
Speech recognition, also known as automatic speech recognition (ASR), computer speech recognition or speech-to-text, is a capability that enables a program to process human speech into a written format.
While speech recognition is commonly confused with voice recognition, speech recognition focuses on the translation of speech from a verbal format to a text one whereas voice recognition just seeks to identify an individual user’s voice.
IBM has had a prominent role within speech recognition since its inception, releasing of “Shoebox” in 1962. This machine had the ability to recognize 16 different words, advancing the initial work from Bell Labs from the 1950s. However, IBM didn’t stop there, but continued to innovate over the years, launching VoiceType Simply Speaking application in 1996. This speech recognition software had a 42,000-word vocabulary, supported English and Spanish, and included a spelling dictionary of 100,000 words.
While speech technology had a limited vocabulary in the early days, it is utilized in a wide number of industries today, such as automotive, technology, and healthcare. Its adoption has only continued to accelerate in recent years due to advancements in deep learning and big data. Research (link resides outside ibm.com) shows that this market is expected to be worth USD 24.9 billion by 2025.
Explore the free O'Reilly ebook to learn how to get started with Presto, the open source SQL engine for data analytics.
Register for the guide on foundation models
Many speech recognition applications and devices are available, but the more advanced solutions use AI and machine learning . They integrate grammar, syntax, structure, and composition of audio and voice signals to understand and process human speech. Ideally, they learn as they go — evolving responses with each interaction.
The best kind of systems also allow organizations to customize and adapt the technology to their specific requirements — everything from language and nuances of speech to brand recognition. For example:
- Language weighting: Improve precision by weighting specific words that are spoken frequently (such as product names or industry jargon), beyond terms already in the base vocabulary.
- Speaker labeling: Output a transcription that cites or tags each speaker’s contributions to a multi-participant conversation.
- Acoustics training: Attend to the acoustical side of the business. Train the system to adapt to an acoustic environment (like the ambient noise in a call center) and speaker styles (like voice pitch, volume and pace).
- Profanity filtering: Use filters to identify certain words or phrases and sanitize speech output.
Meanwhile, speech recognition continues to advance. Companies, like IBM, are making inroads in several areas, the better to improve human and machine interaction.
The vagaries of human speech have made development challenging. It’s considered to be one of the most complex areas of computer science – involving linguistics, mathematics and statistics. Speech recognizers are made up of a few components, such as the speech input, feature extraction, feature vectors, a decoder, and a word output. The decoder leverages acoustic models, a pronunciation dictionary, and language models to determine the appropriate output.
Speech recognition technology is evaluated on its accuracy rate, i.e. word error rate (WER), and speed. A number of factors can impact word error rate, such as pronunciation, accent, pitch, volume, and background noise. Reaching human parity – meaning an error rate on par with that of two humans speaking – has long been the goal of speech recognition systems. Research from Lippmann (link resides outside ibm.com) estimates the word error rate to be around 4 percent, but it’s been difficult to replicate the results from this paper.
Various algorithms and computation techniques are used to recognize speech into text and improve the accuracy of transcription. Below are brief explanations of some of the most commonly used methods:
- Natural language processing (NLP): While NLP isn’t necessarily a specific algorithm used in speech recognition, it is the area of artificial intelligence which focuses on the interaction between humans and machines through language through speech and text. Many mobile devices incorporate speech recognition into their systems to conduct voice search—e.g. Siri—or provide more accessibility around texting.
- Hidden markov models (HMM): Hidden Markov Models build on the Markov chain model, which stipulates that the probability of a given state hinges on the current state, not its prior states. While a Markov chain model is useful for observable events, such as text inputs, hidden markov models allow us to incorporate hidden events, such as part-of-speech tags, into a probabilistic model. They are utilized as sequence models within speech recognition, assigning labels to each unit—i.e. words, syllables, sentences, etc.—in the sequence. These labels create a mapping with the provided input, allowing it to determine the most appropriate label sequence.
- N-grams: This is the simplest type of language model (LM), which assigns probabilities to sentences or phrases. An N-gram is sequence of N-words. For example, “order the pizza” is a trigram or 3-gram and “please order the pizza” is a 4-gram. Grammar and the probability of certain word sequences are used to improve recognition and accuracy.
- Neural networks: Primarily leveraged for deep learning algorithms, neural networks process training data by mimicking the interconnectivity of the human brain through layers of nodes. Each node is made up of inputs, weights, a bias (or threshold) and an output. If that output value exceeds a given threshold, it “fires” or activates the node, passing data to the next layer in the network. Neural networks learn this mapping function through supervised learning, adjusting based on the loss function through the process of gradient descent. While neural networks tend to be more accurate and can accept more data, this comes at a performance efficiency cost as they tend to be slower to train compared to traditional language models.
- Speaker Diarization (SD): Speaker diarization algorithms identify and segment speech by speaker identity. This helps programs better distinguish individuals in a conversation and is frequently applied at call centers distinguishing customers and sales agents.
A wide number of industries are utilizing different applications of speech technology today, helping businesses and consumers save time and even lives. Some examples include:
Automotive: Speech recognizers improves driver safety by enabling voice-activated navigation systems and search capabilities in car radios.
Technology: Virtual agents are increasingly becoming integrated within our daily lives, particularly on our mobile devices. We use voice commands to access them through our smartphones, such as through Google Assistant or Apple’s Siri, for tasks, such as voice search, or through our speakers, via Amazon’s Alexa or Microsoft’s Cortana, to play music. They’ll only continue to integrate into the everyday products that we use, fueling the “Internet of Things” movement.
Healthcare: Doctors and nurses leverage dictation applications to capture and log patient diagnoses and treatment notes.
Sales: Speech recognition technology has a couple of applications in sales. It can help a call center transcribe thousands of phone calls between customers and agents to identify common call patterns and issues. AI chatbots can also talk to people via a webpage, answering common queries and solving basic requests without needing to wait for a contact center agent to be available. It both instances speech recognition systems help reduce time to resolution for consumer issues.
Security: As technology integrates into our daily lives, security protocols are an increasing priority. Voice-based authentication adds a viable level of security.
Convert speech into text using AI-powered speech recognition and transcription.
Convert text into natural-sounding speech in a variety of languages and voices.
AI-powered hybrid cloud software.
Enable speech transcription in multiple languages for a variety of use cases, including but not limited to customer self-service, agent assistance and speech analytics.
Learn how to keep up, rethink how to use technologies like the cloud, AI and automation to accelerate innovation, and meet the evolving customer expectations.
IBM watsonx Assistant helps organizations provide better customer experiences with an AI chatbot that understands the language of the business, connects to existing customer care systems, and deploys anywhere with enterprise security and scalability. watsonx Assistant automates repetitive tasks and uses machine learning to resolve customer support issues quickly and efficiently.
Blog - Use Cases
May 17, 2023 | Read time 6 min

7 Real-World Examples of Voice Recognition Technology
Speechmatics’ Autonomous Voice Recognition shows how powerful speech-to-text can be. Speech recognition’s versatility makes it a vital tool in the 21st century.

Speechmatics Team
Speech recognition technology is the hub of millions of homes worldwide – devices that listen to your voice and carry out a subsequent command. You may think that technology doesn’t extend much further, but you might want to grab a ladder – this hole is a deep one.
The technology within speech recognition software goes beyond what most of us know. Speech-to-text, such as Speechmatics’ Autonomous Speech Recognition (ASR), stretches its influence across society. This article will dive into seven examples of speech recognition and areas where speech-to-text technology makes a valuable difference.
1) Doctor’s Virtual Assistant
Despite having vastly different healthcare systems, both the US and the UK suffer from extended wait times . It’s clear that hospitals around the world would benefit from anything that saves them time.
If doctors have easy access to speech-to-text technology, they shorten the average appointment by converting their notes from speech to text instead of transcribing by hand. The less time a doctor spends typing their notes, the more patients they can see during a day.
Furthermore, effective speech recognition systems such as our world-leading ASR cuts out the middleman more frequently. Instead of waiting for a human operative, many medical institutions use speech recognition to help you identify your symptoms and whether you need a doctor.
There is, however, a concern with the information speech-to-text software would ingest – it would likely need to be validated by recognized medical institutions from a data security perspective.
Despite this, speech-to-text in healthcare seems like a no brainer. When you save time, you save lives.

2) Autonomous Bank Deposits
According to a survey from PwC, 32% of customers will ditch a brand they love after a singular negative experience. Good customer service is vital to keeping customers and enticing new ones.
Banks often struggle with customer service, as customers get bounced from employee to manager, explaining the same details repeatedly. This is where speech-to-text software comes into play. As we move further into the 2020s, banks are adapting their services to the technology available.
There are numerous instances of major banks using speech-to-text technology. The Royal Bank of Canada, for example, lets customers pay bills using voice commands. The USAA offers members access to information about account balances, transactions, and spending patterns through Amazon’s Alexa. Banks such as U.S. Bank Smart Assistant provide tips and insights to help customers with their money. If banks want to reduce the need for human employees where possible.

3) Personalizing Adverts
“My phone keeps listening to me!” seems to pop up in modern conversation more and more these days.
What may seem like spyware is in fact speech-to-text technology collecting your data. Your devices listen for accents, speech patterns, and specific vocabulary used to find a consumer’s age, location, and other information. The software then collates that data into keywords which are then fed to you in the form of personalized ads.
While tracking your search history is vital for marketers, speech-to-text offers a more thorough behavior assessment. Text is often quite limited – you say what you need to say in as little words as possible. Speaking is more fluid and offers a better glimpse into your behavior, so by capturing that, marketers can tailor ads more to your needs.

4) Making Our Home Lives Easier
According to Statista, over 5 billion people will use voice-activated search in 2021, with predicted numbers reaching 6.4 billion in 2022. In addition, 30% of voice-assistant customers say they bought the software to control their homes.
In essence, people use speech recognition technology to make their lives easier. It's 2022, why should we trek over to the light switch to turn it on?
The pandemic pushed speech-to-text technology to greater heights, as people ordered shopping through Alexa, Siri, and co more often. Life is becoming as automated as possible.

5) Handsfree Playlist Shuffling
Take a seat in most modern cars and you’ll see ‘Apple CarPlay’ appear on the center console. This allows you to answer and make phone calls, change songs, send messages, and get directions without taking your hands off the steering wheel.
Not only do these features dramatically increase road safety, but they also make the driving experience more comfortable. You don’t need to queue fifty songs in a row and print off directions to your destination. Instead, speech recognition hears your request to send a text message, transcribes, and sends.
None of that would be possible without technology like speech-to-text.

6) Productivity Manager
COVID-19 changed the workplace forever. Offices have adapted since 2020, with many adopting a hybrid approach to working. Speechmatics is no different. Many of our employees work remotely, some work in our head office, and others started using our newly rented WeWork office spaces.
Organizations need to stay modern, or risk being left behind. Speech-to-text technology helps maintain productivity and efficiency no matter where employees are based. Microsoft Teams and Zoom are now office essentials. Emails and documents are transcribed without typing, saving time and hassle.
Meeting minutes are recorded and transcribed so absent workers can catch up. All of this allows for a more forgiving environment where employees can claim back some agency.

7) Giving Air Force Pilots Less to Think About
Fighter planes are the technological pinnacle of most nations’ weapons arsenal. The RAF’s EuroFighter Typhoon, for example, is one of the most feared jets on the planet. A large part of its operating system is done using speech recognition software . The pilot creates a template used for an array of cockpit functions, lightening their workload.
Step back onto the ground and speech-to-text technology is still just as prevalent. Speech recognition helps soldiers access vital mission information, consult maps, and transmit messages in the heat of battle.
Step back even further into government and speech recognition is everywhere. Departments often use it in place of a human operative, saving labor and money.

Speech Recognition Is Everywhere
In this day and age, you’ll be hard-pressed to find an area of your life not influenced by speech recognition technology. The scale is colossal, as while you tell Apple CarPlay to reply to your partner’s message, a doctor is shifting through their transcribed notes, and a fighter pilot is telling their plane to lock onto a target.
Of course, there are still many challenges – the technology is far from perfect – but the benefits are there for all to see. We at Speechmatics will continue to ensure the world reaps ASR’s potential rewards.
Ready to Try Speechmatics?
Try for free and we'll guide you through the implementation of our API. We pride ourselves on offering the best support for your business needs. If you have any questions, just ask.
Related Articles
Mar 7, 2023
Introducing Ursa from Speechmatics
Nov 17, 2023
Transforming the spoken word into written chapters
Rohan Sarin
Product Manager (ML)
Mar 9, 2023
Achieving Accessibility Through Incredible Accuracy with Ursa

Benedetta Cevoli
Senior Data Scientist
Speech Recognition: Everything You Need to Know in 2024
Speech recognition, also known as automatic speech recognition (ASR) , enables seamless communication between humans and machines. This technology empowers organizations to transform human speech into written text. Speech recognition technology can revolutionize many business applications , including customer service, healthcare, finance and sales.
In this comprehensive guide, we will explain speech recognition, exploring how it works, the algorithms involved, and the use cases of various industries.
If you require training data for your speech recognition system, here is a guide to finding the right speech data collection services.
What is speech recognition?
Speech recognition, also known as automatic speech recognition (ASR), speech-to-text (STT), and computer speech recognition, is a technology that enables a computer to recognize and convert spoken language into text.
Speech recognition technology uses AI and machine learning models to accurately identify and transcribe different accents, dialects, and speech patterns.
What are the features of speech recognition systems?
Speech recognition systems have several components that work together to understand and process human speech. Key features of effective speech recognition are:
- Audio preprocessing: After you have obtained the raw audio signal from an input device, you need to preprocess it to improve the quality of the speech input The main goal of audio preprocessing is to capture relevant speech data by removing any unwanted artifacts and reducing noise.
- Feature extraction: This stage converts the preprocessed audio signal into a more informative representation. This makes raw audio data more manageable for machine learning models in speech recognition systems.
- Language model weighting: Language weighting gives more weight to certain words and phrases, such as product references, in audio and voice signals. This makes those keywords more likely to be recognized in a subsequent speech by speech recognition systems.
- Acoustic modeling : It enables speech recognizers to capture and distinguish phonetic units within a speech signal. Acoustic models are trained on large datasets containing speech samples from a diverse set of speakers with different accents, speaking styles, and backgrounds.
- Speaker labeling: It enables speech recognition applications to determine the identities of multiple speakers in an audio recording. It assigns unique labels to each speaker in an audio recording, allowing the identification of which speaker was speaking at any given time.
- Profanity filtering: The process of removing offensive, inappropriate, or explicit words or phrases from audio data.
What are the different speech recognition algorithms?
Speech recognition uses various algorithms and computation techniques to convert spoken language into written language. The following are some of the most commonly used speech recognition methods:
- Hidden Markov Models (HMMs): Hidden Markov model is a statistical Markov model commonly used in traditional speech recognition systems. HMMs capture the relationship between the acoustic features and model the temporal dynamics of speech signals.
- Estimate the probability of word sequences in the recognized text
- Convert colloquial expressions and abbreviations in a spoken language into a standard written form
- Map phonetic units obtained from acoustic models to their corresponding words in the target language.
- Speaker Diarization (SD): Speaker diarization, or speaker labeling, is the process of identifying and attributing speech segments to their respective speakers (Figure 1). It allows for speaker-specific voice recognition and the identification of individuals in a conversation.
Figure 1: A flowchart illustrating the speaker diarization process

- Dynamic Time Warping (DTW): Speech recognition algorithms use Dynamic Time Warping (DTW) algorithm to find an optimal alignment between two sequences (Figure 2).
Figure 2: A speech recognizer using dynamic time warping to determine the optimal distance between elements

5. Deep neural networks: Neural networks process and transform input data by simulating the non-linear frequency perception of the human auditory system.
6. Connectionist Temporal Classification (CTC): It is a training objective introduced by Alex Graves in 2006. CTC is especially useful for sequence labeling tasks and end-to-end speech recognition systems. It allows the neural network to discover the relationship between input frames and align input frames with output labels.
Speech recognition vs voice recognition
Speech recognition is commonly confused with voice recognition, yet, they refer to distinct concepts. Speech recognition converts spoken words into written text, focusing on identifying the words and sentences spoken by a user, regardless of the speaker’s identity.
On the other hand, voice recognition is concerned with recognizing or verifying a speaker’s voice, aiming to determine the identity of an unknown speaker rather than focusing on understanding the content of the speech.
What are the challenges of speech recognition with solutions?
While speech recognition technology offers many benefits, it still faces a number of challenges that need to be addressed. Some of the main limitations of speech recognition include:
Acoustic Challenges:
- Assume a speech recognition model has been primarily trained on American English accents. If a speaker with a strong Scottish accent uses the system, they may encounter difficulties due to pronunciation differences. For example, the word “water” is pronounced differently in both accents. If the system is not familiar with this pronunciation, it may struggle to recognize the word “water.”
Solution: Addressing these challenges is crucial to enhancing speech recognition applications’ accuracy. To overcome pronunciation variations, it is essential to expand the training data to include samples from speakers with diverse accents. This approach helps the system recognize and understand a broader range of speech patterns.
- For instance, you can use data augmentation techniques to reduce the impact of noise on audio data. Data augmentation helps train speech recognition models with noisy data to improve model accuracy in real-world environments.
Figure 3: Examples of a target sentence (“The clown had a funny face”) in the background noise of babble, car and rain.

Linguistic Challenges:
- Out-of-vocabulary words: Since the speech recognizers model has not been trained on OOV words, they may incorrectly recognize them as different or fail to transcribe them when encountering them.
Figure 4: An example of detecting OOV word
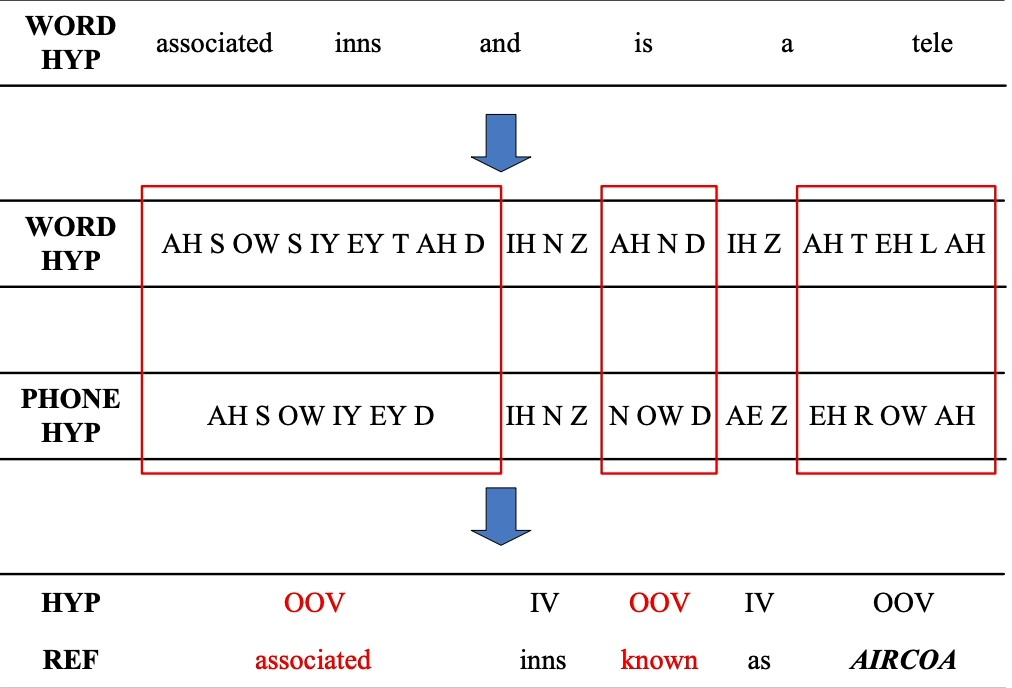
Solution: Word Error Rate (WER) is a common metric that is used to measure the accuracy of a speech recognition or machine translation system. The word error rate can be computed as:
Figure 5: Demonstrating how to calculate word error rate (WER)

- Homophones: Homophones are words that are pronounced identically but have different meanings, such as “to,” “too,” and “two”. Solution: Semantic analysis allows speech recognition programs to select the appropriate homophone based on its intended meaning in a given context. Addressing homophones improves the ability of the speech recognition process to understand and transcribe spoken words accurately.
Technical/System Challenges:
- Data privacy and security: Speech recognition systems involve processing and storing sensitive and personal information, such as financial information. An unauthorized party could use the captured information, leading to privacy breaches.
Solution: You can encrypt sensitive and personal audio information transmitted between the user’s device and the speech recognition software. Another technique for addressing data privacy and security in speech recognition systems is data masking. Data masking algorithms mask and replace sensitive speech data with structurally identical but acoustically different data.
Figure 6: An example of how data masking works

- Limited training data: Limited training data directly impacts the performance of speech recognition software. With insufficient training data, the speech recognition model may struggle to generalize different accents or recognize less common words.
Solution: To improve the quality and quantity of training data, you can expand the existing dataset using data augmentation and synthetic data generation technologies.
13 speech recognition use cases and applications
In this section, we will explain how speech recognition revolutionizes the communication landscape across industries and changes the way businesses interact with machines.
Customer Service and Support
- Interactive Voice Response (IVR) systems: Interactive voice response (IVR) is a technology that automates the process of routing callers to the appropriate department. It understands customer queries and routes calls to the relevant departments. This reduces the call volume for contact centers and minimizes wait times. IVR systems address simple customer questions without human intervention by employing pre-recorded messages or text-to-speech technology . Automatic Speech Recognition (ASR) allows IVR systems to comprehend and respond to customer inquiries and complaints in real time.
- Customer support automation and chatbots: According to a survey, 78% of consumers interacted with a chatbot in 2022, but 80% of respondents said using chatbots increased their frustration level.
- Sentiment analysis and call monitoring: Speech recognition technology converts spoken content from a call into text. After speech-to-text processing, natural language processing (NLP) techniques analyze the text and assign a sentiment score to the conversation, such as positive, negative, or neutral. By integrating speech recognition with sentiment analysis, organizations can address issues early on and gain valuable insights into customer preferences.
- Multilingual support: Speech recognition software can be trained in various languages to recognize and transcribe the language spoken by a user accurately. By integrating speech recognition technology into chatbots and Interactive Voice Response (IVR) systems, organizations can overcome language barriers and reach a global audience (Figure 7). Multilingual chatbots and IVR automatically detect the language spoken by a user and switch to the appropriate language model.
Figure 7: Showing how a multilingual chatbot recognizes words in another language
- Customer authentication with voice biometrics: Voice biometrics use speech recognition technologies to analyze a speaker’s voice and extract features such as accent and speed to verify their identity.
Sales and Marketing:
- Virtual sales assistants: Virtual sales assistants are AI-powered chatbots that assist customers with purchasing and communicate with them through voice interactions. Speech recognition allows virtual sales assistants to understand the intent behind spoken language and tailor their responses based on customer preferences.
- Transcription services : Speech recognition software records audio from sales calls and meetings and then converts the spoken words into written text using speech-to-text algorithms.
Automotive:
- Voice-activated controls: Voice-activated controls allow users to interact with devices and applications using voice commands. Drivers can operate features like climate control, phone calls, or navigation systems.
- Voice-assisted navigation: Voice-assisted navigation provides real-time voice-guided directions by utilizing the driver’s voice input for the destination. Drivers can request real-time traffic updates or search for nearby points of interest using voice commands without physical controls.
Healthcare:
- Recording the physician’s dictation
- Transcribing the audio recording into written text using speech recognition technology
- Editing the transcribed text for better accuracy and correcting errors as needed
- Formatting the document in accordance with legal and medical requirements.
- Virtual medical assistants: Virtual medical assistants (VMAs) use speech recognition, natural language processing, and machine learning algorithms to communicate with patients through voice or text. Speech recognition software allows VMAs to respond to voice commands, retrieve information from electronic health records (EHRs) and automate the medical transcription process.
- Electronic Health Records (EHR) integration: Healthcare professionals can use voice commands to navigate the EHR system , access patient data, and enter data into specific fields.
Technology:
- Virtual agents: Virtual agents utilize natural language processing (NLP) and speech recognition technologies to understand spoken language and convert it into text. Speech recognition enables virtual agents to process spoken language in real-time and respond promptly and accurately to user voice commands.
Further reading
- Top 5 Speech Recognition Data Collection Methods in 2023
- Top 11 Speech Recognition Applications in 2023
External Links
- 1. Databricks
- 2. PubMed Central
- 3. Qin, L. (2013). Learning Out-of-vocabulary Words in Automatic Speech Recognition . Carnegie Mellon University.
- 4. Wikipedia
Next to Read
10+ speech data collection services in 2024, top 5 speech recognition data collection methods in 2024, top 4 speech recognition challenges & solutions in 2024.
Your email address will not be published. All fields are required.
Related research

Top 11 Voice Recognition Applications in 2024
- > Artificial Intelligence
Automatic Speech Recognition: Types and Examples
- Yashoda Gandhi
- Mar 02, 2022
.jpg "Automatic Speech Recognition: Types and Examples")
Voice assistants such as Google Home, Amazon Echo, Siri, Cortana, and others have become increasingly popular in recent years. These are some of the most well-known examples of automatic speech recognition (ASR).
This type of app starts with a clip of spoken audio in a specific language and converts the words spoken into text. As a result, they're also called Speech-to-Text algorithms.
Apps like Siri and the others mentioned above, of course, go even further. They not only extract the text but also interpret and comprehend the semantic meaning of what was said, allowing them to respond to the user's commands with answers or actions.
Automatic Speech Recognition
ASR (Automated speech recognition) is a technology that allows users to enter data into information systems by speaking rather than punching numbers into a keypad. ASR is primarily used for providing information and forwarding phone calls.
In recent years, ASR has grown in popularity among large corporation customer service departments. It is also used by some government agencies and other organizations. Basic ASR systems recognize single-word entries such as yes-or-no responses and spoken numerals.
This enables users to navigate through automated menus without having to manually enter dozens of numerals with no margin for error. In a manual-entry situation, a customer may press the wrong key after entering 20 or 30 numerals at random intervals in the menu and abandon the call rather than call back and start over. This issue is virtually eliminated with ASR.
Natural Language Processing, or NLP for short, is at the heart of the most advanced version of currently available ASR technologies. Though this variant of ASR is still a long way from realizing its full potential, we're already seeing some impressive results in the form of intelligent smartphone interfaces like Apple's Siri and other systems used in business and advanced technology.
Even with a "accuracy" of 96 to 99 percent , these NLP programs can only achieve these kinds of results under ideal circumstances, such as when humans ask them simple yes or no questions with a small number of possible responses based on selected keywords.
Also Read | A Step Towards Artificial Super Intelligence (ASI)
How to carry out Automatic Speech Recognition ?
We’ve listed three significant ways for automatic speech recognition.
Old fashioned way
With ARPA funding in the 1970s, a team at Carnegie Melon University developed technology that could generate transcripts from context-specific speech, such as voice-controlled chess, chart-plotting for GIS and navigation, and document management in the office environment.
These types of products had one major flaw: they could only reliably convert speech to text for one person at a time. This is due to the fact that no two people speak in the same way. In fact, even if the same person speaks the same sentence twice, the sounds are mathematically different when recorded and measured!
Two mathematical realities for silicon brains, the same word to our human, meat-based brains! These ASR-based, personal transcription tools and products were revolutionary and had legitimate business uses, despite their inability to transcribe the utterances of multiple speakers.
Frankenstein approach
In the mid-2000s, companies like Nuance, Google, and Amazon realized that by making ASR work for multiple speakers and in noisy environments, they could improve on the 1970s approach.
Rather than having to train ASR to understand a single speaker, these Franken-ASRs were able to understand multiple speakers fairly well, which is an impressive feat given the acoustic and mathematical realities of spoken language. This is possible because these neural-network algorithms can "learn on their own" when given certain stimuli.
However, slapping a neural network on top of older machinery (remember, this is based on 1970s techniques) results in bulky, complex, and resource-hungry machines like Back-to-the-DeLorean Future's or my college bicycle: a franken-bike that worked when the tides and winds were just right, usually except when it didn't.
While clumsy, the mid-2000s hybrid approach to ASR works well enough for some applications; after all, Siri isn't supposed to answer any real-world data questions.
End to end Deep Learning
The most recent method, end-to-end deep learning ASR, makes use of neural networks and replaces the clumsy 1970s method. In essence, this new approach allows you to do something that was unthinkable even two years ago: train the ASR to recognize dialects, accents, and industry-specific word sets quickly and accurately.
It's a Mr. Fusion bicycle, complete with rusted bike frames and ill-fated auto brands. Several factors contribute to this, including breakthrough math from the 1980s, computing power/technology from the mid-2010s, big data, and the ability to innovate quickly.
It's crucial to be able to experiment with new architectures, technologies, and approaches. Legacy ASR systems based on the franken-ASR hybrid are designed to handle "general" audio rather than specialized audio for industry, business, or even academic purposes.To put it another way, they provide generalized speech recognition and cannot realistically be trained to improve your speech data.
Also Read | Speech Analytics
Types of ASR
The two main types of Automatic Speech Recognition software variants are directed dialogue conversations and natural language conversations.
Detecting a direct dialogue speech
Directed Dialogue conversations are a much less complicated version of ASR at work, consisting of machine interfaces that instruct you to respond verbally with a specific word from a limited list of options, forming their response to your narrowly defined request. Directed conversation Automated telephone banking and other customer service interfaces frequently use ASR software.
Analyze natural language conversation
Natural Language Conversations (the NLP we discussed in the introduction) are more advanced versions of ASR that attempt to simulate real conversation by allowing you to use an open-ended chat format with them rather than a severely limited menu of words. One of the most advanced examples of these systems is the Siri interface on the iPhone.
Applications of ASR
Where continuous conversations must be tracked or recorded word for word, ASR is used in a variety of industries, including higher education, legal, finance, government, health care, and the media.
In legal proceedings, it's critical to record every word, and court reporters are in short supply right now. ASR technology has several advantages, including digital transcription and scalability.
ASR can be used by universities to provide captions and transcriptions in the classroom for students with hearing loss or other disabilities. It can also benefit non-native English speakers, commuters, and students with a variety of learning needs.
ASR is used by doctors to transcribe notes from patient meetings or to document surgical procedures.
Media companies can use ASR to provide live captions and media transcription for all of their productions.
Businesses use ASR for captioning and transcription to make training materials more accessible and to create more inclusive workplaces.
Also Read | Hyper Automation
Advantages of ASR over Traditional Transcriptions
We’ve listed some advantages of ASR over Traditional Transcriptions below :
ASR machines can help improve caption and transcription efficiencies, in addition to the growing shortage of skilled traditional transcribers.
In conversations, lectures, meetings, and proceedings, the technology can distinguish between voices, allowing you to figure out who said what and when.
Because disruptions among participants are common in these conversations with multiple stakeholders, the ability to distinguish between speakers can be very useful.
Users can train the ASR machine by uploading hundreds of related documents, such as books, articles, and other materials.
The technology can absorb this vast amount of data faster than a human, allowing it to recognize different accents, dialects, and terminology with greater accuracy.
Of course, in order to achieve the near-perfect accuracy required, the ideal format would involve using human intelligence to fact-check the artificial intelligence that is being used.
Automatic Speech Recognition Systems (ASRs) can convert spoken words into understandable text.
Its application to air traffic control and automated car environments has been studied due to its ability to convert speech in real-time.
The Hidden Markov model is used in feature extraction by the ASR system for air traffic control, and its phraseology is based on the commands used in air applications.
Speech recognition is used in the car environment for route navigation applications.
Also Read | Artificial Intelligence vs Human Intelligence
Automatic Speech Recognition vs Voice Recognition
The difference between Voice Recognition and Automatic Speech Recognition (the technical term for AI speech recognition, or ASR) is how they process and respond to audio.
You'll be able to use voice recognition with devices like Amazon Alexa or Google Dot. It listens to your voice and responds in real-time. Most digital assistants use voice recognition, which has limited functionality and is usually limited to the task at hand.
ASR differs from other voice recognition systems in that it recognizes speech rather than voices. It can accurately generate an audio transcript using NLP, resulting in real-time captioning. ASR isn't perfect; in fact, even under ideal conditions, it rarely exceeds 90%-95 percent accuracy . However, it compensates for this by being quick and inexpensive.
In essence, ASR is a transcription of what someone said, whereas Voice Recognition is a transcription of who said it. Both processes are inextricably linked, and they are frequently used interchangeably. The distinctions are subtle but noticeable.
Share Blog :
Be a part of our Instagram community
Trending blogs
5 Factors Influencing Consumer Behavior
Elasticity of Demand and its Types
What is PESTLE Analysis? Everything you need to know about it
An Overview of Descriptive Analysis
What is Managerial Economics? Definition, Types, Nature, Principles, and Scope
5 Factors Affecting the Price Elasticity of Demand (PED)
6 Major Branches of Artificial Intelligence (AI)
Dijkstra’s Algorithm: The Shortest Path Algorithm
Scope of Managerial Economics
Different Types of Research Methods
Latest Comments
jasonbennett355
Omg I Finally Got Helped !! I'm so excited right now, I just have to share my testimony on this Forum.. The feeling of being loved takes away so much burden from our shoulders. I had all this but I made a big mistake when I cheated on my wife with another woman and my wife left me for over 4 months after she found out.. I was lonely, sad and devastated. Luckily I was directed to a very powerful spell caster Dr Emu who helped me cast a spell of reconciliation on our Relationship and he brought back my wife and now she loves me far more than ever.. I'm so happy with life now. Thank you so much Dr Emu, kindly Contact Dr Emu Today and get any kind of help you want.. Via Email [email protected] or Call/WhatsApp cell number +2347012841542 Https://web.facebook.com/Emu-Temple-104891335203341
An Easy Introduction to Speech AI

Artificial intelligence (AI) has transformed synthesized speech from monotone robocalls and decades-old GPS navigation systems to the polished tone of virtual assistants in smartphones and smart speakers.
It has never been so easy for organizations to use customized state-of-the-art speech AI technology for their specific industries and domains.
Speech AI is being used to power virtual assistants , scale call centers, humanize digital avatars , enhance AR experiences , and provide a frictionless medical experience for patients by automating clinical note-taking.
According to Gartner Research , customers will prefer using speech interfaces to initiate 70% of self-service customer interactions (up from 40% in 2019) by 2023. The demand for personalized and automated experiences only continues to grow.
In this post, I discuss speech AI, how it works, the benefits of voice recognition technology, and examples of speech AI use cases.
What is speech AI, and what are the benefits?
Speech AI uses AI for voice-based technologies: automatic speech recognition (ASR), also known as speech-to-text, and text-to-speech (TTS). Examples include automatic live captioning in virtual meetings and adding voice-based interfaces to virtual assistants.
Similarly, language-based applications such as chatbots, text analytics, and digital assistants use speech AI as part of larger applications or systems, alongside natural language processing (NLP). For more information, see the Conversational AI glossary .

There are many benefits of speech AI:
- High availability : Speech AI applications can respond to customer calls during and outside of human agent hours, allowing contact centers to operate more efficiently.
- Real-time insights: Real-time transcripts are dictated and used as inputs for customer-focused business analyses such as sentiment analysis, customer experience analysis, and fraud detection.
- Instant scalability: During peak seasons, speech AI applications can automatically scale to handle tens of thousands of requests from customers.
- Enhanced experiences : Speech AI improves customer satisfaction by reducing holding times, quickly resolving customer queries, and providing human-like interactions with customizable voice interfaces.
- Digital accessibility: From speech-to-text to text-to-speech applications, speech AI tools are helping those with reading and hearing impairments to learn from generated spoken audio and written text.
Who is using speech AI and how?
Today, speech AI is revolutionizing the world’s largest industries such as finance, telecommunications, and unified communication as a service (UCaaS).

Companies starting out with deep-learning, speech-based technologies and mature companies augmenting existing speech-based conversational AI platforms benefit from speech AI.
Here are some specific examples of speech AI driving efficiencies and business outcomes.
Call center transcription
About 10 million call center agents are answering 2 billion phone calls daily worldwide. Call center use cases include all of the following:
- Trend analysis
- Regulatory compliance
- Real-time security or fraud analysis
- Real-time sentiment analysis
- Real-time translation
For example, automatic speech recognition transcribes live conversations between customers and call center agents for text analysis, which is then used to provide agents with real-time recommendations for quickly resolving customer queries .
Clinical note taking
In healthcare, speech AI applications improve patient access to medical professionals and claims representatives. ASR automates note-taking during patient-physician conversations and information extraction for claims agents.
Virtual assistants
Virtual assistants are found in every industry enhancing user experience. ASR is used to transcribe an audio query for a virtual assistant. Then, text-to-speech generates the virtual assistant’s synthetic voice. Besides humanizing transactional situations, virtual assistants also help the visually impaired interact with non-braille texts, the vocally challenged to communicate with individuals , and children to learn how to read .
How does speech AI work?
Speech AI uses automatic speech recognition and text-to-speech technology to provide a voice interface for conversational applications. A typical speech AI pipeline consists of data preprocessing stages, neural network model training, and post-processing.
In this section, I discuss these stages in both ASR and TTS pipelines.

Automatic speech recognition
For machines to hear and speak with humans, they need a common medium for translating sound into code. How can a device or an application “see” the world through sound?
An ASR pipeline processes and transcribes a given raw audio file containing speech into corresponding text while minimizing a metric known as the word error rate (WER).
WER is used to measure and compare performance between types of speech recognition systems and algorithms. It is calculated by the number of errors divided by the number of words in the clip being transcribed.
ASR pipelines must accomplish a series of tasks, including feature extraction, acoustic modeling, as well as language modeling.

The feature extraction task involves converting raw analog audio signals into spectrograms, which are visual charts that represent the loudness of a signal over time at various frequencies and resemble heat maps. Part of the transformation process involves traditional signal preprocessing techniques like standardization and windowing .
Acoustic modeling is then used to model the relationship between the audio signal and the phonetic units in the language. It maps an audio segment to the most likely distinct unit of speech and corresponding characters.
The final task in an ASR pipeline involves language modeling. A language model adds contextual representation and corrects the acoustic model’s mistakes. In other words, when you have the characters from the acoustic model, you can convert these characters to sequences of words, which can be further processed into phrases and sentences.
Historically, this series of tasks was performed using a generative approach that required using a language model, pronunciation model, and acoustic model to translate pronunciations to audio waveforms. Then, either a Gaussian mixture model or hidden Markov model would be used to try to find the words that most likely match the sounds from the audio waveform.
This statistical approach was less accurate and more intensive in both time and effort to implement and deploy. This was especially true when trying to ensure that each time step of the audio data matched the correct output of characters.
However, end-to-end deep learning models, like connectionist temporal classification (CTC) models and sequence-to-sequence models with attention , can generate the transcript directly from the audio signal and with a lower WER.
In other words, deep learning-based models like Jasper , QuartzNet , and Citrinet enable companies to create less expensive, more powerful, and more accurate speech AI applications.
Text-to-speech
A TTS or speech synthesis pipeline is responsible for converting text into natural-sounding speech that is artificially produced with human-like intonation and clear articulation.

TTS pipelines potentially must accomplish a number of different tasks, including text analysis, linguistic analysis , and waveform generation.
During the text analysis stage, raw text (with symbols, abbreviations, and so on) is converted into full words and sentences, expanding abbreviations, and analyzing expressions. The output is passed into linguistic analysis for refining intonation, duration, and otherwise understanding grammatical structure. As a result, a spectrogram or mel-spectrogram is produced to be converted into continuous human-like audio.
The preceding approach that I walked through is a typical two-step process requiring a synthesis network and a vocoder network. These are two separate networks trained for the subsequent purposes of generating a spectrogram from text (using a Tacotron architecture or FastPitch ) and generating audio from the spectrogram or other intermediate representation (like WaveGlow or HiFiGAN ).
As well as the two-stage approach, another possible implementation of a TTS pipeline involves using an end-to-end deep learning model that uses a single model to generate audio straight from the text. The neural network is trained directly from text-audio pairs without depending on intermediate representations.
The end-to-end approach decreases complexity as it reduces error propagation between networks, mitigates the need for separate training pipelines, and minimizes the cost of manual annotation of duration information.
Traditional TTS approaches also tend to result in more robotic and unnatural-sounding voices that affect user engagement, particularly with consumer-facing applications and services.
Challenges in building a speech AI system
Successful speech AI applications must enable the following functionality.
Access to state-of-the-art models
Creating highly trained and accurate deep learning models from scratch is costly and time-consuming.
By providing access to cutting-edge models as soon as they’re published, even data and resource-constrained companies can use highly accurate, pretrained models and transfer learning in their products and services out-of-the-box.
High accuracy
To be deployed globally or to any industry or domain, models must be customized to account for multiple languages (a fraction of the 6,500 spoken languages in the world), dialects, accents, and contexts. Some domains use specific terminology and technical jargon .
Real-time performance
Pipelines consisting of multiple deep learning models must run inferences in milliseconds for real-time interactivity, precisely far less than 300 ms, as most users start to notice lags and communication breakdowns around 100 ms, preceding which conversations or experiences begin to feel unnatural.
Flexible and scalable deployment
Companies require different deployment patterns and may even require a mix of cloud, on-premises, and edge deployment. Successful systems support scaling to hundreds of thousands of concurrent users with fluctuating demand.
Data ownership and privacy
Companies should be able to implement the appropriate security practices for their industries and domains, such as safe data processing on-premises or in an organization’s cloud. For example, healthcare companies abiding by HIPAA or other regulations may be required to restrict access to data and data processing.
The future of speech AI
Thanks to advancements in computing infrastructure, speech AI algorithms, increased demand for remote services, and exciting new use cases in existing and emerging industries, there is now a robust ecosystem and infrastructure for speech AI-based products and services.
As powerful as the current applications of speech AI are in driving business outcomes, the next generation of speech AI applications must be equipped to handle multi-language, multi-domain, and multi-user conversations.
Organizations that can successfully integrate speech AI technology into their core operations will be well-equipped to scale their services and offerings for use cases yet to be listed.
Learn how your organization can deploy speech AI by checking out the free ebook, Building Speech AI Applications .
Related resources
- DLI course: Building Conversational AI Applications
- GTC session: Speech AI Demystified
- GTC session: Mastering Speech AI for Multilingual Multimedia Transformation
- GTC session: Speaking in Every Language: A Quick-Start Guide to TTS Models for Accented, Multilingual Communication
- Webinar: How Telcos Transform Customer Experiences with Conversational AI
- Webinar: How to Build and Deploy an AI Voice-Enabled Virtual Assistant for Financial Services Contact Centers
About the Authors

Related posts

How Speech Recognition Improves Customer Service in Telecommunications

Speech AI Spotlight: Reimagine Customer Service with Virtual Agents

Making an NVIDIA Riva ASR Service for a New Language
Exploring Unique Applications of Automatic Speech Recognition Technology

Essential Guide to Automatic Speech Recognition Technology

Efficient CUDA Debugging: Memory Initialization and Thread Synchronization with NVIDIA Compute Sanitizer

Analyzing the Security of Machine Learning Research Code

Comparing Solutions for Boosting Data Center Redundancy
Validating nvidia drive sim radar models.

New Video Series: CUDA Developer Tools Tutorials
From Talk to Tech: Exploring the World of Speech Recognition

What is Speech Recognition Technology?
Imagine being able to control electronic devices, order groceries, or dictate messages with just voice. Speech recognition technology has ushered in a new era of interaction with devices, transforming the way we communicate with them. It allows machines to understand and interpret human speech, enabling a range of applications that were once thought impossible.
Speech recognition leverages machine learning algorithms to recognize speech patterns, convert audio files into text, and examine word meaning. Siri, Alexa, Google's Assistant, and Microsoft's Cortana are some of the most popular speech to text voice assistants used today that can interpret human speech and respond in a synthesized voice.
From personal assistants that can understand every command directed towards them to self-driving cars that can comprehend voice instructions and take the necessary actions, the potential applications of speech recognition are manifold. As technology continues to advance, the possibilities are endless.
How do Speech Recognition Systems Work?
speech to text processing is traditionally carried out in the following way:
Recording the audio: The first step of speech to text conversion involves recording the audio and voice signals using a microphone or other audio input devices.
Breaking the audio into parts: The recorded voice or audio signals are then broken down into small segments, and features are extracted from each piece, such as the sound's frequency, pitch, and duration.
Digitizing speech into computer-readable format: In the third step, the speech data is digitized into a computer-readable format that identifies the sequence of characters to remember the words or phrases that were most likely spoken.
Decoding speech using the algorithm: Finally, language models decode the speech using speech recognition algorithms to produce a transcript or other output.
To adapt to the nature of human speech and language, speech recognition is designed to identify patterns, speaking styles, frequency of words spoken, and speech dialects on various levels. Advanced speech recognition software are also capable of eliminating background noises that often accompany speech signals.
When it comes to processing human speech, the following two types of models are used:
Acoustic Models
Acoustic models are a type of machine learning model used in speech recognition systems. These models are designed to help a computer understand and interpret spoken language by analyzing the sound waves produced by a person's voice.
Language Models
Based on the speech context, language models employ statistical algorithms to forecast the likelihood of words and phrases. They compare the acoustic model's output to a pre-built vocabulary of words and phrases to identify the most likely word order that makes sense in a given context of the speech.
Applications of Speech Recognition Technology
Automatic speech recognition is becoming increasingly integrated into our daily lives, and its potential applications are continually expanding. With the help of speech to text applications, it's now becoming convenient to convert a speech or spoken word into a text format, in minutes.
Speech recognition is also used across industries, including healthcare , customer service, education, automotive, finance, and more, to save time and work efficiently. Here are some common speech recognition applications:
Voice Command for Smart Devices
Today, there are many home devices designed with voice recognition. Mobile devices and home assistants like Amazon Echo or Google Home are among the most widely used speech recognition system. One can easily use such devices to set reminders, place calls, play music, or turn on lights with simple voice commands.
Online Voice Search
Finding information online is now more straightforward and practical, thanks to speech to text technology. With online voice search, users can search using their voice rather than typing. This is an excellent advantage for people with disabilities and physical impairments and those that are multitasking and don't have the time to type a prompt.
Help People with Disabilities
People with disabilities can also benefit from speech to text applications because it allows them to use voice recognition to operate equipment, communicate, and carry out daily duties. In other words, it improves their accessibility. For example, in case of emergencies, people with visual impairment can use voice commands to call their friends and family on their mobile devices.
Business Applications of Speech Recognition
Speech recognition has various uses in business, including banking, healthcare, and customer support. In these industries, voice recognition mainly aims at enhancing productivity, communication, and accessibility. Some common applications of speech technology in business sectors include:
Speech recognition is used in the banking industry to enhance customer service and expedite internal procedures. Banks can also utilize speech to text programs to enable clients to access their accounts and conduct transactions using only their voice.
Customers in the bank who have difficulties entering or navigating through complicated data will find speech to text particularly useful. They can simply voice search the necessary data. In fact, today, banks are automating procedures like fraud detection and customer identification using this impressive technology, which can save costs and boost security.
Voice recognition is used in the healthcare industry to enhance patient care and expedite administrative procedures. For instance, physicians can dictate notes about patient visits using speech recognition programs, which can then be converted into electronic medical records. This also helps to save a lot of time, and correct data is recorded in the best way possible with this technology.
Customer Support
Speech recognition is employed in customer care to enhance the customer experience and cut expenses. For instance, businesses can automate time-consuming processes using speech to text so that customers can access information and solve problems without speaking to a live representative. This could shorten wait times and increase customer satisfaction.
Challenges with Speech Recognition Technology
Although speech recognition has become popular in recent years and made our lives easier, there are still several challenges concerning speech recognition that needs to be addressed.
Accuracy may not always be perfect
A speech recognition software can still have difficulty accurately recognizing speech in noisy or crowded environments or when the speaker has an accent or speech impediment. This can lead to incorrect transcriptions and miscommunications.
The software can not always understand complexity and jargon
Any speech recognition software has a limited vocabulary, so it may struggle to identify uncommon or specialized vocabulary like complex sentences or technical jargon, making it less useful in specific industries or contexts. Errors in interpretation or translation may happen if the speech recognition fails to recognize the context of words or phrases.
Concern about data privacy, data can be recorded.
Speech recognition technology relies on recording and storing audio data, which can raise concerns about data privacy. Users may be uncomfortable with their voice recordings being stored and used for other purposes. Also, voice notes, phone calls, and recordings may be recorded without the user's knowledge, and hacking or impersonation can be vulnerable to these security breaches. These things raise privacy and security concerns.
Software that Use Speech Recognition Technology
Many software programs use speech recognition technology to transcribe spoken words into text. Here are some of the most popular ones:
Nuance Dragon.
Amazon Transcribe.
Google Text to Speech
Watson Speech to Text
To sum up, speech recognition technology has come a long way in recent years. Given its benefits, including increased efficiency, productivity, and accessibility, its finding applications across a wide range of industries. As we continue to explore the potential of this evolving technology, we can expect to see even more exciting applications emerge in the future.
With the power of AI and machine learning at our fingertips, we're poised to transform the way we interact with technology in ways we never thought possible. So, let's embrace this exciting future and see where speech recognition takes us next!
What are the three steps of speech recognition?
The three steps of speech recognition are as follows:
Step 1: Capture the acoustic signal
The first step is to capture the acoustic signal using an audio input device and later pre-process the motion to remove noise and other unwanted sounds. The movement is then broken down into small segments, and features such as frequency, pitch, and duration are extracted from each piece.
Step 2: Combining the acoustic and language models
The second step involves combining the acoustic and language models to produce a transcription of the spoken words and word sequences.
Step 3: Converting the text into a synthesized voice
The final step is converting the text into a synthesized voice or using the transcription to perform other actions, such as controlling a computer or navigating a system.
What are examples of speech recognition?
Speech recognition is used in a wide range of applications. The most famous examples of speech recognition are voice assistants like Apple's Siri, Amazon's Alexa, and Google Assistant. These assistants use effective speech recognition to understand and respond to voice commands, allowing users to ask questions, set reminders, and control their smart home devices using only voice.
What is the importance of speech recognition?
Speech recognition is essential for improving accessibility for people with disabilities, including those with visual or motor impairments. It can also improve productivity in various settings and promote language learning and communication in multicultural environments. Speech recognition can break down language barriers, save time, and reduce errors.
You should also read:

Understanding Speech to Text in Depth

Top 10 Speech to Text Software in 2024

How Speech Recognition is Changing Language Learning
A Complete Guide to Speech Recognition Technology
Last Updated June 11, 2021

Here’s everything you need to know about speech recognition technology. History, how it works, how it’s used today, what the future holds, and what it all means for you.
Back in 2008, many of us were captivated by Tony Stark’s virtual butler, J.A.R.V.I.S, in Marvel’s Iron Man movie.
J.A.R.V.I.S. started as a computer interface. It was eventually upgraded to an artificial intelligence system that ran the business and provided global security.
Learn more about our speech data solutions.
J.A.R.V.I.S. opened our eyes – and ears – to the possibilities inherent in speech recognition technology. While we’re maybe not all the way there just yet, advancements are being used in many ways on a wide variety of devices.
Speech recognition technology allows for hands-free control of smartphones, speakers, and even vehicles in a wide variety of languages.
It’s an advancement that’s been dreamt of and worked on for decades. The goal is, quite simply, to make life simpler and safer.
In this guide we are going to take a brief look at the history of speech recognition technology. We’ll start with how it works and some devices that make use of it. Then we’ll examine what might be just around the corner.
History of Speech Recognition Technology
Speech recognition is valuable because it saves consumers and companies time and money.
The average typing speed on a desktop computer is around 40 words per minute. That rate diminishes a bit when it comes to typing on smartphones and mobile devices.
When it comes to speech, though, we can rack up between 125 and 150 words per minute. That’s a drastic increase.
Therefore, speech recognition helps us do everything faster—whether it’s creating a document or talking to an automated customer service agent .
The substance of speech recognition technology is the use of natural language to trigger an action. Modern speech technology began in the 1950s and took off over the decades.
Speech Recognition Through the Years
- 1950s : Bell laboratories developed “Audrey”, a system able to recognize the numbers 1-9 spoken by a single voice.
- 1960s : IBM came up with a device called “Shoebox” that could recognize and differentiate between 16 spoken English words.
- 1970s : The It led to the ‘Harpy’ system at Carnegie Mellon that could understand over 1,000 words.
- 1990s : The advent of personal computing brought quicker processors and opened the door for dictation technology. Bell was at it again with dial-in interactive voice recognition systems.
- 2000s : Speech recognition achieved close to an 80% accuracy rate. Then Google Voice came on the scene, making the technology available to millions of users and allowing Google to collect valuable data.
- 2010s : Apple launched Siri and Amazon came out with Alexa in a bid to compete with Google. This big three continues to lead the charge.
Slowly but surely, developers have moved towards the goal of enabling machines to understand and respond to more and more of our verbalized commands.
Today’s leading speech recognition systems—Google Assistant, Amazon Alexa, and Apple’s Siri—would not be where they are today without the early pioneers who paved the way.
Thanks to the integration of new technologies such as cloud-based processing and continuous improvements made thanks to speech data collection , these speech systems have continuously improved their ability to ‘hear’ and understand a wider variety of words, languages, and accents .
How Does Voice Recognition Work?
Now that we’re surrounded by smart cars, smart home appliances, and voice assistants, it’s easy to take for granted how speech recognition technology works .
Because the simplicity of being able to speak to digital assistants is misleading. Voice recognition is incredibly complicated—even now.
Think about how a child learns a language.
From day one, they hear words being used all around them. Parents speak and their child listens. The child absorbs all kinds of verbal cues: intonation, inflection, syntax, and pronunciation. Their brain is tasked with identifying complex patterns and connections based on how their parents use language.
But whereas human brains are hard-wired to acquire speech, speech recognition developers have to build the hard wiring themselves.
The challenge is building the language-learning mechanism. There are thousands of languages, accents, and dialects to consider, after all.
That’s not to say we aren’t making progress. In early 2020, researchers at Google were finally able to beat human performance on a broad range of language understanding tasks.
Google’s updated model now performs better than humans in labelling sentences and finding the right answers to a question.
Basic Steps
- A microphone transmits the vibrations of a person’s voice into a wavelike electrical signal.
- This signal in turn is converted by the system’s hardware—a computer’s sound card, for examples—into a digital signal.
- The speech recognition software analyzes the digital signal to register phonemes, units of sound that distinguish one word from another in a particular language.
- The phenomes are reconstructed into words.
To pick the correct word, the program must rely on context cues, accomplished through trigram analysis .
This method relies on a database of frequent three-word clusters in which probabilities are assigned that any two words will be followed by a given third word.
Think about the predictive text on your phone’s keyboard. A simple example would be typing “how are” and you phone would suggest “you?” The more you use it, though, the more it gets to know your tendencies and will suggest frequently used phrases.
Speech recognition software works by breaking down the audio of a speech recording into individual sounds, analyzing each sound, using algorithms to find the most probable word fit in that language, and transcribing those sounds into text.
How do companies build speech recognition technology?
A lot of this depends on what you’re trying to achieve and how much you’re willing to invest.
As it stands, there’s no need to start from scratch in terms of coding and acquiring speech data because much of that groundwork has been laid and is available to be built upon.
For instance, you can tap into commercial application programming interfaces (APIs) and access their speech recognition algorithms. The problem, though, is they’re not customizable.
You might instead need to seek out speech data collection that can be accessed quickly and efficiently through an easy-to-use API, such as:
- The Speech-to-text API from Google Cloud
- The Automatic Speech Recognition (ASR) system from Nuance
- IBM Watson “Speech to text” API
From there, you design and develop software to suit your requirements. For example, you might code algorithms and modules using Python
Regional accents and speech impediments can throw off word recognition platforms, and background noise can be difficult to penetrate, not to mention multiple-voice input. In other words, understanding speech is a much bigger challenge than simply recognizing sounds.
Different Models
- Acoustic : Take the waveform of speech and break it up into small fragments to predict the most likely phonemes in the speech.
- Pronunciation : Take the sounds and tie them together to make words, i.e. associate words with their phonetic representations.
- Language : Take the words and tie them together to make sentences, i.e. predict the most likely sequence of words (or text strings) among several a set of text strings.
Algorithms can also combine the predictions of acoustic and language models to offer outputs the most likely text string for a given speech file input.
To further highlight the challenge, speech recognition systems have to be able to distinguish between homophones (words with the same pronunciation but different meanings), to learn the difference between proper names and separate words (“Tim Cook” is a person, not a request for Tim to cook), and more.
After all, speech recognition accuracy is what determines whether voice assistants become a can’t-live-without accessory.

How Voice Assistants Bring Speech Recognition into Everyday Life
Speech recognition technology has grown leaps and bounds in the early 21 st century and has literally come home to roost.
Look around you. There could be a handful of devices at your disposal at this very moment.
Let’s look at a few of the leading options.
Apple’s Siri
Apple’s Siri emerged as the first popular voice assistant after its debut in 2011. Since then, it has been integrated on all iPhones, iPads, the Apple Watch, the HomePod, Mac computers, and Apple TV.
Siri is even used as the key user interface in Apple’s CarPlay infotainment system, as well as the wireless AirPod earbuds, and the HomePod Mini.
Siri is with you everywhere you go; on the road, in your home, and for some, literally on your body. This gave Apple a huge advantage in terms of early adoption.
Naturally, being the earliest quite often means receiving most of the flack for functionality that might not work as expected.
Although Apple had a big head start with Siri, many users expressed frustration at its seeming inability to properly understand and interpret voice commands.
If you asked Siri to send a text message or make a call on your behalf, it could easily do so. However, when it came to interacting with third-party apps, Siri was a little less robust compared to its competitors.
But today, an iPhone user can say, “Hey Siri, I’d like a ride to the airport” or “Hey Siri, order me a car,” and Siri will open whatever ride service app you have on your phone and book the trip.
Focusing on the system’s ability to handle follow-up questions, language translation, and revamping Siri’s voice to something more human-esque is helping to iron out the voice assistant’s user experience.
As of 2021, Apple hovers over its competitors in terms of availability by country and thus in Siri’s understanding of foreign accents. Siri is available in more than 30 countries and 21 languages – and, in some cases, several different dialects.
Amazon Alexa
Amazon announced Alexa and the Echo to the world in 2014, kicking off the age of the smart speaker.
Alexa is now housed inside the following:
- Smart speaker
- Show (a voice-controlled tablet)
- Spot (a voice-controlled alarm clock)
- Buds headphones (Amazon’s version of Apple’s AirPods).
In contrast to Apple, Amazon has always believed the voice assistant with the most “skills”, (its term for voice apps on its Echo assistant devices) “will gain a loyal following, even if it sometimes makes mistakes and takes more effort to use”.
Although some users pegged Alexa’s word recognition rate as being a shade behind other voice platforms, the good news is that Alexa adapts to your voice over time, offsetting any issues it may have with your particular accent or dialect.
Speaking of skills, Amazon’s Alexa Skills Kit (ASK) is perhaps what has propelled Alexa forward as a bonafide platform. ASK allows third-party developers to create apps and tap into the power of Alexa without ever needing native support.
Alexa was ahead of the curve with its integration with smart home devices. They had cameras, door locks, entertainment systems, lighting, and thermostats.
Ultimately, giving users absolute control of their home whether they’re cozying up on their couch or on-the-go. With Amazon’s Smart Home Skill API , you can enable customers to control their connected devices from tens of millions of Alexa-enabled endpoints.
When you ask Siri to add something to your shopping list, she adds it without buying it for you. Alexa however goes a step further.
If you ask Alexa to re-order garbage bags, she’ll scroll Amazon and order some. In fact, you can order millions of products off Amazon without ever lifting a finger; a natural and unique ability that Alexa has over its competitors.
Google Assistant
How many of us have said or heard “let me Google that for you”? Almost everyone, it seems. It only makes sense then, that Google Assistant prevails when it comes to answering (and understanding) all questions its users may have.
From asking for a phrase to be translated into another language, to converting the number of sticks of butter in one cup, Google Assistant not only answers correctly, but also gives some additional context and cites a source website for the information.
Given that it’s backed by Google’s powerful search technology, perhaps it’s an unsurprising caveat.
Though Amazon’s Alexa was released (through the introduction of Echo) two years earlier than Google Home, Google has made great strides in catching up with Alexa in a very short time. Google Home was released in late 2016, and within a year, had already established itself as the most meaningful opponent to Alexa.
In 2017, Google boasted a 95% word accuracy rate for U.S. English, the highest out of all the voice-assistants currently out there. This translates to a 4.9%-word error rate – making Google the first of the group to fall below the 5% threshold.
Word-error rate has its limitations , though. Factors that affect the data include:
- Background noise
Still, they’re getting close to 0% and that’s significant.
To get a better sense of the languages supported by these voice assistants, be sure to check out our comparison article .
Where else is speech recognition technology prevalent?
Voice assistants are far from the only mechanisms through which advancements in speech recognition are becoming even more mainstream.
In-Car Speech Recognition
Voice-activated devices and digital voice assistants aren’t just about making things easier. It’s also about safety – at least it is when it comes to in-car speech recognition .
Companies like Apple, Google, and Nuance have completely reshaped the driver’s experience in their vehicle—aiming at removing the distraction of looking down at your mobile phone while you drive allows drivers to keep their eyes on the road.
- Instead of texting while driving, you can now tell your car who to call or what restaurant to navigate to.
- Instead of scrolling through Apple Music to find your favorite playlist, you can just ask Siri to find and play it for you.
- If the fuel in your car is running low, your in-car speech system can not only inform you that you need to refuel, but also point out the nearest fuel station and ask whether you have a preference for a particular brand. Or perhaps it can warn you that the petrol station you prefer is too far to reach with the fuel remaining.
When it comes to safety, there’s an important caveat to be aware of. A report published by the UK’s Transport Research Laboratory (TRL) showed that driver distraction levels are much lower when using voice activated system technologies compared to touch screen systems.
However, it recommends that further research is necessary to steer the use of spoken instructions as the safest method for future in-car control, seeing as the most effective safety precautions would be the elimination of distractions altogether.
That’s where field data collection comes in.
How to Train a Car
Companies need precise and comprehensive data with respect to terms and phrases that would be used to communicate in a vehicle.
Field data collection is conducted in a specifically chosen physical location or environment as opposed to remotely . This data is collected via loosely structured scenarios that include elements like culture, education, dialect, and social environment that can an impact on how a user will articulate a request.
This is best suited for projects with specific environmental requirements, such as specific acoustics for sound recordings.
Think about in-car speech recognition , for example. Driving around presents very unique circumstances in terms of speech data.
You must be able to record speech data from the cabin of a car to simulate acoustic environment, background noises, and voice commands used in real scenarios.
That’s how you reach new levels of innovation in human and machine interaction.
Voice-Activated Video Games
Speech recognition technology is also making strides in the gaming industry.
Voice-activated video games have begun to extend from the classic console and PC format to voice-activated mobile games and apps .
Creating a video game is already extraordinarily difficult. It takes years to properly flesh out the plot, the gameplay, character development, customizable gear, worlds, and so on. The game also has to be able to change and adapt based on each player’s actions.
Now, just imagine adding another layer to gaming through speech recognition technology.
Many of the companies championing this idea do so with the intention of making gaming more accessible for visually and/or physically impaired players, as well as allowing players to immerse themselves further into gameplay through enabling yet another layer of integration.
Voice control could also potentially lower the learning curve for beginners, seeing as less importance will be placed on figuring out controls. Players can just begin talking right away.
Moving forward, text-to-speech (TTS), synthetic voices, and generative neural networks will help developers create spoken and dynamic dialogue .
You will be able to have a conversation with characters within the game itself.
The rise of speech technology in video games has only just begun.
Speech Recognition Technology: The Focus Moving Forward
What does the future of speech recognition hold?
Here are a few key areas of focus you can expect moving forward.
1. Mobile app voice integration
Integrating voice-tech into mobile apps has become a hot trend, and will remain so because speech is a natural user interface (NUI).
Voice-powered apps increase functionality and save users from complicated navigation.
It’s easier for the user to navigate an app — even if they don’t know the exact name of the item they’re looking for or where to find it in the app’s menu.
Voice integration will soon become a standard that users will expect.
2. Individualized experiences
Voice assistants will also continue to offer more individualized experiences as they get better at differentiating between voices.
Google Home, for example, can not only support up to six user accounts but also detect unique voices, which allows you to customize many features.
You can ask “What’s on my calendar today?” or “tell me about my day?” and the assistant will dictate commute times, weather, and news information tailored specifically to you.
It also includes features such as nicknames, work locations, payment information, and linked accounts such as Google Play, Spotify, and Netflix.
Similarly, for those using Alexa, saying “learn my voice” will allow you to create separate voice profiles so it can detect who is speaking.
3. Smart displays
The smart speaker is great and all, but what people are really after now is the smart display, essentially a smart speaker with a touch screen attached to it.
In 2020, the sale of smart displays rose by 21% to 9.5 million units, while basic smart speakers fell by 3%, and that trend is only likely to continue.
Smart displays like the Russian Sber portal or the Chinese smart screen Xiaodu, for example, are already equipped with several AI-powered functions, including far-field voice interaction, facial recognition, hand gesture control, and eye gesture detection.
Collect Better Data
We help you create outstanding human experiences with high-quality speech, image, video, or text data for AI.
Summa Linguae Technologies collects and annotates the training and testing data you need to build your AI-powered solutions, including voice assistants, wearables, autonomous vehicles, and much more.
We offer both in-field and remote data collection options. They’re backed by a network of technical engineers, project managers, quality assurance professionals, and annotators.
Here are a few resources you can tap into right away:
- Data Sets – Sample of our pre-packaged speech , image , and video data sets. These data samples are free to download and provide a preview of the capabilities of our ready-to-order or highly customizable data solutions .
- The Ultimate Guide to Data Collection (PDF) – Learn how to collect data for emerging technology.
Want even more? Contact us today for a full speech data solutions consultation.
Related Posts

Amazon Flags Low-Quality Training Data for LLMs
The tools are out there to gather large swaths of training data for LLMS, but human touchpoints help clean...

Should you trust voice assistants for medical advice?
If you have specific health concerns or questions, it’s always best to consult a qualified healthcar...

Where are we with voice recognition technology in 2023?
The voice recognition technology landscape is rapidly evolving. Here’s where we are midway through 2023. I...
Summa Linguae uses cookies to allow us to better understand how the site is used. By continuing to use this site, you consent to this policy.
What we do best
AI Data Services
Data Collection Create & collect audio, images, text & video from across the globe.
Data Annotation & Labeling Accurately annotate data to make AI & ML think faster & smarter.
Data Transcription AI-driven, cloud-based transcription supporting 150+ languages.
Healthcare AI Harness the power to transform complex data into actionable insight.
Conversational AI Localize AI-enabled speech models with rich structured multi-lingual datasets.
Computer Vision Train ML models with best-in-class AI data to make sense of the visual world.
Generative AI Harness the power to transform complex data into actionable insight.
- Question & Answering Pairs
- Text Summarization
- LLM Data Evaluation
- LLM Data Comparison
- Synthetic Dialogue Creation
- Image Summarization, Rating & Validation
Off-the-shelf Data Catalog & Licensing
Medical Datasets Gold standard, high-quality, de-identified healthcare data.
Physician Dictation Datasets
Transcribed Medical Records
Electronic Health Records (EHR)
CT Scan Images Datasets
X-Ray Images Datasets
Computer Vision Datasets Image and Video datasets to accelerate ML development.
Bank Statement Dataset
Damaged Car Image Dataset
Facial Recognition Datasets
Landmark Image Dataset
Pay Slips Dataset
Speech/Audio Datasets Source, transcribed & annotated speech data in over 50 languages.
New York English | TTS
Chinese Traditional | Utterance/Wake Word
Spanish (Mexico) | Call-Center
Canadian French | Scripted Monologue
Arabic | General Conversation
Banking & Finance Improve ML models to create a secure user experience.
Automotive Highly accurate training & validation data for Autonomous Vehicles.
eCommerce Improve shopping experience with AI to increase Conversion, Order Value, & Revenue.
Named Entity Recognition Unlock critical information in unstructured data with entity extraction in NLP.
Facial Recognition Auto-detect one or more human faces based on facial landmarks.
Search Queries Optimization Improving online store search results for better customer traffic.
Text-To-Speech (TTS) Enhance interactions with precise global language TTS datasets.
Content Moderation Services Power AI with data-driven content moderation & enjoy improved trust & brand reputation.
Optical Character Recognition (OCR) Optimize data digitization with high-quality OCR training data.
AI innovation in Healthcare
- Healthcare AI
Medical Annotation
Data De-identification
Clinical Data Codification
Clinical NER
- Generative AI
Off-the-Shelf Datasets
- Events & Webinar
- Security & Compliance
- Buyer’s Guide
- Infographics
- In The Media
- Sample Datasets

- April 18, 2023
Automatic Speech Recognition (ASR): Everything a Beginner Needs to Know (in 2024)
Automatic Speech Recognition technology has been there for a long haul but recently gained prominence after its use became prevalent in various smartphone applications like Siri and Alexa. These AI-based smartphone applications have illustrated the power of ASR in simplifying everyday tasks for all of us.
Additionally, as different industry verticals further move toward automation, the underlying need for ASR is subjected to surge. Hence, let us understand this terrific speech recognition technology in-depth and why it is considered one of the most crucial technologies for the future.
A Brief History of ASR Technology
Before proceeding ahead and exploring the potential of Automatic Speech Recognition, let us first take a look at its evolution.
In the 1950s, Bell Labs created a virtual speech recognizer known as ‘Audrey’ that could identify the numbers between 1-9 when spoken by a single voice.
In 1952, IBM launched its first voice recognition system, ‘Shoebox,’ which could understand and differentiate between sixteen English words.
Carnegie Mellon University in the year 1976 developed a ‘Harpy’ system that could recognize over 1000 words.
After 40 years, Bell Technologies again breakthrough the industry with its dial-in IVR systems that could dictate human speech.
Google created advanced speech software with an accuracy rate of 80%, making it popular worldwide.
The last decade became a golden period for ASR, with Amazon and Apple launching their first-ever AI-based speech software, Alexa and Siri.
Moving ahead of 2010, ASR is tremendously evolving and becoming more and more prevalent and accurate. Today, Amazon, Google, and Apple are the most prominent leaders in ASR technology.
[ Also Read: The Complete Guide to Conversational AI ]
How Does Voice Recognition Work?
Automatic Speech Recognition is a fairly advanced technology that is extremely hard to design and develop. There are thousands of languages worldwide with various dialects and accents, so it is hard to develop software that can understand it all.
ASR uses concepts of natural language processing and machine learning for its development. By incorporating numerous language-learning mechanisms in the software, developers ensure the precision and efficiency of speech recognition software.
Here are some of the basic steps used in developing Automatic Speech Recognition software:
- Transmission of Voice into Electrical Signal: The vibrations of a person’s voice are captured using a microphone and transmitted into a wavelike electrical signal.
- Transforming Electrical into Digital Signal: The electric signal is further converted into a digital signal using physical devices like a sound card.
- Registering Phonemes to the Software: The speech recognition software then examines the digital signal and registers phonemes to differentiate between the captured words.
- Reconstructing Phonemes to Words: After processing the digital signal completely and registering all the phonemes, words are reconstructed, and sentences are formed.
To achieve the intended accuracy, the software leverages the trigram analysis method, which relies on using three frequently used words through a specific database. The ASR software is an exceptional technology that breaks down any audio pattern, analyzes the sounds, and transcribes those collected sounds into meaningful text and words.
[ Also Read: What is Speech-to-Text Technology and How it works ]

Real-World Examples of ASR

What is Speech-To-Text Technology and How Does it Works in Automatic Speech Recognition

Making Speech Recognition Streamlined with Remote Speech Data Collection

The Future of Language Processing: Large Language Models and Their Examples
- Data Annotation
- Data Collection
- Data De-Identification
- Conversational AI
- Computer Vision
- Automotive AI
- Banking & Finance
- ShaipCloud™ Platform
(US): (866) 473-5655
[email protected] [email protected] [email protected]
Vendor Enrollment Form
© 2018 – 2024 Shaip | All Rights Reserved
The Power of Speech Recognition in Natural Language Processing

Introduction to Speech Recognition in Natural Language Processing
Voice recognition is an increasingly important technology in natural language processing (NLP). It is a form of artificial intelligence that enables machines to understand and interpret spoken language. Speech recognition has been around since the 1950s and has seen rapid advances over the past few decades. It is now being used in a variety of applications, including customer service, medical care, and automotive navigation.
At its core, speech recognition involves training computers to recognize speech patterns. This requires sophisticated algorithms that are able to identify words and phrases from audio input. Speech recognition can be used for both voice commands (such as “Call John Smith”) or for more complex tasks such as understanding natural conversations between two people.
The power of speech recognition lies in its ability to allow machines to interact with humans in more natural ways than before. For example, instead of having users type out commands on a keyboard or touch screen, they can simply speak into a microphone or other device and receive responses from the machine in natural language. This opens up all kinds of possibilities for improving user experiences, streamlining processes, and creating new opportunities for businesses and organizations alike.
Exploring the Benefits of Speech Recognition for AI Research
Speech recognition is rapidly becoming an integral part of artificial intelligence (AI) research. It has the potential to revolutionize the way machines interact with humans and enhance natural language processing (NLP). Speech recognition technology is already being used in a variety of applications, from voice-activated virtual assistants to automated customer service systems.
The primary benefit of speech recognition for AI research is its accuracy. Unlike traditional text-based input methods, speech recognition offers a more accurate method of understanding human intent and commands. This makes it easier for researchers to develop more sophisticated AI algorithms that can interpret complex user requests. Additionally, speech recognition enables quicker response times by eliminating the need to manually type out commands or queries.
Another advantage of speech recognition for AI research is its scalability. As more data becomes available about how users interact with voice agents, this technology can be used to create better models and improve accuracy over time. This allows researchers to quickly iterate on their algorithms without having to manually update large amounts of data or manually review results each time they make changes.
Finally, speech recognition also offers cost savings because it eliminates the need for expensive hardware or software investments associated with manual transcription and other text-based input methods. By relying on existing infrastructure such as cloud computing systems or mobile devices, researchers can quickly test their models at minimal cost while ensuring greater accuracy than ever before.
Understanding the Challenges Facing Speech Recognition Technology
Speech recognition technology has come a long way in recent decades, but there are still challenges remaining that need to be addressed. One of the major obstacles is the inability of computers to recognize speech in noisy environments or with multiple speakers. Humans have an incredible ability to filter out background noise and understand what is being said even when there are multiple people speaking at once. This is something that computers still struggle with, and so it’s one area where a lot of research needs to be done.
Another challenge facing speech recognition technology is its accuracy rate when dealing with different accents and dialects. Even though researchers have made great strides in developing software that can effectively recognize different accents, it’s still far from perfect. Different parts of the world use different languages and dialects, so speech recognition software must be able to accurately pick up on these differences if it’s going to be useful for natural language processing applications.
Finally, there’s always the risk of data privacy violations when using speech recognition technology. As more companies adopt this technology for their products and services, they need to ensure that user data is secure and not misused. It’s important for developers of speech-based products and services to consider ethical implications before releasing them into the market place in order to protect users from potential security risks or privacy breaches.
Key Concepts and Terminology of Speech Recognition
When it comes to speech recognition and natural language processing (NLP), there are certain concepts that are key to understanding the technology. Here, we’ll cover some of the most important terms related to NLP & SR.
Artificial Intelligence (AI) : AI is used to describe computer systems that can learn, reason, and act like humans. AI technology can be used in a variety of applications, such as robotics, natural language processing, and speech recognition.
Machine Learning (ML) : ML is a type of artificial intelligence in which computers use data to make decisions or predictions without explicit programming instructions. Through machine learning algorithms, computers can learn from experience and adjust their behavior accordingly.
Natural Language Processing (NLP) : NLP is an interdisciplinary field focusing on the interactions between human languages and computers/machines. It involves using algorithms to understand written or spoken input in order for machines to take action based on this input.
Speech Recognition (SR) : Speech recognition is a subfield within NLP focused on enabling machines to recognize human speech so they can interpret what’s being said and respond accordingly. It requires specialized software that uses sophisticated algorithms for interpreting audio signals into words or phrases understood by the machine.
With advances in technology making it easier than ever before for us to communicate with machines through voice commands, it’s clear that speech recognition will continue playing an increasingly important role in natural language processing going forward.
Examining the Impact of Voice Assistants on Natural Language Processing
Voice assistants are becoming increasingly commonplace as technology advances and more people become accustomed to using them. Voice assistants such as Alexa, Siri, and Google Assistant are powered by natural language processing (NLP) and speech recognition (SR) software that can understand spoken commands and respond to the user’s voice with an appropriate response. This technology has opened up a whole new realm of possibilities for both consumers and businesses alike, allowing users to access information quickly through conversational interactions.
The use of voice assistants has already had a profound impact on natural language processing. For example, NLP algorithms have been improved through machine learning techniques that allow AI systems to better understand human speech patterns. Additionally, the increasing prevalence of voice assistants has driven research into more complex tasks such as sentiment analysis and dialogue management. This is especially important in fields like healthcare, where conversations between doctors and patients can be monitored for medical accuracy or to detect changes in mood or behavior over time.
Voice assistants also represent a unique opportunity for personalization within natural language processing applications. By leveraging data from previous conversations with users, these systems can tailor their responses based on individual preferences or prior interactions with the user. This type of customization could help create a more personalized experience when interacting with AI-powered applications like chatbots or virtual assistant technologies.
Ultimately, voice-enabled technologies are transforming how we interact with machines – making it easier than ever before for us to communicate our needs quickly and accurately without having to learn complex syntax rules or memorize specific commands. The potential implications of this shift should not be underestimated; as companies continue to invest in NLP & SR research, we will likely see continued advancements in how effectively we communicate with computers in the near future.
How Human-Computer Interaction is Shaping the Future of NLP & SR
The development of Natural Language Processing (NLP) and Speech Recognition (SR) technologies has been nothing short of revolutionary, profoundly impacting the way humans interact with computers. As technology advances, human-computer interaction is continuously evolving, allowing for more intuitive and natural user experiences.
One area where this evolution is particularly evident is in the use of voice assistants. We have seen a huge increase in the usage of virtual assistants like Alexa or Google Home over recent years as these devices become increasingly popular for helping us to control our appliances, search the web or even order products online. These developments are greatly enabled by the progress made in NLP and SR technology which allows these machines to understand and respond to human speech.
Another example lies in automated customer service bots that are becoming more commonplace as companies look to streamline their operations while providing more efficient customer service. Through NLP and SR capabilities, customers can now converse with chatbots just as they would a real person without knowing that there’s artificial intelligence at work behind the scenes.
These examples demonstrate how Human-Computer Interaction has become an integral part of modern day life, not only enabling more efficient ways to communicate but also influencing how we perceive technology itself. The potential applications for such advancements are seemingly endless; from using speech recognition software to drive autonomous vehicles safely on our roads, to designing intelligent robotic systems that can be employed in dangerous scenarios such as hazardous waste disposal or search-and-rescue missions – all driven by AI algorithms powered by NLP & SR technology.
It’s clear that this combination of Human-Computer Interaction and Artificial Intelligence will play an important role in shaping the future course of both Natural Language Processing & Speech Recognition research and development - pushing boundaries further than ever before so that one day we may reach new heights never imagined possible today!
The Role of Machine Learning in Enhancing Speech Recognition Accuracy
Machine learning has become an increasingly important tool for natural language processing (NLP) and speech recognition (SR). With the help of machine learning algorithms, researchers have been able to develop systems that can accurately recognize and interpret human speech with minimal errors. Machine learning enables computers to learn from large datasets of audio recordings, allowing them to become better at recognizing patterns in speech and understanding natural language.
By leveraging powerful machine learning algorithms such as deep neural networks, researchers are able to process large amounts of data in a fraction of the time it would take humans. This enables much faster development times, leading to more accurate voice recognition technology. Furthermore, by incorporating unsupervised methods such as clustering or random forests into their models, researchers can also improve accuracy by identifying important features in the input data that would have otherwise gone unnoticed.
The combination of supervised and unsupervised methods is essential for achieving high levels of accuracy when building models for NLP & SR applications. By training models on both labeled and unlabeled data sets, these systems can learn complex patterns within speech inputs that may not be apparent when only using one or the other type of data set alone. Additionally, these models can also be fine-tuned over time as new input data becomes available or changes occur within the environment they are deployed in. This allows developers to quickly adjust their model parameters accordingly and continue optimizing performance without having to start from scratch each time.
In summary, machine learning plays a key role in improving accuracy when it comes to NLP & SR applications. By leveraging powerful supervised and unsupervised techniques such as deep neural networks or clustering, developers are able to build highly accurate systems capable of interpreting human speech with little error rate. Additionally, these systems can be quickly adjusted over time based on new input data or changing environmental conditions without having to go through a complete rebuild process each time – making them extremely useful for rapidly evolving fields like natural language processing & speech recognition research!
Case Studies: Applied Examples of NLP & SR in Real-World Scenarios
NLP and SR technology have already been applied to a wide range of real-world scenarios. Let’s look at some examples of how speech recognition has been used in the field.
One of the most fascinating applications of NLP and SR is within healthcare. AI-powered medical assistants are being developed to automatically transcribe patient notes, allowing doctors to focus more on providing quality care rather than dealing with paperwork. These systems can even detect potential symptoms or diagnoses from patient conversations, helping doctors provide better treatment plans for their patients.
Another example is customer service automation. Companies like Amazon use automated chatbots powered by NLP and SR technology to quickly answer customer inquiries without needing human oversight. This allows them to provide faster, more efficient support with fewer resources and improved customer satisfaction rates.
Finally, voice search optimization has become increasingly important for businesses looking to stay ahead of the competition online. By leveraging NLP and SR technologies, companies can optimize their website content for voice search queries, making it easier for customers to find exactly what they’re looking for in an instant via voice command alone.
These are just a few examples of how NLP and SR technology have already been applied in real-world scenarios today—and there are sure to be many more exciting developments in the years ahead!
Looking Ahead: Trends and Potential Developments in NLP & SR
With the continuing advances in machine learning, natural language processing (NLP) and speech recognition (SR) are set to become increasingly powerful tools for both businesses and consumers. In the coming years, we can expect to see a wide range of applications that make use of these technologies, from voice-driven customer service systems to virtual assistants that can help with day-to-day tasks. Already we are beginning to see how NLP and SR can be used in combination with other AI tools such as computer vision and robotics to create more sophisticated AI solutions than ever before.
In addition, there is potential for further developments in the field of speech recognition technology. As software continues to improve and hardware costs continue to decrease, it will become easier for businesses large and small alike to implement this technology into their products or services. At the same time, researchers are continually striving towards improving SR accuracy by exploring new approaches such as deep learning architectures or unsupervised methods.
All in all, there’s no doubt that NLP & SR have an incredible amount of potential when it comes to revolutionizing our lives through advances in AI technology. With continued research into these areas over the next few years, we should start seeing some truly remarkable breakthroughs in artificial intelligence that could transform how humans interact with machines on a day-to-day basis.
In conclusion, speech recognition has come a long way since its first introduction several decades ago. From helping us communicate more efficiently with computers through natural language processing techniques to driving the development of smarter virtual assistants with improved accuracy over time–speech recognition has been making great strides within the realm of artificial intelligence over recent years. Looking ahead at what’s yet come for NLP & SR, it’ll be exciting see just where this technology takes us next!
- Artificial intelligence
- Natural Language Processing
- Speech Recognition
Voice technology for the rest of the world
Project aims to build a dataset with 1,000 words in 1,000 different languages to bring voice technology to hundreds of millions of speakers around the world.
Voice-enabled technologies like Siri have gone from a novelty to a routine way to interact with technology in the past decade. In the coming years, our devices will only get chattier as the market for voice-enabled apps, technologies and services continues to expand.
But the growth of voice-enabled technology is not universal. For much of the world, technology remains frustratingly silent.
“Speech is a natural way for people to interact with devices, but we haven’t realized the full potential of that yet because so much of the world is shut out from these technologies,” said Mark Mazumder, a Ph.D. student at the Harvard John A. Paulson School of Engineering and Applied Sciences (SEAS) and the Graduate School of Arts and Sciences.
The challenge is data. Voice assistants like Apple’s Siri or Amazon’s Alexa need thousands to millions of unique examples to recognize individual keywords like “light” or “off”. Building those enormous datasets is incredibly expensive and time-consuming, prohibiting all but the biggest companies from developing voice recognition interfaces.
Even companies like Apple and Google only train their models on a handful of languages, shutting out hundreds of millions of people from interacting with their devices via voice. Want to build a voice-enabled app for the nearly 50 million Hausa speakers across West Africa? Forget it. Neither Siri, Alexa nor Google Home currently support a single African language.
But Mazumder and a team of SEAS researchers, in collaboration with researchers from the University of Michigan, Intel, NVIDIA, Landing AI, Google, MLCommons and Coqui, are building a solution to bring voice technology to the rest of the world.
At the Neural Information Processing Systems conference last week, the team presented a diverse, multilingual speech dataset that spans languages spoken by over 5 billion people. Dubbed the Multilingual Spoken Words Corpus , the dataset has more than 340,000 keywords in 50 languages with upwards of 23.4 million audio examples so far.
“We have built a dataset automation pipeline that can automatically identify and extract keywords and synthesize them into a dataset,” said Vijay Janapa Reddi , Associate Professor of Electrical Engineering at SEAS and senior author of the study. “The Multilingual Spoken Words Corpus advances the research and development of voice-enabled applications for a broad global audience."

Voice interfaces can make technology more accessible for users with visual or physical impairments, or for lower literacy users. We hope free datasets like ours will help assistive technology developers to meet these needs.

Speech technology can empower billions of people across the planet, but there’s a real need for large, open, and diverse datasets to catalyze innovation.

This is just the beginning. Our goal is to build a dataset with 1,000 words in 1,000 different languages.
“Speech technology can empower billions of people across the planet, but there’s a real need for large, open, and diverse datasets to catalyze innovation,” said David Kanter, MLCommons co-founder and executive director and co-author of the study. “The Multilingual Spoken Words Corpus offers a tremendous breadth of languages. I’m excited for these datasets to improve everyday experiences like voice-enabled consumer devices and speech recognition.”
To build the dataset, the team used recordings from Mozilla Common Voice, a massive global project that collects donated voice recordings in a wide variety of spoken languages, including languages with a smaller population of speakers. Through the Common Voice website, volunteer speakers are given a sentence to read aloud in their chosen language. Another group of volunteers listens to the recorded sentences and verifies its accuracy.
The researchers applied a machine learning algorithm that can recognize and pull keywords from recorded sentences in Common Voice.
For example, one sentence prompt from Common Voice reads: “He played college football at Texas and Rice.”
First, the algorithm uses a common machine learning technique called forced alignment — specifically a tool called the Montreal Forced Aligner — to match the spoken words with text. Then the algorithm filters and extracts words with three or more characters (or two characters in Chinese). From the above sentence, the algorithm would pull “played” “college” “football” “Texas” “and” and “Rice.” To add the word to the dataset, the algorithm needs to find at least five examples of the word, which ensures all words have multiple pronunciation examples.
The algorithm also optimizes for gender balance and minimal speaker overlap between the samples used for training and evaluating keyword spotting models.
“Our goal was to create a large corpus of very common words,” said Mazumder, who is the first author of the study. “So, if you want to train a model for smart lights in Tamil, for example, you would probably use our dataset to pull the keywords “light”, “on”, “off” and “dim” and be able to find enough examples to train the model.”
“We want to build the voice equivalent of Google search for text and images,” said Reddi. “A dataset search engine that can go and find what you want, when you want it on the fly, rather than rely on static datasets that are costly and tedious to create.”
When the researchers compared the accuracy of models trained on their dataset against models trained on a Google dataset that was manually constructed by carefully sourcing individual and specific words, the team found only a small accuracy gap between the two.
For most of the 50 languages, the Multilingual Spoken Words Corpus is the first available keyword dataset that is free for commercial use. For several languages, such as Mongolian, Sakha, and Hakha Chin, it is the first keyword spotting dataset in the language.
“This is just the beginning,” said Reddi. “Our goal is to build a dataset with 1,000 words in 1,000 different languages.”
“Whether it’s on Common Voice or YouTube, Wikicommons, archive.org, or any other creative commons site, there is so much more data out there that we can scrape to build this dataset and expand the diversity of the languages for voice-based interfaces,” said Mazumder. “Voice interfaces can make technology more accessible for users with visual or physical impairments, or for lower literacy users. We hope free datasets like ours will help assistive technology developers to meet these needs.”
The corpus is available on MLCommons, a not-for-profit, open engineering consortium dedicated to improving machine learning for everyone. Reddi is Vice President and a board member of MLCommons .
The paper was co-authored by Sharad Chitlangia, Colby Banbury, Yiping Kang, Juan Manuel Ciro, Keith Achorn, Daniel Galvez, Mark Sabini, Peter Mattson, Greg Diamos, Pete Warden and Josh Meyer.
The research was sponsored in part by the Semiconductor Research Corporation (SRC) and Google.
Topics: AI / Machine Learning , Computer Science
Cutting-edge science delivered direct to your inbox.
Join the Harvard SEAS mailing list.
Scientist Profiles

Vijay Janapa Reddi
John L. Loeb Associate Professor of Engineering and Applied Sciences
Press Contact
Leah Burrows | 617-496-1351 | [email protected]
Related News

Alumni profile: Jacomo Corbo, Ph.D. '08
Racing into the future of machine learning
AI / Machine Learning , Computer Science

Ph.D. student Monteiro Paes named Apple Scholar in AI/ML
Monteiro Paes studies fairness and arbitrariness in machine learning models
AI / Machine Learning , Applied Mathematics , Awards , Graduate Student Profile

A new phase for Harvard Quantum Computing Club
SEAS students place second at MIT quantum hackathon
Computer Science , Quantum Engineering , Undergraduate Student Profile
- Shop all deals
- Free phones
- Smartphones
- Fios Home Internet
- Bring your own device
- Accessories
- Refer a Friend
- Verizon Visa® Card
- Certified pre-owned phones
- Apple iPhone 15 Pro
- Apple iPhone 15
- Samsung Galaxy S24 Ultra
- Google Pixel 8 Pro
- Other phones
- Trade in your device
- Tablets & laptops
- Certified pre-owned watches
- Jetpacks & hotspots
- Shop all accessories
- Phone cases
- Screen protectors
- Tablet accessories
- Chargers & cables
- Phone attachments
- MagSafe compatible
- Verizon accessories
- Shop all watch accessories
- Smart watches
- Shop all plans
- International services
- Connected devices
- Discounts overview
- Mobile + Home
- First responders
- Verizon Forward
- Connected car plans
- Shop all home solutions
- 5G Home Internet
- LTE Home Internet
- Accessories overview
- Cables & connectors
- Networking & Wi-Fi
- TV accessories
- Phone equipment
- 5G Home accessories
- Prepaid overview
- Phone plans
- International plans
- Basic phones
- Mobile hotspots & routers
- Affordable Connectivity Program
- Why Verizon Prepaid
- Disney+, Hulu, ESPN+
- Apple Arcade
- Google Play Pass
- Apple Music
- Xbox All Access
- Services & perks overview
- Entertainment
- Protection & security
- Digital family
- Financial services
- 5G overview
- Coverage map
- Innovation Labs
- Global coverage
- Devices & plans
- Device protection
- Verizon Cloud
- Health discounts
- Responsibility
- Support overview
- Mobile support overview
- Billing & payments
- Account management
- Device support & setup
- Services & apps
- International trip planner
- Order status
- Community Forums
- Download My Verizon App
- Home support overview
- Billing & account management
- Fios Internet
- Back to Menu
- Sign in to My Account
- Prepaid instant pay
- Business Log in
Choose your cart
- Mobile solutions
- Home solutions
A guide to voice-activated technology
Voice recognition technology is a software program or hardware device that has the ability to decode the human voice. Sometimes referred to as voice-activated or speech recognition software, this technology has become more and more popular in recent years among everyday consumers. Many people incorporate these devices into multiple facets of their homes to perform commands, find information, or make recordings more conveniently. In fact, the size of the voice commerce market is expected to increase significantly over the next several years, growing from $2 billion in 2018 to $40 billion by 2022 .
With voice-activated technology becoming more pervasive and accessible, it’s important for you to understand more about it before inviting it into your life, home, or workplace. As with any piece of new technology, you should know how it works and the various ways in which you can use it, as well as some of its disadvantages and the various concerns and risks that may come from using it. After all, voice-activated technology is an exciting new development that is changing the way people interact with and use technology, and it’s likely only going to become increasingly integrated into consumers’ daily lives.
How does voice recognition work?
Although using voice recognition technology is as simple as uttering a few words, the way it works is actually quite complex . First, speech recognition software filters through the sounds you speak and translates them into a format it can “read.” Then, it analyzes that “translation” for meaning and uses that information — along with its algorithm and previous inputs — to guess what you said.

Popular Articles

If you are the only person using a piece of voice-activated technology, its ability to understand you and your meaning will improve over time, becoming more and more accurate. Things get far more complex when accounting for other users, different languages and dialects, and the other factors that can affect human speech. Even common changes, such as background noise or vocal inflections, can affect how voice-activated technology understands a speaker.
Many types of voice-activated technology actually “learn” language in the same way that human children do: language input. The Linguistic Society of America claims that “children acquire language quickly, easily, and without effort or formal teaching. It happens automatically [...] Children who are never spoken to will not acquire language.” In other words, children learn based on how other people use language with and around them. Similarly, voice recognition systems must receive language input and be interacted with in order to learn how to recognize patterns and make connections in human language. Without this input and training, many voice recognition systems likely would not be able to function as well or as accurately as they currently do.
Despite these difficulties, various voice recognition systems continue to improve and advance in their ability to understand human speakers. For example, at the end of 2016, Microsoft’s speech recognition technology reached a level of understanding similar to that of humans themselves, and Google’s own voice recognition software attained a level of 95% recognition accuracy not long after. As researchers continue to teach, train, and develop voice recognition technology, it could become even more accurate in the future.
Types of recognition systems
There are a variety of different kinds of systems that fall under the larger umbrella of voice-activated technology. Other common types of recognition systems include:
- Speaker dependent systems: Requires training before use and is thus dependent on a speaker to be functional. Users may have to read a series of words, phrases, and sentences to help train the system.
- Speaker independent systems: Does not require training before use and is already capable of understanding most user’s voices. Many popular voice assistants use speaker-independent systems.
- Discrete speech recognition: Requires users to speak words one-at-a-time or with pauses between each word, as the system can only understand words and their meanings individually.
- Continuous speech recognition: Allows users to speak at a normal rate when interacting with the system.
- Natural language: Can understand a user’s words and their meaning, and can also respond to them, provide answers to questions, complete commands, or deliver requested information.
How is voice activation and recognition used?
Though it has only seen widespread use in the last several years, voice activation and recognition technology already have myriad applications in different facets of everyday life. As a matter of fact, it’s become so popular so quickly that you’ve probably used or encountered voice-activated technology already. Some popular uses for voice-activated technology include:
- Cars: Many cars now have voice-activated technology integrated directly into the vehicle itself. This includes things like smart car speakers and connected car hotspots to allow for easier and safe hands-free driving.
- Home appliances: Many appliances, devices, and systems are now connected to the internet and to each other to make it easier than ever before for people to control, protect, and enjoy their homes. Many of these different smart home devices , such as thermostats and security systems, also make use of voice activation for that same purpose.
- Laptops & tablets: It’s now common for laptops and tablets to have voice recognition built into the device so you can embrace a hands-free experience when you need or want to.
- Personal digital assistants: Personal digital assistants are among the most popular uses of voice-activated technology. Many — such as Google’s Hey Google and Apple’s Siri — are integrated directly into popular smartphones so you can use them regardless of where you are or what you’re doing.
- Wearable technology: Similarly, wearable technology like fitness trackers and smartwatches also allows you to use voice recognition whenever you have your device on your person. This can make it easier to use these devices altogether since they tend to have small screens and buttons.

Advantages and disadvantages of voice activation.
Regardless of how you use it, there are both advantages and disadvantages that come from using voice activation technology. Some of the biggest advantages include:
- Accessibility: Voice activation allows a greater number of people to access digital technology, connected devices, and the internet more easily. It improves accessibility for people with disabilities, especially for individuals who have impaired vision or motor functions.
- Connection: Voice activation can easily work with other connected technologies and devices in your home, such as smart appliances and speakers. This connection makes it that much simpler and faster to accomplish different tasks in your home.
- Convenience: Using voice activation can be significantly more convenient than typing something out on a keyboard or smartphone or manually completing a task. Of the Americans who use digital assistants, 55% claim that being able to use their devices hands-free is a major reason they use voice activation at all. When using voice-activated technology, you’re able to use your mind and hands to do something else.
- Personalization: Voice-activated technology creates a more personalized digital experience for users. This can include remembering information from previous interactions, offering helpful reminders, and distinguishing between multiple users from voice alone. In other words, the more you use voice activation, the easier and better it is for you to use.
On the other hand, there are also disadvantages and barriers to using voice-activated technology that can affect consumers’ ability to engage with it. Some of the biggest concerns about it include:
- Cost: Different devices that make use of voice activation, including speakers and smart appliances, can be costly for some people. They may only be able to afford one piece of voice-activated technology, such as a smartphone, and miss out on the benefits of connecting and using multiple devices.
- Inaccuracy: Although the accuracy of voice-activated technology has increased dramatically in the last several years, it still isn’t perfect. You’ll likely still encounter some minor inaccuracies or errors when using voice activation.
- Limitations: Voice-activated technology is currently capable of only doing so much. There are limitations to how it can be used, and it will take more time to discover more applications and uses of voice recognition.
- Multi-tasking: You may think that using voice recognition helps you multitask, but it may actually just be disruptive. For example, a growing body of research indicates that using voice assistant technology can still be a distraction for drivers , especially when it doesn’t work accurately.
Depending on how you engage with voice-activated technology and what you use it for, though, the benefits may easily outweigh the drawbacks (or vice versa). It all depends on what type of experience you want to have with voice recognition.
Is voice control technology secure?
Just as with virtually any piece of new technology such as mobile pay and even cell phones in and of themselves, there are concerns about the security of voice recognition technology. It’s true that you do take some risks when using any type of voice-activated technology. Common threats include hackers being able to access your private information, duplicating or copying your voice to make commands or purchases, or leveraging the voice recognition software to control other connected devices in your home. These are very real privacy and security threats that can compromise sensitive information, your finances, and your home.
However, threat researcher Candid Wueest notes that “these devices do not present more risk than a smartphone or laptop.” All of the main concerns that stem from voice-activated technology are also a risk when using other connected devices. And as with other types of technology, there will always be hackers and fraudsters looking to take advantage of any potential vulnerabilities for their own benefit. Further, as voice-activated technology becomes more sophisticated and integrated into day-to-day life, it will likely become more secure and safe for consumers to use.
- Home Internet & TV
- Return policy
- Accessibility
- Check network status
- Verizon Innovative Learning
- Consumer info
- Apple iPhone 15 Pro Max
- Apple iPhone 15 Plus
- Apple AirPods Max
- Apple Watch Series 9
- Elizabeth James
- Terms & Conditions
- Device Payment Terms & Conditions
- Report a security vulnerability
- Mobile customer agreement
- Announcements
- Radio frequency emissions
- Taxes & surcharges
- Legal notices
- facebook-official
- Privacy Policy
- California Privacy Notice
- Health Privacy Notice
- Open Internet
- Terms & Conditions
- About Our Ads
Book a Demo

The Impact of Speech Recognition Technology on the Workplace
With over 60% of employees working remotely, it's now more important than ever for employers to empower their workforce with the right tools. Many companies are looking to speech recognition technology to achieve this.

Table of Contents
Speech recognition technology is changing the way we do business in many industries. We're at a point where speech recognition is becoming integrated into everyday life, including the workplace.
With over 60% of employees working remotely , it's now more important than ever for employers to empower their workforce with the right tools. Many companies are looking to speech recognition technology to achieve this.
Even before remote work increased because of the pandemic, IT departments were readying to mainstream voice recognition in the workplace.
According to a Gartner report , the adoption of chatbots and virtual personal assistants by businesses and increasing consumer use of voice-enabled devices has driven the integration of speech-to-text applications at work.
Evolution of Speech Technology in the Workplace
Speech recognition technology has come a long way in relatively little time. Voice commands are now being used in various applications but one of the most significant changes have come in workplace software.
Speech-to-text dictation is the most apparent applicable form of speech recognition technology for work. Using voice to write has increased work productivity tenfold rather than typing long-form documents or dictating and later transcribing articles.
The Early Days of Speech Dictation Software
In the early 1990s, Dragon Systems Inc. provided the first commercially available speech-to-text software. However, it was costly, and it required a great deal of training on the user's part. Also, the software was only compatible with Microsoft programs.
The early version of the software, called Dragon Dictate, was clunky and required users to enunciate words one at a time, with a pause in between. Later versions of the software, now called Dragon NaturallySpeaking, led to continuous speech-to-text dictation. However, the software is still restricted to Microsoft compatible applications and PC-friendly browsers.
By the mid-2000s, people could go to their local big box store or even download software and get a speech recognition program for a couple of hundred dollars. But even then, speech recognition technology in the workplace still required at least 30 minutes of training.
Today, you can easily get free speech recognition software online or buy it for less than $100. Some companies like Otter offer subscription for a small monthly fee, and it requires no training at all.
Google and Microsoft Take Speech Recognition to the Next Level
Although Google introduced Voice Search in 2008 , it wasn’t until 2015 that it offered speech-to-text (STT) for Google Docs.
Developers now use its cloud-based API speech technology to create various business and consumer applications.
One such business is Voximplant, which uses Google’s Cloud SST API to build speech recognition tools for clients like Hyundai, Burger King, and Sberbank, one of Europe’s largest banks.
While Microsoft had already offered speech recognition in previous products such as Microsoft Office as early as 2002, it required separate installation of an individual speech recognition component.
In 2009, Microsoft released Windows Speech Recognition (WSR), developed for Windows Vista. The speech recognition software enabled users to use voice to control their desktop user interface and dictate text for email and electronic documents. Office users could also use voice control to navigate websites, operate their mouse cursor, and perform keyboard shortcuts.
Microsoft also offers add-on speech control programs that allow users to control Excel and other apps with their voice rather than using a keyboard or mouse. These tools are used by clicking the microphone icon on the toolbar or using a "wake word" such as "Excel."
Interestingly, Google doesn’t offer voice commands with its spreadsheets app. However, some browser extensions enable speech-to-text controls for Google Spreadsheets.
Besides the big tech companies’ offering, many smart devices have integrated speech recognition capabilities that employees can use with most dictation, navigation, search, and other apps.
Speech technology for work has also grown to include audio and video conferencing platforms such as Zoom, Google Meet, GotoMeeting, etc.

Benefits of Speech Recognition Technology in the Workplace
New technology can often have a positive impact on employees' working lives. And speech recognition is no exception. So, how can speech recognition technology help transform the workplace?
Improved Productivity
The primary benefit of speech recognition software is improved productivity. Users can dictate documents, email responses, and other text without manually inputting any information into a machine.
Using speech-to-text technology removes one barrier between a user's thoughts and their digital output — which can streamline business processes, save time, and ultimately increase productivity.
The reduction of handling paperwork by using speech technology alone saves an astounding amount of time. On average, employees spend 60% of their time working with documents. In addition, looking for misplaced papers takes up 30% to 40% of an employee's time.
With the aid of speech technology, employees can be more productive in their roles and focus on higher-value tasks. It means your business will receive important information faster, improving efficiency across the organization.
Enhanced Mobility
While the pandemic substantially increased the number of employees working remotely, traveling for meetings and other purposes has long been the norm for many.
Voice technology advancements have eliminated meeting in-person with prospective clients or employees.
These developments give remote workers complete flexibility over where they work and increase further productivity by allowing them to complete work wherever.
Less risk of injury
Speech recognition technology can relieve pain associated with keyboarding or mouse usage for those who suffer from repetitive stress injuries, such as carpal tunnel syndrome. The technology also provides an alternative for those who have difficulty using a keyboard or mouse because of physical or cognitive limitations.
Fields Where Voice Recognition is Making Strides
The medical setting may be one of the most prevalent places where speech recognition technology has significantly improved workflow and performance.
For example, the speed at which doctors can dictate their notes has significantly increased from 30 words per minute when using a keyboard to 150 words per minute when using speech recognition software. As a result, doctors and nurses can optimize operations and spend more time with patients instead of handwriting or typing medical notes, much of which is for electronic health records (EHR) for r egulatory and billing information .
Healthcare companies such as Nebraska Health and Baptist Health use Nuance’s Dragon Medical One dictation software to ease operations and avoid burnout from “burdensome documentation processes.”
For telemedicine, studies have found face-to-face communication is lost during emailing and instant messaging, so voice interaction over the Internet may help offset this loss.
Content Creators
Speech recognition technology has made writing much easier and faster. It typically takes the average person to type 38 to 40 words per minute, while dictation results in 125 to 150 words per minute. Using voice recognition to take notes and dictate stories is a huge timesaver.
Journalists, in particular, spend six hours a week transcribing audio. AI-driven speech-to-text software that transcribes notes frees up a great deal of time for reporters to conduct in-depth interviews and write articles.
Social media marketers, bloggers, and other digital content creators benefit from speech recognition software that enables them to search for information quickly, take voice notes, and write long-form content via dictation.
Legal Profession
Many tasks involving legal documents also lend themselves well to speech recognition software.
In addition to drafting letters or contracts by voice taking notes during important client meetings, are quickly done with AI-driven software that transcribes notes into bullet-pointed documents and highlights action-oriented bullet points.
An example is the AI-driven note-taking platform Dubber (previously known as Notiv). The platform automatically records and transcribes meetings via phone or video conferencing into actions and summaries.
The benefits of speech recognition software are not lost on the legal profession. In a survey by Censuswide, 82% of legal firms polled in the U.K. said they were planning to invest in speech recognition technology. The same study found that legal professionals who did not use speech recognition technology spent between two to four hours per day typing.
Speech Recognition Limitations
While speech recognition technology has made significant advances in the past decade, its use still has many limitations. For example, background noise, different languages and accents, and other issues create barriers to accurate speech recognition.
As Stephanie Lahr, CIO and CMIO of Monument Health, told Healthcare IT News , while speech recognition can improve the patient-doctor experience by freeing up time, clinical exchanges are complex. Most leading speech technology software cannot isolate clinical terminology from the general chitchat between doctor and patient.
Security and privacy concerns, especially in the medical and legal professions, are also of great concern. For example, data stored in the cloud can expose sensitive information to hackers. Also, voice identity fraud is a significant issue, as seen in a recent bank heist.
Device makers that integrate speech recognition must ensure the software offers high accuracy, on-edge technology, and voice identification features to provide secure voice control to advance its use in the workplace.
In Conclusion
The workplace of tomorrow is using speech recognition technology that leads to increased productivity and enhances efficient communication. Businesses are seeing the benefits of this software and increasing its use, which will probably lead to further innovation.
However, the safety and security of those working with speech recognition are paramount. Still, the technology can help to revolutionize the workplace by allowing employees to communicate and conduct business from virtually any location.
The future of business is transforming, and speech recognition is leading the way.
Enjoyed this read?
Stay up to date with the latest video business news, strategies, and insights sent straight to your inbox!
Get the Latest Updates

Download ASR/Wake Word Study
Related articles.

Voice AI Technology: Streamlining Fleet Management and Logistics
.png "examples of speech recognition technology")
Kardome and Panasonic Automotive Join Forces to Enhance In-Car Voice User Experience

Kardome Mobility Empowers Automotive OEMs to Create Next-Gen Voice Interfaces with AI-Powered Technology

Introducing Kardome Mobility: Revolutionizing In-Car Voice Interactions
Give your users a voice.
Kardome’s VUI technology can integrate with any voice-enabled platform or smart device.
Multi-speaker Isolation
Eliminate Background Noise
Accurate Speech Recognition

[email protected]
Kardome Technology LTD, All Rights Reserved, 2022.
July 5, 2020
Speech Recognition Tech Is Yet Another Example of Bias
Siri, Alexa and other programs sometimes have trouble with the accents and speech patterns of people from many underrepresented groups
By Claudia Lopez Lloreda

Getty Images
“Clow-dia,” I say once. Twice. A third time. Defeated, I say the Americanized version of my name: “Claw-dee-ah.” Finally, Siri recognizes it.
Having to adapt our way of speaking to interact with speech recognition technologies is a familiar experience for people whose first language is not English or who do not have conventionally American-sounding names. I have even stopped using Siri because of it.
Implementation of speech recognition technology in the last few decades has unveiled a very problematic issue ingrained in them: racial bias. One recent study , published in PNAS, showed that speech recognition programs are biased against Black speakers. On average, all five programs from leading technology companies like Apple and Microsoft showed significant race disparities; they were twice as likely to incorrectly transcribe audio from Black speakers as opposed to white speakers.
On supporting science journalism
If you're enjoying this article, consider supporting our award-winning journalism by subscribing . By purchasing a subscription you are helping to ensure the future of impactful stories about the discoveries and ideas shaping our world today.
In normal conversations with other people, we might choose to code-switch, alternating between languages, accents or ways of speaking, depending on one’s audience. But with automated speech recognition programs, there is no code-switching—either you assimilate, or you are not understood. This effectively censors voices that are not part of the “standard” languages or accents used to create these technologies.
“I don't get to negotiate with these devices unless I adapt my language patterns,” says Halcyon Lawrence , an assistant professor of technical communication and information design at Towson University who was not part of the study. “That is problematic.” Specifically, the problem goes beyond just having to change your way of speaking: it means having to adapt your identity and assimilate.
For Lawrence, who has a Trinidad and Tobagonian accent, and others part of our identity comes from speaking a particular language, having an accent, or using a set of speech forms such as African American Vernacular English (AAVE). For me as a Puerto Rican, saying my name in Spanish, rather than trying to translate the sounds to make it understandable for North American listeners, means staying true to my roots. Having to change such an integral part of an identity to be able to be recognized is inherently cruel, Lawrence adds: “The same way one wouldn’t expect that I would take the color of my skin off.”
The inability to be understood by speech recognition programs impacts other marginalized communities. Allison Koenecke, a computational graduate student and first author of the study, points out a uniquely vulnerable community: people with disabilities who rely on voice recognition and speech-to-text tools. “This is only going to work for one subset of the population who is able to be understood by [automated speech recognition] systems,” she says. For someone who has a disability and is dependent on these technologies, being misunderstood could have serious consequences.
There are probably many culprits for these disparities, but Koenecke points to the most likely: training data. Across the board, the “standard” data used to train speech recognition technologies are predominantly white. By using narrow speech corpora both in the words that are used and how they are said, systems exclude accents and other ways of speaking that have unique linguistic features, such as AAVE. In fact, the study found that with increased use of AAVE, the likelihood of misunderstanding also increased. Specifically, the disparities found in the study were mainly due to the way words were said, since even when speakers said identical phrases, Black speakers were again twice as likely to be misunderstood compared to white speakers.
Additionally, accent and language bias lives in the humans that create these technologies. For example, research shows that the presence of an accent affects whether jurors find people guilty and whether patients find their doctors competent . Recognizing these biases would be an important way to avoid implementing them in technologies.
Safiya Noble , associate professor of information studies at the University of California, Los Angeles, admits that language is tricky to incorporate into a technology. “Language is contextual,” says Noble, who was not involved in the study. “Certain words mean certain things when certain bodies say them, and these [speech] recognition systems really don't account for a lot of that.” But that doesn’t mean that companies shouldn’t strive to decrease bias and disparities in their technologies. However, to try to do this, they need to appreciate the complexities of human language. For this reason, solutions can come not only from the field of technology but also from the fields of humanities, linguistics, and social sciences.
Lawrence argues that developers have to be aware of the implications of the technologies they create, and that people have to question what purpose and who these technologies serve. The only way to do this is to have humanists and social scientists at the table and in dialogue with technologists to ask the important questions of if these recognition technologies could be co-opted as weapons against marginalized communities, similar to certain harmful developments with facial recognition technologies.
From the tech side, feeding more diverse training data into the programs could close this gap, says Koenecke. “I think at least increasing the share of non-standard English audio samples in the training data set will take us towards closing the race gap,” she adds. They should also test their products more widely and have more diverse work forces so people from different backgrounds and perspectives can directly influence the design of speech technologies, says Noble.
But both sides agree that tech companies must be held accountable and should aim to change. Koenecke suggests that automated speech recognition companies use their study as a preliminary benchmark and continue using this to assess their systems over time.
With these strategies, tech companies and developers may be able to make speech recognition technologies more inclusive. But if they continue to be disconnected from the complexities of human language and society without recognizing their own biases, there will continue to be gaps. In the meantime, many of us will continue to struggle between identity and being understood when interacting with Alexa, Cortana or Siri. But Lawrence chooses identity every time: “I’m not switching, I'm not doing it.”
More From Forbes
Is openai voice engine adding value or creating more societal risks.
- Share to Facebook
- Share to Twitter
- Share to Linkedin
AI speaks letters, text-to-speech or TTS, text-to-voice, speech synthesis applications, generative ... [+] Artificial Intelligence, futuristic technology in language and communication.
Innovative futuristic technology continues to burst from OpenAI research labs. Voice Engine, just announced, generates natural speech that resembles the original speaker in a fifteen second audio capture. The tool can recreate voices in english, Spanish, French or Chinese.
Although the Voice Engine was in their labs in 2022, OpenAI stated they were being cautious in their release and want to start a dialogue on responsible deployment of synthetic voices.
Voice Engine can help advance a number of use cases. One example is providing reading assistance to non-readers and children through natural sounding voices to generate pre-scripted voice over content automatically. This allows for more content development and more rapid deployment.
A second example is helping patients recover their voices when suffering from a sudden loss of speech or degenerative speech conditions. Brown University has been piloting Voice Engine to help patients with oncologic or neurologic issued for treating speech impairments.
The partners testing Voice Engine have agreed to OpenAI usage policies , which prohibit the impersonation of another individual or organization without consent or legal right.
In addition, OpenAI partners require explicit and informed consent from the original speaker and the company does not allow developers to build ways for individual users to create their own voices. The partners must also also disclose to their audience that the voices they're hearing are AI-generated. Perhaps the most important point is OpenAI is implementing watermarking to trace the origin of any audio generated by Voice Engine, and retain proactive monitoring of how Voice Engine is being used.
Google Suddenly Reveals Surprise Android Update That Beats iPhone
This popular google app will stop working in 3 days how to migrate your data, ufc fight night results fighter suffers rare self inflicted ko loss.
Although not officially released Voice Engine has serious risks. Some of the risks most often highlighted are to families and small businesses that are targeted with fraudulent extortion scams. False election and marketing campaigns is a boon to bad actors with access to Voice Engine technology. In addition, creative professionals, such as voice artists, could potentially have their voices used in ways that could jeopardize an artist's reputation and ability to earn an income.
The company also made recommendations to look ahead on safety approaches for voice technologies:
- phasing out voice based authentication as a security measure for accessing bank accounts and other sensitive information,
- exploring policies to protect the use of individuals' voices in AI,
- educating the public in understanding the capabilities and limitations of AI technologies, including the possibility of deceptive AI content, and
- accelerating the development and adoption of techniques for tracking the origin of audiovisual content, so it's always clear when you're interacting with a real person or with an AI consent or legal right.
OpenAI is wisely proceeding with more caution and safety positioning with Voice Engine and is withholding a formal public release over safety concerns, citing the election year as a factor.
Where is OpenAI heading with Voice Engine?
An obvious answer is direct competition with Amazon’s Alexa, as the company filed a trademark application on March 19, further signalling its market direction. No matter where OpenAI Voice Engine is heading, the reality is that voice cloning is here to stay.
Update on Voice Cloning FCC Legislation
The Federal Communications Commission (FCC) announced in early February, 2024 that calls made with voices generated with the help of Artificial Intelligence (AI) will be considered “artificial” under the Telephone Consumer Protection Act (TCPA).
This announcement makes robocalls that implement voice cloning technology and target consumers illegal.

- Editorial Standards
- Reprints & Permissions
IMAGES
VIDEO
COMMENTS
Speech recognition, also known as automatic speech recognition (ASR), computer speech recognition or speech-to-text, is a capability that enables a program to process human speech into a written format. While speech recognition is commonly confused with voice recognition, speech recognition focuses on the translation of speech from a verbal ...
The technology within speech recognition software goes beyond what most of us know. Speech-to-text, such as Speechmatics' Autonomous Speech Recognition (ASR), stretches its influence across society. This article will dive into seven examples of speech recognition and areas where speech-to-text technology makes a valuable difference.
Interactive Voice Response (IVR): It is one of the oldest speech recognition applications and allows customers to reach the right agents or resolve their problems via voice commands. Analytics: Transcription of thousands of phone calls between customers and agents helps identify common call patterns and issues. 5.
For example, speech recognition could help industries such as finance, telecommunications, and unified communications as a service (UCaaS) to improve customer experience, operational efficiency, and return on investment (ROI). ... ASR models makes it difficult for developers to take advantage of the best speech recognition technology. Limited ...
Simply put, speech recognition technology (otherwise known as speech-to-text or automatic speech recognition) is software that can convert the sound waves of spoken human language into readable text. These programs match sounds to word sequences through a series of steps that include: Pre-processing: may consist of efforts to improve the audio ...
Speech recognition, also known as automatic speech recognition (ASR), enables seamless communication between humans and machines. This technology empowers organizations to transform human speech into written text. Speech recognition technology can revolutionize many business applications, including customer service, healthcare, finance and sales.
Automatic Speech Recognition is a technology allowing users to enter data into information systems by speaking instead of punching numbers into a keypad. ... These are some of the most well-known examples of automatic speech recognition (ASR). This type of app starts with a clip of spoken audio in a specific language and converts the words ...
Speech recognition is an interdisciplinary subfield of computer science and computational linguistics that develops methodologies and technologies that enable the recognition and translation of spoken language into text by computers. It is also known as automatic speech recognition (ASR), computer speech recognition or speech to text (STT).It incorporates knowledge and research in the computer ...
Speech AI uses automatic speech recognition and text-to-speech technology to provide a voice interface for conversational applications. A typical speech AI pipeline consists of data preprocessing stages, neural network model training, and post-processing. In this section, I discuss these stages in both ASR and TTS pipelines.
Speech recognition technology has ushered in a new era of interaction with devices, transforming the way we communicate with them. It allows machines to understand and interpret human speech, enabling a range of applications that were once thought impossible. Speech recognition leverages machine learning algorithms to recognize speech patterns ...
A Complete Guide to Speech Recognition Technology. Here's everything you need to know about speech recognition technology. History, how it works, how it's used today, what the future holds, and what it all means for you. Back in 2008, many of us were captivated by Tony Stark's virtual butler, J.A.R.V.I.S, in Marvel's Iron Man movie.
voice portal (vortal): A voice portal (sometimes called a vortal ) is a Web portal that can be accessed entirely by voice. Ideally, any type of information, service, or transaction found on the Internet could be accessed through a voice portal.
Artificial intelligence (AI)-based speech recognition is a software technology fueled by cutting-edge solutions like Natural Language Processing (NLP) and Machine Learning (ML). NLP, an AI system that analyses natural human speech, is sometimes referred to as human language processing. The vocal data is first transformed into a digital format ...
Speech recognition technology is a type of artificial intelligence that involves understanding what a person says. It usually does this by looking at the words being said and then comparing them to a predefined list of acceptable phrases. Speech recognition software has an extensive list of words and phrases programmed into it, including things ...
Automatic Speech Recognition is a fairly advanced technology that is extremely hard to design and develop. There are thousands of languages worldwide with various dialects and accents, so it is hard to develop software that can understand it all. ASR uses concepts of natural language processing and machine learning for its development.
Communications of the ACM (2014). This article provides an in-depth and scholarly look at the evolution of speech recognition technology. The Past, Present and Future of Speech Recognition Technology by Clark Boyd at The Startup. This blog post presents an overview of speech recognition technology, with some thoughts about the future.
Introduction to Speech Recognition in Natural Language Processing Voice recognition is an increasingly important technology in natural language processing (NLP). It is a form of artificial intelligence that enables machines to understand and interpret spoken language. Speech recognition has been around since the 1950s and has seen rapid advances over the past few decades.
speech recognition, the ability of devices to respond to spoken commands. Speech recognition enables hands-free control of various devices and equipment (a particular boon to many disabled persons), provides input to automatic translation, and creates print-ready dictation. Among the earliest applications for speech recognition were automated ...
"Speech technology can empower billions of people across the planet, but there's a real need for large, open, and diverse datasets to catalyze innovation," said David Kanter, MLCommons co-founder and executive director and co-author of the study. "The Multilingual Spoken Words Corpus offers a tremendous breadth of languages.
For example, at the end of 2016, Microsoft's speech recognition technology reached a level of understanding similar to that of humans themselves, and Google's own voice recognition software attained a level of 95% recognition accuracy not long after. As researchers continue to teach, train, and develop voice recognition technology, it could ...
Photo by Andrew DesLauriers on Unsplash TL;DR: This post focuses on the advancements in Automatic Speech Recognition (ASR) technology and its impact on various domains. ASR has become prevalent in multiple industries, with improved accuracy driven by scaling model size and constructing larger labeled and unlabelled training datasets.
Speech recognition technology has made writing much easier and faster. It typically takes the average person to type 38 to 40 words per minute, while dictation results in 125 to 150 words per minute. Using voice recognition to take notes and dictate stories is a huge timesaver.
Implementation of speech recognition technology in the last few decades has unveiled a very problematic issue ingrained in them: racial bias. One recent study, published in PNAS, showed that ...
Innovative futuristic technology continues to burst from OpenAI research labs. Voice Engine, just announced, generates natural speech that resembles the original speaker in a fifteen second audio ...