte). Néanmoins, les navigateurs fonctionnent couramment en mode graphique : ils sont capables afficher une typographie élaborée, des images et des animations et d'interagir avec les actions de l'utilisateur. Le langage informatique HTML (Hypertext Markup Language) indique au navigateur le texte à afficher ainsi que la structure générale de la mise en page. L'utilisation du Css (ou feuilles de style en cascade) permet de définir une mise en page plus élaborée avec des marges, alignements, espacements, couleurs et bordures. La plupart des navigateurs permettent aussi d'imprimer les pages web. Certains sont compatibles avec des dispositifs permettant de pallier un handicap visuel ou moteur. Par ailleurs, les navigateurs exécutent des scripts c’est-à-dire des programmes informatiques intégrés aux pages web pour réaliser des tâches simples (vérifier les données d’un formulaire ou gérer des menus…). JavaScript est le principal langage de script utilisé sur le web.
Plus d'information :
Tag : navigateur web, navigateurs web, navigateur Internet, fonctionnement navigateur web, histoire des navigateurs web , Web , navigateur , logiciel , navigateur web , Netscape Navigator , interface utilisateur, moteur de rendu, logiciels , serveur web , mode texte, Safari , navigation , interface graphique , HTTP , protocole de communication , hypertexte , mode graphique, typographie , langage de script , JavaScript , programmes informatiques , Handicap visuel , pages web , feuilles de style , HyperText Markup Language , HTML , langage informatique , Mozilla Firefox , Internet Explorer , 1990 , spywares , virus , navigateurs web , barre de menus déroulants, plugins, Serveur http, client http, NCSA Mosaic , 1993 , 2000 , arpenteur, Québec , navigateur Internet , Microsoft , Internet Explorer 1, Andreessen, 1995 , sites web ,
Donner votre avis

Naviguer sur le web : Les navigateurs Internet expliqués
Les navigateurs Internet sont nos portails vers le vaste monde du web. Que vous souhaitiez lire des nouvelles, vérifier vos e-mails ou regarder des vidéos, tout commence par l'ouverture d'un navigateur.
Qu'est-ce qu'un navigateur Internet?
Un navigateur est une application logicielle conçue pour vous permettre d'accéder et de naviguer sur des sites web. Il interprète le code HTML et d'autres langages de programmation pour présenter le contenu dans un format lisible.
Les types de navigateurs
Il existe plusieurs navigateurs, mais les plus populaires sont Chrome, Firefox, Safari et Edge. Chacun a ses propres caractéristiques et avantages.
Comment fonctionne un navigateur?
Lorsque vous tapez une adresse web, le navigateur communique avec un serveur web, demande les données de la page et les affiche sur votre écran.
Une histoire de la vie réelle
Imaginez que vous cherchez une recette de gâteau. Vous ouvrez votre navigateur, tapez l'adresse d'un site de cuisine et en quelques secondes, vous avez accès à des centaines de recettes.
Personnaliser votre expérience de navigation
Les navigateurs permettent d'ajouter des extensions, de changer le thème et de gérer les paramètres de confidentialité pour une expérience personnalisée.
La sécurité sur Internet
Les navigateurs modernes incluent des fonctionnalités de sécurité pour vous protéger contre les logiciels malveillants et les tentatives de phishing.
Exercices pratiques
Essayez d'installer une extension, de changer le thème de votre navigateur ou de vérifier les paramètres de sécurité pour mieux comprendre comment ils fonctionnent.
Les navigateurs mobiles
Sur mobile, les navigateurs sont optimisés pour les petits écrans et les connexions de données mobiles, offrant une expérience différente mais tout aussi riche.
Les problèmes courants et leurs solutions
Si un site ne se charge pas, essayez de vider le cache de votre navigateur ou de vérifier votre connexion Internet.
Comprendre les navigateurs est essentiel pour naviguer efficacement sur le web. Prenez le temps d'explorer et de personnaliser le vôtre pour une meilleure expérience en ligne. Besoin d'une formation sur Initiation en Informatique? Inscrivez-vous sur Créer un compte étudiant CNDCI et commencez dès aujourd'hui

Partagez cet article
- Cybersécurité (1)
- Word2.0 (6)
Articles récents
Comment naviguer sur Internet en toute sécurité ?
Cybersécurité pour Débutants
Apprendre à coder : Par où commencer ?
Les bases de l’informatique : Un guide pour débutants
Les propriétés CSS les plus utilisées
10 Astuces pour Maîtriser Microsoft Word | Blog CNDCI
Les raccourcis clavier essentiels pour gagner du temps sous Windows, Mac, Excel, Word, Powerpoint
La messagerie électronique pour les novices : Ce que vous devez savoir
Formations disponibles.
- JAVA : Conception et Programmation
- ACCESS : du Débutant au niveau Avancé
- POWERPOINT : du Débutant au niveau Professionnel
- Intiation en Informatique et WORD du débutant au niveau avancé
- PROGRAMMATION WEB avec HTML, CSS, PHP, Bootstrap et MySQL
- Python : Conception, Programmation et Analyse des données
- C# : Conception et Programmation
- VB.NET : Conception et Programmation
- EXCEL : du Débutant au niveau Avancé
- PROGRAMMATION MOBILE : Conception et Programmation
- PHOTOSHOP : du débutant au niveau Avancé
- EXCEL PRO : Gestion et fonctions avancées
- PROGRAMMATION WEB PRO : Gestion de vente, stock, facturation et rapport
- Réseau Informatique
- ANGLAIS : du débutant au niveau avancé
- Pratique du Marketing Digital
- Initiation en information et Word 2.0 du débutant au niveau avancé

A new AI era begins
Introducing the fastest, most intelligent Windows PCs ever. Windows 11 Copilot+ PCs give you lightning speed, unique Copilot+ PC experiences, and more at a price that outperforms.
The best Windows yet
When there’s a lot to do, let Windows 11 help you get it done.

Meet Windows 11
Learn how to use the new features of Windows 11 and see what makes it the best Windows yet.

Upgrade your experience
Learn how to get Windows 11 on your current PC 4 , or purchase a new PC that can run Windows 11.

Need help transferring files, resetting a password, or upgrading to Windows 11? Explore the Windows support page for helpful articles on all things Windows. Have a specific issue you’re troubleshooting? Ask your question in the Microsoft Community.

Meet Copilot in Windows
Find the information and ideas you need to power your ingenuity. Copilot in Windows 6 is an AI feature that allows you to get answers fast and ask follow-up questions, get AI-generated graphics based on your ideas, and kickstart your creativity while you work. Get to know Copilot in Windows, your new intelligent assistant.
Sync your PC & phone
Microsoft Phone Link makes it possible to make calls, reply to texts, and check your phone’s notifications from your PC 5 .
Find the right fit
Explore a selection of new PCs, or get help selecting the best computer for your unique needs.

Better together
Discover the Windows 11 experiences built to bring your favorite Microsoft tools to life.

Microsoft Store
The apps you need. The shows you love. Find them fast in the new Microsoft Store. 1 2

Microsoft Edge
Make the most of your time online with the browser built for Windows.

Microsoft 365
Maximize your productivity with easy-to-use Windows 11 multitasking tools built to work with the Microsoft apps you use every day. 3
Looking for more?
Get help with your transition to Windows 11, and make the most of your Windows experience.

Get Microsoft news and updates
Subscribe to our newsletter to get the latest news, feature updates, how-to tips, deals and more for Windows and other Microsoft products.
Become an insider
Register with the Windows Insider Program and start engaging with engineers to help shape the future of Windows.
- 1 Screens simulated. Features and app availability may vary by region.
- 2 Some apps shown coming later. Certain apps only available through Microsoft Store app in Windows 11.
- 3 Microsoft 365 subscription sold separately.
- 4 Windows 11 upgrade is available for eligible PCs that meet minimum device specifications . Upgrade timing may vary by device. Internet service fees may apply. Features and app availability may vary by region. Certain features require specific hardware (see Windows 11 specifications ).
- 5 Phone Link experience comes preinstalled on your PC with Windows 10 (running Windows 10, May 2019 Update at the least) or Windows 11. To experience the full functionality, Android phones must be running Android 7.0 or later. Phone Link for iOS requires iPhone with iOS 14 or higher, Windows 11 device, Bluetooth connection and the latest version of the Phone Link app. Not available for iPad (iPadOS) or MacOS. Device compatibility may vary. Regional restrictions may apply.
- 6 Copilot in Windows (in preview) is available in select global markets and will roll out starting in summer 2024 to Windows 11 PCs in the European Economic Area. Copilot in Windows 10 functionality is limited and has specific system requirements . Learn More .
Follow Microsoft Windows

Share this page
Connectez-vous ou créez un compte
Pour pouvoir enregistrer un article, un compte est nécessaire.
- Colmar Guebwiller
- Haguenau - Wissembourg
- Molsheim - Obernai
- Mulhouse - Thann
- Saverne - Sarre-Union
- Sélestat - Erstein
- Sundgau - Trois-Frontières
- Libra Memoria
- Newsletters
- La Boutique
- Mon Séjour en Montagne

mer. 19/06/2024
- Activer JavaScript dans votre navigateur pour accéder à l'inscription sur notre site
Si vous voyez ce champ, ne le remplissez pas
Les Dernières Nouvelles d'Alsace, en tant que responsable de traitement, recueille dans ce formulaire des informations qui sont enregistrées dans un fichier informatisé par son Service Relations Clients, la finalité étant d’assurer la création et la gestion de votre compte, ainsi que des abonnements et autres services souscrits. Si vous y avez consenti, ces données peuvent également être utilisées pour l’envoi de newsletters et/ou d’offres promotionnelles par Les Dernières Nouvelles d'Alsace, les sociétés qui lui sont affiliées et/ou ses partenaires commerciaux. Vous pouvez exercer en permanence vos droits d’accès, rectification, effacement, limitation, opposition, retirer votre consentement et/ou pour toute question relative au traitement de vos données à caractère personnel en contactant [email protected] ou consulter les liens suivants : Protection des données , CGU du site et Contact . Le Délégué à la Protection des Données personnelles ( [email protected] ) est en copie de toute demande relative à vos informations personnelles.
- Dans un article
- Dans ma ville
- Wissembourg
- Saint-Louis

Législatives
- Dans nos départements
Législatives Qu'est-ce que le droit du sol, que souhaite restreindre Jordan Bardella ?
Contrairement aux idées reçues, aujourd'hui, l'acquisition de la nationalité par « droit du sol » n'est pas automatique pour les enfants de parents étrangers, mais soumise à certaines conditions.

Cette réforme « fait partie des urgences pointées par Jordan Bardella », selon le service communication du leader du RN. Photo Sipa/Vincent Loison
Le Rassemblement national promet, en cas d'arrivée au pouvoir après les législatives, de restreindre les conditions d'accès à la nationalité française par le « droit du sol », un principe fondamental ancien, maintes fois attaqué.
Aujourd'hui, l'acquisition de la nationalité par « droit du sol » n'est pas automatique pour les enfants de parents étrangers, mais soumise à certaines conditions.
Quelles conditions d'obtention ?
Il ne suffit pas de naître en France pour l'obtenir. Elle est en effet attribuée à la majorité lorsqu'un enfant est né en France de deux parents étrangers à condition de résider en France à ses 18 ans et pendant une période continue ou discontinue d'au moins cinq ans depuis l’âge de 11 ans.
L'enfant peut cependant obtenir la nationalité avant sa majorité sur demande de ses parents (entre 13 et 16 ans) ou sur demande personnelle (entre 16 et 18 ans).
Quid de la nationalité française ?
La nationalité française est attribuée de façon systématique uniquement par « droit du sang » pour tout enfant né en France ou à l'étranger dont au moins un des parents est Français. C'est également le cas par « double droit du sol », c'est-à-dire pour tout enfant né en France dont au moins un des parents est également né en France. Ce sont les seuls cas d'attribution automatique dès la naissance.
Que propose le RN ?
Le Rassemblement national (RN) propose de restreindre le droit du sol afin que « seul un enfant né d’au moins un parent français ait accès automatiquement à la nationalité française », a précisé le service communication du parti d'extrême droite. Ainsi, « tout enfant né de deux parents étrangers sur le sol français ne pourra accéder à la nationalité qu’après une demande à partir de ses 18 ans », a-t-il ajouté.
Cette démarche « fera l’objet d’un examen détaillé par l'administration et comportera certains critères basés notamment sur le casier judiciaire », ajoute la même source. C'est déjà le cas, en cas de condamnation à une peine égale ou supérieure à six mois d'emprisonnement.
Cette réforme, qui prendrait la forme d'« une loi simple » votée au parlement, « fait partie des urgences pointées par Jordan Bardella », explique encore le service communication du leader du RN.
15 députés à élire : la carte des candidatures en Alsace
Le rn retire son soutien à l'un de ses candidats après un tweet antisémite, législatives : l'équipe de campagne d'un député lfi ciblée par des insultes racistes.
Un droit ancien et contesté
Apparu dès le Moyen-Age, le droit du sol a été consacré par la Code civil depuis 1804. Il a été aboli sous le régime de Vichy et rétabli par ordonnance en octobre 1945.
Dans les années 1980, dans le cadre des débats sur l'immigration, la question de l’automaticité du droit du sol, héritée de 1889, est déjà remise en cause par l'extrême droite. Entre 1993 et 1998, la loi dite Pasqua prévoit que, pour bénéficier du droit du sol et devenir français, un enfant né en France de parents étrangers doit en manifester la volonté entre 16 et 21 ans.
Mi-février, le ministre de l'Intérieur Gérald Darmanin avait annoncé son intention de supprimer le droit du sol à Mayotte, alors que l'archipel était bloqué par des collectifs citoyens protestant contre l'immigration illégale et la délinquance. Prévue en mai, la présentation en Conseil des ministres du projet de loi constitutionnelle prévoyant cette suppression avait été décalée en juillet.
- Élections législatives
- France - Monde
- Rassemblement national
Javascript est desactivé dans votre navigateur.
République Française
Entreprendre .Service-Public.fr
Le site officiel d'information administrative pour les entreprises
- Accéder au site pour les particuliers
Sélectionnez une commune dans la liste des suggestions
Une erreur est survenue pendant la recherche, merci de réessayer.
Partager la page
Votre abonnement a bien été pris en compte
Vous serez alerté(e) par email dès que la page « Projet de création d'entreprise : comment faire un business plan » sera mise à jour significativement.
Vous pouvez à tout moment supprimer votre abonnement dans votre compte service-public.fr .
Votre abonnement n’a pas pu être pris en compte.
Vous devez vous connecter à votre espace personnel afin de vous abonner à la mise à jour de cette page.
Être alerté(e) en cas de changement
Ce sujet vous intéresse ? Connectez-vous à votre compte et recevez une alerte par email dès que l’information de la page « Projet de création d'entreprise : comment faire un business plan » est mise à jour.
Pour vous abonner aux mises à jour des pages service-public.fr, vous devez activer votre espace personnel .
Vous serez alerté(e) par courriel dès que la page « Projet de création d'entreprise : comment faire un business plan » sera mise à jour significativement.
ACTIVER MON ESPACE PERSONNEL
Projet de création d'entreprise : comment faire un business plan
Vérifié le 26 septembre 2023 - Direction de l'information légale et administrative (Premier ministre)
Personne qui investit de l'argent dans une entreprise innovante à fort potentiel. Elle est expérimentée et apporte des contacts, conseils. Elle espère faire une plus-value.
Autres cas ?
Reprise d’entreprise : bâtir un business plan
Vous avez un projet de création d'entreprise ? Le business plan (ou plan d'affaires) est un document écrit qui présente en détail votre projet de création entreprise. Le business plan sera l'outil pour convaincre les banques et les investisseurs . Nous vous expliquons comment faire un business plan étape par étape .
La démarche par étapes
1 Ce qu'il faut savoir avant de faire votre business plan
À quoi sert le business plan , un guide et un outil vendeur.
Le business plan doit être vendeur , rassurant , c'est-à-dire réaliste.
Vous devez le construire à partir du terrain , de vos recherches et de votre analyse .
Il doit prouver que votre projet de création d'entreprise est sérieux .
Le business plan doit être à la fois synthétique et très précis avec des prévisions chiffrées .
Un outil adapté à chaque investisseur
Votre business plan est l' outil pour convaincre les investisseurs et tous ceux qui soutiendront votre projet.
Il s'adresse donc aux investisseurs suivants :
- Collectivités locales
- Business angels : titleContent
- Futurs associés
- Tous ceux auprès de qui vous cherchez des fonds
À savoir
En fonction de l'investisseur à qui vous vous adressez, vous mettez certaines informations en avant.
Vous devez donc faire plusieurs versions de votre business plan selon chaque destinataire .
Les étapes du business plan
Le business plan est un document qui se construit en 5 étapes :
- Introduction ou pitch de présentation
- Présentation de votre produit (ou service)
- Présentation de votre business model (appelé aussi stratégie commerciale )
- Votre étude de marché (synthèse)
- Votre prévisionnel financier (synthèse)
2 Préparer un pitch de présentation
À quoi sert un pitch de présentation .
Le pitch de présentation du business plan est aussi appelé executive summary .
Il s'agit de la présentation de votre projet de création d'entreprise.
Il doit être condensé .
Son objectif est de convaincre un interlocuteur.
Vous devez convaincre dans un temps court .
L' objectif de cette synthèse est de prouver :
- Votre capacité à créer et diriger une entreprise
- Votre adéquation avec le projet
- Votre sérieuse préparation du projet
- Si vous êtes plusieurs associés, votre cohésion d'équipe
Il est conseillé de rédiger plusieurs versions de cette présentation selon chaque investisseur à convaincre.
- Pour convaincre un investisseur public, vous insisterez davantage sur le service que vous rendez à la société.
- Pour convaincre un business angel : titleContent , vous insisterez sur le caractère innovant de votre offre.
Ces informations doivent permettre de comprendre quelles sont vos idées , vos valeurs , ce qui vous motive , donc le sens de votre projet .
Si vous êtes plusieurs à porter le projet de création, on doit sentir la cohésion de l' équipe et la complémentarité des membres.
Cette présentation doit prouver votre capacité à créer et diriger une entreprise sur le court et le long terme .
Quel est le contenu du pitch ?
Cette présentation doit permettre de répondre aux questions suivantes :
- Qui êtes-vous et quels sont les membres de votre équipe (collaborateurs, associés) ?
- Quel est votre projet ? Il s'agit du nom de votre entreprise, sa forme juridique, sa domiciliation, la nature de l'activité, l'histoire du projet.
- Quelle est votre cible ? Il s'agit de montrer que vous avez identifié vos futurs clients.
- Quel est l' environnement ? Il s'agit de montrer que vous avez identifié la concurrence, les contraintes, les risques, les tendances de votre marché, etc.
- Quelles sont vos ambitions de développement ? Il s'agit de montrer que vous avez une vision du projet à court , moyen et long terme .
La présentation du business plan est en partie un résumé de l' étude de marché .
3 Expliquer quel est votre produit ou service
Vous décrivez ce que vous allez vendre .
Cette description doit être précise, concise, claire.
Il faut éviter d'employer des termes trop techniques.
Vous devez être compris par des personnes qui ne connaissent rien à votre domaine d'activité.
Vous pouvez faire des schémas, dessins, etc. pour accompagner cette description du produit.
4 Définir la stratégie marketing ou business model
Qu'est-ce que le business model d'une entreprise .
Vous devez présenter comment vous allez vendre votre produit ou votre service.
Le business model s'appelle de différentes façons : une stratégie marketing , une stratégie commerciale, un " mix-marketing " ou encore un modèle économique .
Le business model de votre entreprise doit répondre aux questions suivantes :
- De quelle façon allez-vous faire la promotion et la publicité de votre entreprise, de votre produit ou service ?
- Quels seront vos tarifs ?
- Quels seront vos fournisseurs ?
- Par qui sera fabriqué votre produit ou service ?
- Quels seront vos canaux de distribution , où sera vendu votre produit ou service (internet, réseaux professionnels, boutiques etc.) ?
- Quelle sera la relation avec vos clients, comment les fidéliser ?
- Où seront stockés vos produits ?
- Quelles seront les pistes de développement de votre activité (internet, national, international, etc.) ?
Avez-vous analysé les contraintes ?
Il s'agit de prévoir ce qui peut freiner votre activité .
Vous devez identifier ce qui peut faire grimper vos coûts : stockage, production, distribution, communication.
- Le cours fluctuant des matières premières influe-t-il sur votre production ?
- Les fournisseurs du secteur ont-ils un monopole ?
- La demande vis-à-vis de votre produit est-elle saisonnière ?
Vous devez prouver que vous avez réfléchi aux solutions suivantes :
- Comment dépasser les contraintes
- Comment faire face à des pertes de bénéfices, à une hausse de vos charges, à de nouveaux concurrents, etc.
5 Rédiger la synthèse de votre étude de marché
L'objectif de l'étude de marché et de sa synthèse est d'expliquer :
- Quels sont vos futurs clients ?
- Quelle plus-value votre produit apporte-t-il sur le marché ?
- Dans quel environnement s'insère votre future activité ?
Nous vous expliquons en détail comment faire une étude de marché dans notre fiche sur l'étude de marché .
6 Rédiger la synthèse du prévisionnel financier
L'objectif d'un prévisionnel financier est de montrer que votre entreprise sera rentable .
Il est aussi appelé plan de financements ou budget prévisionnel .
Le prévisionnel financier (ou budget prévisionnel) fait partie de votre étude de marché. Il s'agit de la dernière partie de votre étude de marché.
Vous devez construire ce budget sur les 3 années à venir .
Vous devez chiffrer :
- Vos charges, les dépenses nécessaires
- Vos recettes (chiffre d'affaires)
- Vos besoins de financements
- Les fluctuations de votre activité et celles du marché
Il se déroule en 4 parties :
- Compte de résultat
- Plan de financement
- Budget ou plan de trésorerie
Ces 4 parties correspondent à 4 tableaux chiffrés.
Nous vous expliquons en détail les 4 étapes d'un budget prévisionnel dans notre fiche sur l'étude de marché .
Services en ligne et formulaires
Trouver un accompagnement adapté à la création de votre entreprise
Service en ligne
Lister vos concurrents
Outil de recherche
Insee : portrait économique d'un territoire
Projet de création d’entreprise : comment faire une étude de marché
Recherche de financements pour créer ou reprendre une entreprise
Réseau entreprendre : des entrepreneurs vous aident à créer
Réseau entreprendre
Cette page vous a-t-elle été utile ?
- 1 Pas du tout Cette page ne pas m'a pas du tout été utile
- 2 Un peu Cette page m'a été un peu utile
- 3 Moyen Cette page m'a été moyennement utile
- 4 Beaucoup Cette page m'a été très utile
- 5 Parfait ! Cette page m'a été parfaitement utile
Pas du tout
L’équipe entreprendre.Service-Public.fr vous remercie
Je vais sur la page d’accueil
Vous avez noté 1 sur 5 : Pas du tout
Vous avez noté 2 sur 5 : Un peu
Vous avez noté 3 sur 5 : Moyen
Vous avez noté 4 sur 5 : Beaucoup
Vous avez noté 5 sur 5 : Parfait !
Je fais une remarque sur cette page
L’équipe entreprendre.Service-Public.fr vous remercie pour vos remarques utiles à l'amélioration du site.
Pour des raisons de sécurité, nous ne pouvons valider ce formulaire suite à une trop longue période d’inactivité. Merci de recharger la page si vous souhaitez le soumettre à nouveau.
Une erreur technique s'est produite. Merci de réessayer ultérieurement.
Vos remarques pour améliorer la page
La page est-elle facile à comprendre , l’information a-t-elle été utile .
Javascript est desactivé dans votre navigateur.
Savez-vous que votre navigateur est obsolète ?
Pour naviguer de la manière la plus satisfaisante sur le Web, nous vous recommandons de procéder à une mise à jour de votre navigateur . Vous pouvez aussi essayer d’autres navigateurs web populaires .
- Aller au contenu
- Aller au menu
- Aller à la recherche
- Informations de mises à jour
- Gestion des cookies
- Nous contacter
- Activer l’aide sur la page
Effectuer une recherche dans :
- --> --> --> Partager via Twitter --> --> --> --> Partager via Facebook --> --> --> --> Partager par e-mail --> --> --> --> Ajouter en Favoris --> --> --> --> Télécharger au format PDF --> -->